Kimi这波什么情况?马斯克点赞的「注意力残差」,把Transformer十年地基给拆了
震惊了,要是你关注AI圈,昨天肯定被一张图刷屏了——马斯克亲自下场,给中国公司Kimi的新研究点赞,说了句“Impressive work from Kimi”(Kimi这活儿干得漂亮)。
旁边还有前特斯拉AI总监、OpenAI联创Karpathy在那“锐评”:“看来我们还没把‘Attention is All You Need’这句话吃透啊” 。
什么概念?这就好比马斯克路过工地,看见Kimi在那拆地基,不仅没骂人,还回头竖了个大拇指:“拆得不错,继续拆。”
Kimi到底拆了啥?能把硅谷半个AI圈都炸出来?接下来我将用大白话为大家进行拆解:
kimi论文【中文版】:Attention Residuals中文报告
kimi论文【英文版】Attention Residuals
开源地址:https://github.com/MoonshotAI/Attention-Residuals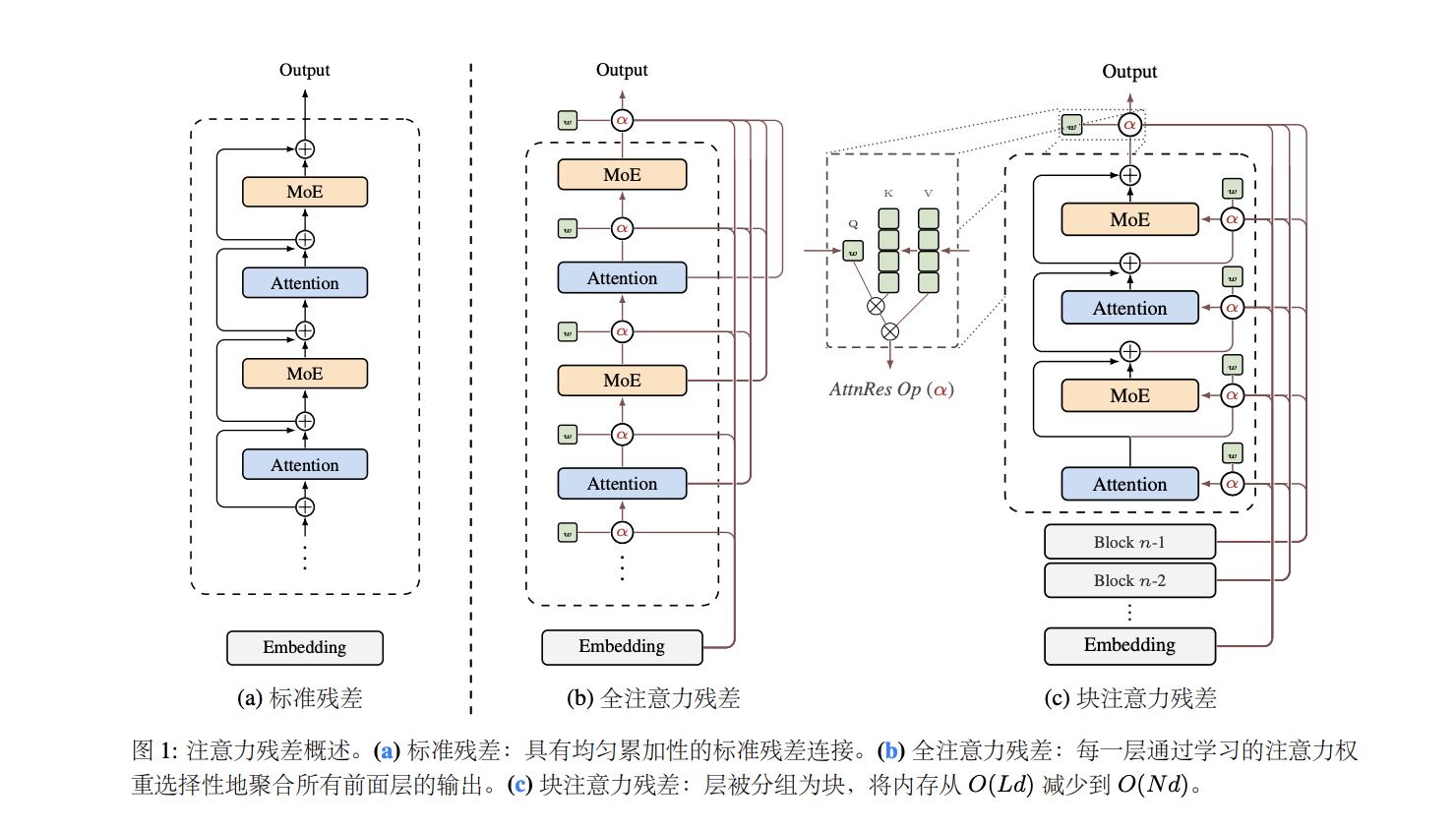
一、他们把那行用了十年的“祖传代码”给改了
要理解这事儿多牛,得先知道什么叫“残差连接”。
2015年,大神何恺明写了一行代码,大概意思就是:
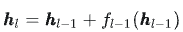
简单说就是:每次处理完信息,都强行把原始信息再加回来一次,防止信息在传递过程中丢失。
这行代码有多牛?过去十年,全世界所有大模型——GPT、Claude、Gemini,包括咱们的DeepSeek,都在用这行代码,没人敢动。它就像神经网络里的“祖传代码”,虽然没人说得清它是不是最优解,但“祖宗之法不可变”嘛。
但Kimi这次干了件事:他们把这行代码换了。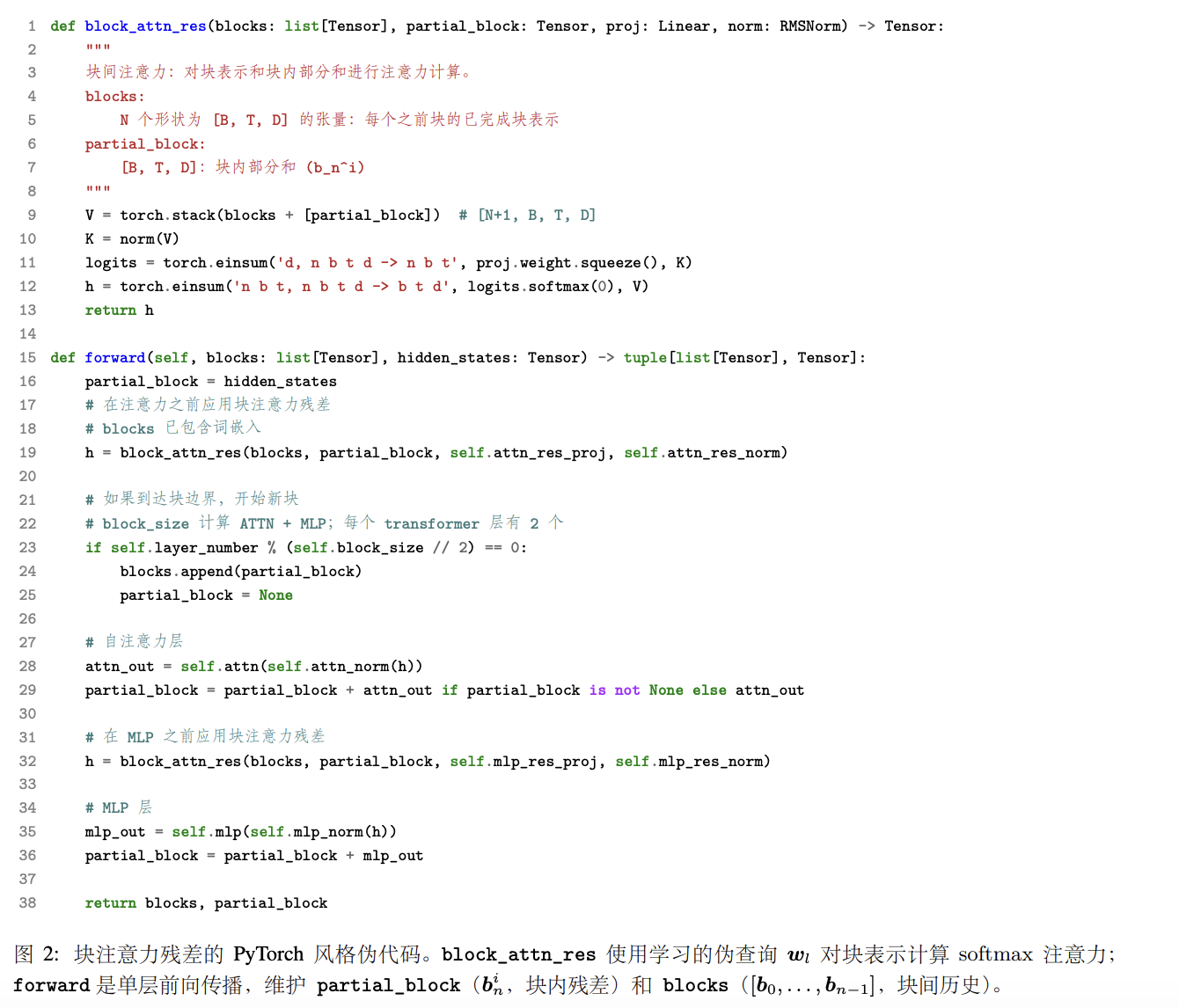
二、传统残差的问题:像“排长龙传话”
用大白话解释一下老方法的毛病。
传统的残差连接,就像让100个人排成一排传话。第1个人说“今天吃了吗”,传到第50个人的时候,已经变成了“今天下雨了”。为什么?因为每个人都在原来的话上加了点自己的东西,最后累加起来,最早的信息早就被稀释没了。
在模型里也一样。以前的残差连接是固定权重的,无论第1层提取的特征多重要,第50层提取的特征多垃圾,到了第100层累加的时候,大家权重都一样。这就导致浅层的关键特征被淹没了,深层的模型其实在“划水”,输出的东西又大又没用。
Kimi团队发现一个问题:随着层数加深,模型输出的数值像吹气球一样暴涨,但梯度(可以理解为学习信号)全集中在前几层,后面的层根本学不到东西。这就相当于公司里只有前几个员工在干活,后面的都在摸鱼,但老板还给他们发一样的工资。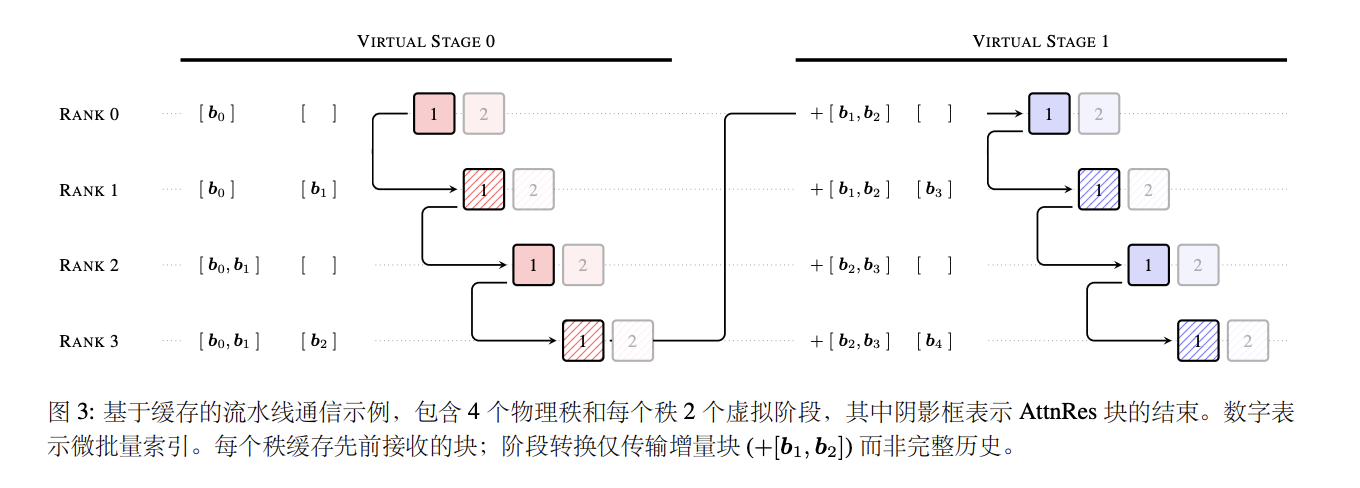
三、Kimi的骚操作:给每一层装上“智能筛选器”
Kimi这次提出的“注意力残差”(Attention Residuals),相当于彻底换了个玩法。
把传话游戏变成“开会讨论”。
传统残差是固定累加,Kimi的新方法是让每一层自己决定:前面那么多层的信息,哪些对我现在处理的任务有用?
他们干了件特别巧的事:把Transformer最核心的“注意力机制”旋转了90度。
原来Transformer里的注意力是干嘛的?是让每个词去看前面所有的词,自己决定该重点关注谁。Kimi说:咱们把这个逻辑用在深度上。让第50层模型去看前面49层的输出,自己决定该重点关注哪一层的特征。
第3层的特征很有用?直接给它加大权重!第30层的输出是噪音?直接忽略。
这样一来,浅层的关键信息再也不会被稀释,深层模型也不用被迫输出巨大数值去“抢麦”了。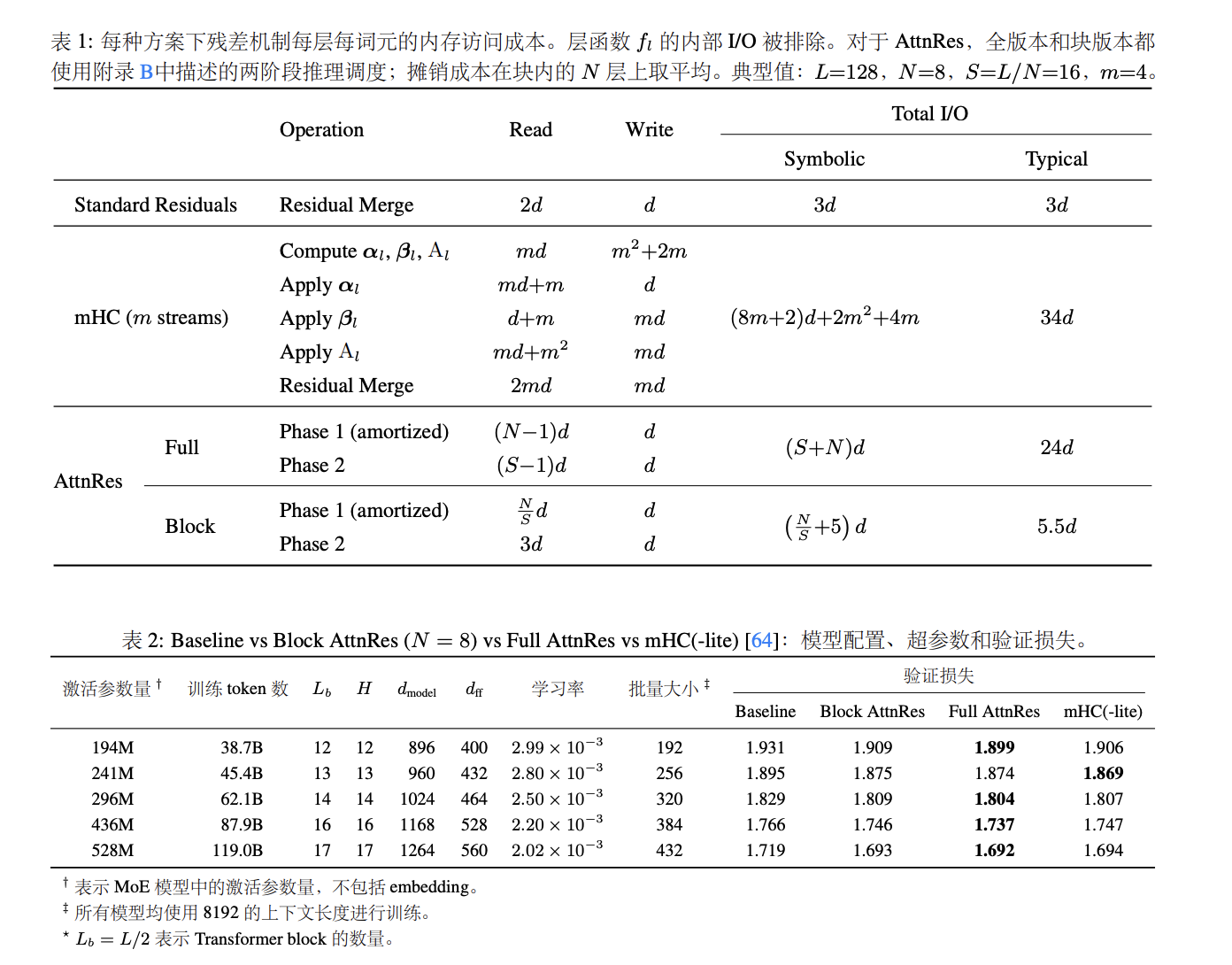
四、效果炸裂:相当于白送1.25倍算力
听起来很美好,但会不会太耗资源?
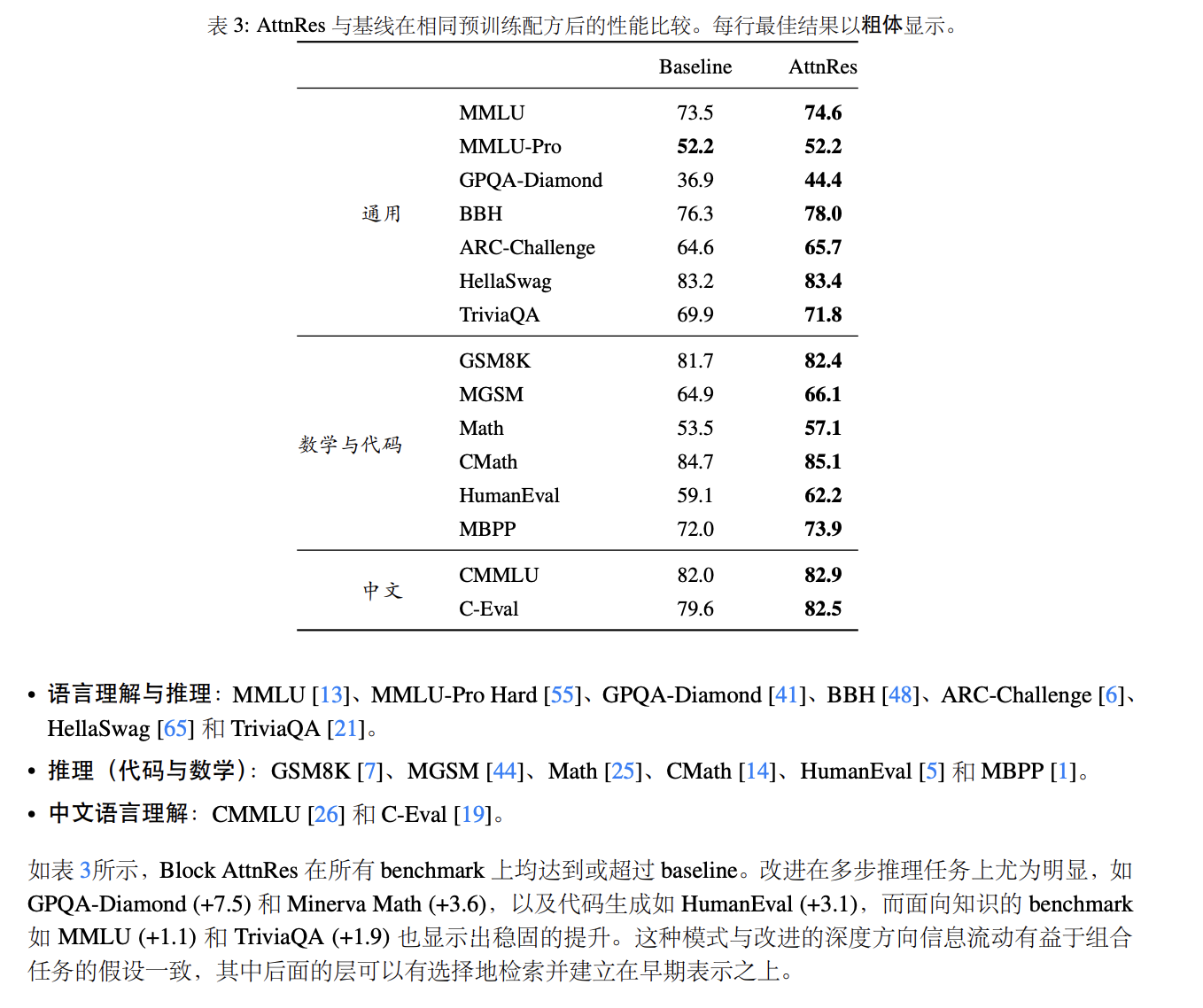
Kimi团队考虑到了。他们设计了一个叫“Block AttnRes”的工程方案,把模型分成几个块,块内保持传统累加保证效率,块之间用注意力动态选择。最后推理延迟只增加了不到2%,几乎可以忽略不计。
效果呢?
- 48B参数的模型,训练效率提升了1.25倍——相当于白送你25%的算力
- 博士级别的科学问答(GPQA-Diamond),成绩暴涨7.5%
- 数学推理(Minerva Math)涨了3.6%,代码生成(HumanEval)涨了3.1%
越难的任务,提升越大。这说明什么?说明这种深度维度的注意力机制,真的让模型学会了“深度思考”。
五、为什么马斯克和Karpathy都惊了?
原因有三:
-
这是地基级的创新。残差连接用了十年,中间字节和DeepSeek都改良过,但都是在原框架里“加车道”“装限速器”。Kimi这次直接把发动机换了。Karpathy那句话潜台词就是:我们一直在用Attention处理序列,但没想到Attention还能处理深度本身。
-
中国团队又捅破一层天花板。去年DeepSeek让英伟达蒸发6000亿美金,今年Kimi直接在架构底层动刀。有网友说得好:“硅谷没人会转发这个帖子,因为承认一家中国实验室免费推动了整个AI领域,就会摧毁那套‘我们需要100亿美元造AGI’的融资故事”。
-
论文一作是个17岁高中生。这事儿更离谱。陈光宇,17岁,去年3月才开始接触机器学习,16岁暑假独自飞帕洛阿尔托做研究,过海关还被二次检查。10月加入Kimi,1月过生日那天还在和同事讨论架构改进。现在18岁,已经是可能改变AI历史的论文一作。
六、所以“深度学习2.0”真的要来了吗?
前OpenAI研究副总裁、被誉为“推理模型之父”的Jerry Tworek看完论文后说了一句话:“一切都需要被重新思考,深度学习2.0要来了”。
这话不夸张。
过去几年,大模型的发展主要靠“堆”——堆数据、堆算力、堆参数。但这次Kimi证明了一件事:堆得深不如堆得聪明。当每一层都能“有意识”地去选择该关注什么,模型的潜力才真正被释放。
Kimi官方回应马斯克点赞时说了句话:“你的火箭造得也不错”。
这回应挺有意思——既有中国式幽默,也有技术自信:你在天上飞你的,我在地上拆我的地基,咱们顶峰相见。
十年残差今犹在,未见当年何恺明。
不对,这回是真的见到了。

这里是“一人公司”的成长家园。我们提供从产品曝光、技术变现到法律财税的全栈内容,并连接云服务、办公空间等稀缺资源,助你专注创造,无忧运营。
更多推荐
 5
5 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)