从零开始搭建AI智能体 2:Python基础 - 异步编程
Python中的异步编程属于异步阻塞,当代码执行到 await 耗时IO操作时,当前协程会主动暂停执行,并把 CPU 时间片交还给事件循环。
同步/异步/阻塞/非阻塞
进行异步编程前需要理解同步/异步/阻塞/非阻塞的概念。
以单cpu为例,假设:
- 时间片长度 = 20ms (时间片代表CPU使用权)
- 被分配的任务 = T(包含 3 个操作:A = 发起文件1下载、B = 处理本地文件2中的数据、C = 检查文件1下载状态)
- 任务T操作时间:
- A = 发起文件 1 下载(IO 操作,触发后由网卡 / 操作系统后台执行,需 2 秒完成)
- B = 处理本地文件 2 中的数据(纯 CPU 计算,无 IO,执行需 18ms)
- C = 检查文件 1 下载状态(轮询指令,单次执行需 1ms)
- CPU 持有 T 的 20ms 时间片,代表cpu在这20ms内的使用权归任务T
同步阻塞
发起 IO 后,CPU 空等结果,完全不执行任务 T 的其他操作(B/C 都不做),直到 IO 完成。
| 时间区间(20ms 时间片内) | CPU 执行操作(任务 T) | 操作说明 | 核心特征 |
|---|---|---|---|
| 0-1ms | 操作 A:发起文件 1 下载 | 触发后台 IO,仅耗时 1ms | 正常执行 |
| 1-20ms | 空等(无任何操作) | 不执行 B、不执行 C,CPU 拿着时间片但闲置 | 阻塞关键:放弃任务 T 的其他操作,纯空等 IO |
同步非阻塞
发起 IO 后,CPU 不空等,而是持续轮询 IO 状态(反复执行 C),仍不执行任务 T 的其他有效操作(B)。
| 时间区间(20ms 时间片内) | CPU 执行操作(任务 T) | 操作说明 | 核心特征 |
|---|---|---|---|
| 0-1ms | 操作 A:发起文件 1 下载 | 触发后台 IO,仅耗时 1ms | 正常执行 |
| 1-2ms | 操作 C:检查文件 1 下载状态 | 单次轮询,结果为 “未完成”,耗时 1ms | 首次轮询 |
| 2-3ms | 操作 C:检查文件 1 下载状态 | 结果仍为 “未完成”,耗时 1ms | 重复轮询 |
| ...(以此类推) | ... | ... | 持续轮询 |
| 19-20ms | 操作 C:检查文件 1 下载状态 | 第 19 次轮询,结果仍为 “未完成” | 时间片用完 |
异步阻塞
发起 IO 后,CPU 不空等,而是将时间片(cpu使用权)分配给其他任务。
| 时间区间(任务 T 的时间片) | CPU 执行操作(任务 T) | 操作说明 | 核心特征 |
|---|---|---|---|
| 0-1ms | 操作 A:发起文件 1 下载 | 触发后台 IO,耗时 1ms | 仅执行 IO 触发指令 |
| 1-20ms | 主动交出时间片 | 任务 T 暂停,CPU 将 20ms 剩余 19ms 时间片分配给其他任务(比如任务 S:处理文件 3 数据) | 阻塞关键:放弃当前时间片使用权,不占用 CPU |
异步非阻塞
发起 IO 后,CPU 不空等,而是执行任务 T 的其他有效操作(B)。
| 时间区间(20ms 时间片内) | CPU 执行操作(任务 T) | 操作说明 | 核心优势 |
|---|---|---|---|
| 0-1ms | 操作 A:发起文件 1 下载 | 触发后台 IO | 正常执行 |
| 1-19ms | 操作 B:处理文件 2 数据 | 有效计算,耗时 18ms | 利用 IO 等待期干正事 |
| 19-20ms | 操作 C:检查下载状态 | 单次轮询,耗时 1ms | 仅用 1ms 查状态 |
协程 ( Coroutine)
已知,一个程序对应一个进程,一个进程中可以拥有多个线程。线程的核心作用是实现任务的并发执行,对于文件下载这类 I/O 密集型操作,多线程能减少整体等待时间(看似 “同时执行” 多个下载任务)。如下代码所示,下载文件为 I/O 操作,需要耗时完成,为了缩短总耗时,可通过创建多个线程来并发下载多个文件。代码中使用的线程池可以统一管理线程、复用线程,还能限制线程数量,避免无节制创建线程。
from concurrent.futures import ThreadPoolExecutor
import time
# 定义一个模拟IO任务的函数
def download_file(file_name):
print(f"开始下载 {file_name}")
time.sleep(2) # 模拟IO等待(线程会释放GIL,不阻塞)
print(f"完成下载 {file_name}")
return f"{file_name} 下载成功"
# 创建线程池,指定最大线程数为3
with ThreadPoolExecutor(max_workers=3) as executor:
# 提交任务到线程池
task1 = executor.submit(download_file, "文件1.txt")
task2 = executor.submit(download_file, "文件2.txt")
task3 = executor.submit(download_file, "文件3.txt")
# 获取任务结果
print(task1.result())
print(task2.result())
print(task3.result())但代码中仅创建了三个线程,如果需要下载成百上千个文件,难道要创建成百上千个线程吗?答案是否定的:1. 成百上千的线程会带来显著的切换开销和内存占用(每个线程约占几 MB 内存),且 Python 受 GIL(全局解释器锁)限制,多线程无法利用多核 CPU;2. 操作系统对单个进程的线程数也有物理上限。但如果线程数太少,大量 IO 等待时间又会导致总耗时过长。针对这个问题,Python 提供了协程来解决。
协程(Coroutine)是用户级的轻量级 “伪线程”,也叫 “微线程”—— 它不是操作系统的线程,而是由 Python 代码主动控制的 “任务执行流”。协程的切换完全由代码主动触发(非操作系统抢占式调度),切换开销远小于线程(无需内核态 / 用户态切换,仅切换函数上下文),效率极高;且一个线程内可以同时运行成百上千个协程,既能实现高并发,又能避免多线程的资源浪费。
asyncio
asyncio是 Python 官方的异步框架(负责管理协程的调度、事件循环、任务并发等),核心是事件循环驱动的异步任务调度。
把asyncio 想象成一个 “单线程的任务调度中心”:
Event Loop
事件循环是 asyncio 最底层的核心组件,是一个无限循环,负责:
- 管理所有异步任务的生命周期(创建、执行、暂停、恢复、结束);
- 监听 IO 事件(如网络响应、文件读写完成);
- 调度任务的执行顺序(非抢占式,只有任务主动
await时才切换); - 处理异步函数的返回值和异常。
不用操心如何实现,asyncio.run()会自动处理。
Future
Future 是一个低层级对象,表示 “一个尚未完成的异步操作的结果”,核心属性:
- 状态:pending / done / canceled
- 结果:任务完成后存储返回值,未完成时获取会阻塞;
- 回调:可绑定回调函数,任务完成后自动执行。
注意,add_done_callback会自动将触发回调的 Future/Task 对象作为第一个参数传给回调函数,这是 asyncio 的固定规则。
import asyncio
def callback(future):
# 回调函数:任务完成后执行
print(f"任务完成,结果:{future.result()}")
# 创建Future对象
future = asyncio.Future()
# 绑定回调函数
future.add_done_callback(callback)
# 模拟任务完成:手动触发done状态
future.set_result("下载成功")
# 输出:任务完成,结果:下载成功Task
Task 是Future的子类,是asyncio中最常用的异步任务对象,核心作用:
- 把协程包装成可被事件循环调度的任务;
- 支持取消任务、查看任务状态、等待任务完成;
- 事件循环可同时调度多个 Task,实现协程的并发执行。
async/await
async/await是定义和控制协程的语法关键字,async定义协程,await控制协程的暂停和恢复(只能在协程中使用)。
将文件下载代码改为异步编程,可以看到,每个文件下载操作用时2秒,采用异步操作后总时间约为2秒。注意,await后面的操作,必须是不需要 CPU 持续参与的操作(基本都是IO操作) —— 一旦触发,它会在 “后台” 自己完成(由操作系统 / 硬件负责),比如asyncio.sleep、 网络请求等I/O操作,CPU 可以去干别的事,等它完成后再回来继续执行协程代码。此外,要注意区分库的同步/异步形式,同步 IO 库(如 requests)即使加了 await 也没用,必须用对应的异步库(如 aiohttp)才能真正后台执行。
import asyncio
from functools import partial
import time
# 定义协程
async def download_file(file_name):
await asyncio.sleep(2)
return f"{file_name} 下载成功(用时2秒)"
# 定义回调函数
def callback(task, custom_msg):
print(f"{custom_msg} - 任务结果:{task.result()},状态:{task._state}")
async def main():
# 创建Task(把协程包装成可调度任务)
task1 = asyncio.create_task(download_file("文件1.txt"))
task2 = asyncio.create_task(download_file("文件2.txt"))
task3 = asyncio.create_task(download_file("文件3.txt"))
# 绑定回调函数
task1.add_done_callback(partial(callback, custom_msg="任务1完成通知"))
task2.add_done_callback(partial(callback, custom_msg="任务2完成通知"))
task3.add_done_callback(partial(callback, custom_msg="任务3完成通知"))
# 查看任务状态
print(f"task1状态:{task1._state}") # 输出:PENDING
# 等待任务完成
res1 = await task1
res2 = await task2
res3 = await task3
print(f"task1状态:{task1._state}") # 输出:FINISHED
# 启动事件循环,执行任务
start = time.time()
asyncio.run(main())
end = time.time()
print(f'总用时 = {end - start}')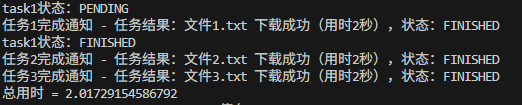

这里是“一人公司”的成长家园。我们提供从产品曝光、技术变现到法律财税的全栈内容,并连接云服务、办公空间等稀缺资源,助你专注创造,无忧运营。
更多推荐

 40
40 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)