从零开始搭建AI智能体 9:RAG原理及简单实现
RAG核心概念
背景
预训练语言模型虽能将事实知识存储在参数中,但其存在三大核心局限:知识难以扩展 / 修订(时间局限性?不能获取实时的信息)、无法为预测提供溯源(来源不知)、生成内容易产生 “幻觉”。
RAG与传统微调的对比优势
- 传统微调:让模型记住知识(改变模型参数)
- RAG:让模型学会查阅知识(不改变模型参数,动态获取)
(RAG擅长处理长尾问题,长尾问题:问的人极少,但问题种类极多,合起来占了大部分请求)
索引和检索生成
RAG核心流程:原始文档 → 索引阶段 → 向量知识库 → 检索生成阶段 → 最终答案。
可以新建一个jupyter文件来实操rag(非langchaini框架),然后让ai生成一个md格式的内容,用来测试查询。

file.md
索引(Indexing)
目标:将原始文档转化为可高效检索的向量知识库。
文档加载与分割(chunking)
根据文章内容,进行语义分割:
# chunking
def split_into_chunks(doc_file: str) -> str:
with open(doc_file, 'r') as file:
content = file.read()
return [chunk for chunk in content.split("\n#")]
chunks = split_into_chunks("file.md")
print(len(chunks))
for i,chunk in enumerate(chunks):
print(f"[{i}] {chunk}\n")
分割方法总结:
|
方法 |
优点 |
缺点 |
适用场景 |
|
固定长度分割 |
简单快速 |
可能切断完整句子 |
技术文档 |
|
递归字符分割 |
保持语义完整性 |
稍复杂 |
通用文档 |
|
语义分割 |
最佳语义边界 |
计算成本高 |
重要报告 |
|
重叠分割 |
保留上下文 |
存储冗余 |
问答系统 |
文本向量化(Embedding)
文本向量化需要加载模型来对分割后的文本进行向量化,text2vec-base-chinese模型是huggingface中开源的一个模型,可直接下载放到本地,但是huggingface需要科学上网,国内有些网站也可以下载,需要搜索。
# embedding
from sentence_transformers import SentenceTransformer
embedding_model = SentenceTransformer("./model/text2vec-base-chinese")
def embed_chunk(chunk: str) -> list[float]:
embedding = embedding_model.encode(chunk)
return embedding.tolist()
embeddings = [embed_chunk(chunk) for chunk in chunks]
print(len(embeddings))
print(embeddings[0])
- 嵌入模型选择:
text-embedding-3-large:精度最高text-embedding-3-small:速度/成本平衡bge-large-zh:中文优化
ps. 模型与向量维度匹配,有的模型可以自由设置向量维度
向量数据库
文本向量化之后需要储存到向量数据库,选用chromadb:
import chromadb
chromadb_client = chromadb.EphemeralClient() #PersistentClient()
chromadb_collection = chromadb_client.get_or_create_collection(name="default")
def save_embeddings(chunks: list[str], embeddings: list[list[float]]) -> None:
ids = [str(i) for i in range(len(chunks))]
chromadb_collection.add(
documents=chunks,
embeddings=embeddings,
ids=ids
)
save_embeddings(chunks, embeddings)向量数据库:
|
数据库 |
优点 |
缺点 |
适合场景 |
|
Pinecone |
全托管,易用 |
付费,有延迟 |
生产环境 |
|
Chroma |
轻量,开源 |
功能较基础 |
开发/测试 |
|
Weaviate |
功能丰富,自带ML |
配置复杂 |
企业级 |
|
Qdrant |
性能好,Rust编写 |
社区较小 |
高性能需求 |
|
FAISS |
Facebook出品,高效 |
仅内存存储 |
研究/实验 |
检索生成(Retrieval & Generation)
目标:基于用户查询(query),从知识库找到相关信息并生成优质答案
查询处理与索引(Retrieve)
先将query进行向量化,然后获取top_k个可能符合query的向量片段:
# retreve
def retrieve(query:str, top_k: int) -> list[str]:
query_embedding = embed_chunk(query)
results = chromadb_collection.query(
query_embeddings=[query_embedding],
n_results=top_k
)
return results['documents'][0]
query = "Luna是什么职业的?"
retrieved_chunks = retrieve(query, 5)
for i, chunk in enumerate(retrieved_chunks):
print(f"[{i}] {chunk}\n")
对top_k个结果进行重排序(Rerank):
from sentence_transformers import CrossEncoder
def rerank(query: str, retrieved_chunks: list[str], top_k: int) -> list[str]:
cross_encoder = CrossEncoder('./model/mmarco-mMiniLMv2-L12-H384-v1')
pairs = [(query, chunk) for chunk in retrieved_chunks]
scores = cross_encoder.predict(pairs)
chunk_with_score_list = [(chunk, score) for chunk, score in zip(retrieved_chunks, scores)]
chunk_with_score_list.sort(key=lambda pair: pair[1], reverse=True)
return [chunk for chunk, _ in chunk_with_score_list][:top_k]
rerank_chunks = rerank(query, retrieved_chunks, 3)
for i, chunk in enumerate(rerank_chunks):
print(f"[{i}] {chunk}\n")
检索方法:
|
策略 |
方法 |
适用场景 |
|
简单向量检索 |
余弦相似度(最大内积搜索) |
基础问答 |
|
多查询检索 |
生成多个相关查询(原始查询->多个子查询->分别检索 |
复杂问题 |
|
分层检索 |
先关键词过滤,再向量检索 |
大型知识库 |
|
混合检索 |
BM25(关键词匹配) + 向量相似度加权 |
高精度需求 |
|
自我检索 |
模型判断是否需要检索 |
减少不必要检索 |
生成
from langchain_ollama import ChatOllama
from langchain_core.messages import HumanMessage
def generate_result(query: str, chunks: list[str]) -> str:
chunks_text = "\n\n".join(chunks)
prompt = f"""你是一位知识助手,请根据用户的问题和下列片段生成准确的答案。
用户问题: {query}
相关片段: {chunks_text}
请基于上述内容作答,不要编造信息。"""
llm = ChatOllama(model='llama3.2:3b-instruct-q4_K_M', temperature=0.1)
response = llm.invoke([HumanMessage(content=prompt)])
result = response.content.strip()
print("生成结果:", result)
return result
generate_result(query,rerank_chunks)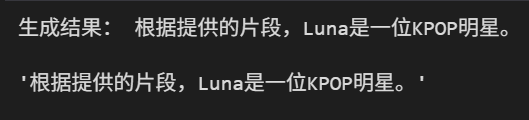
接下来会用langchain架构实现一个完整的rag项目。

这里是“一人公司”的成长家园。我们提供从产品曝光、技术变现到法律财税的全栈内容,并连接云服务、办公空间等稀缺资源,助你专注创造,无忧运营。
更多推荐

 19
19 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)