Dify 1.14.2 发布:安全、工作流、RAG 与部署能力继续补强
大家好,我是独孤风。
Dify 1.14.2 已经发布。
这次官方给出的版本说明很直接:这是 1.14.1 之后的一次补丁版本,重点放在安全加固、工作流和知识库可靠性、观测追踪修复、Agent 基础工作,以及部署和运行时调优上。
所以这篇文章我不把它写成“重大功能发布”,也不强行拔高。
如果只看版本号,1.14.2 很容易被当成一次普通小版本。但如果你正在自托管 Dify,或者已经把 Dify 用在工作流、知识库、RAG、HITL 和企业应用里,这次更新仍然值得认真看。
我的判断是:
Dify 1.14.2 不是在做新功能展示,而是在继续修企业 AI 应用平台进入生产环境后真正会遇到的问题。

一、先说结论:这次更新可以分成五类
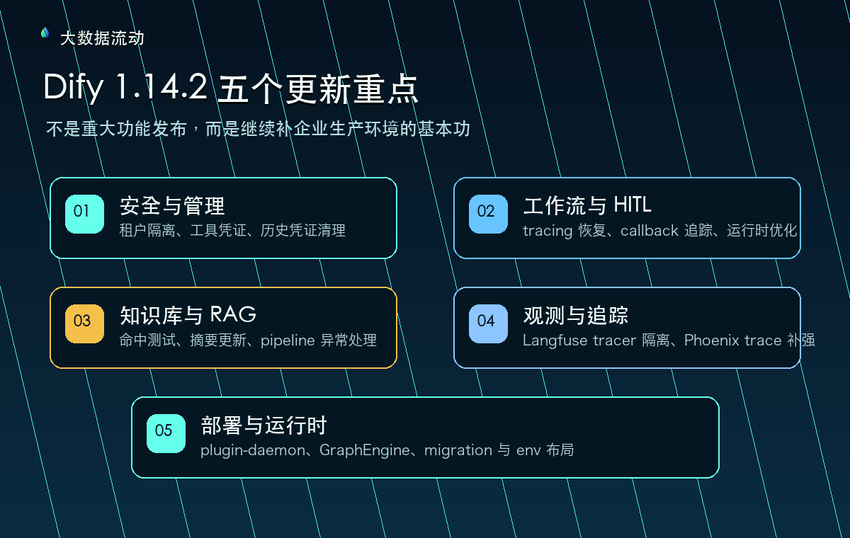
我把 Dify 1.14.2 的更新拆成五个重点来看:
① 安全与管理:加强租户隔离,限制默认工具凭证更新权限,清理历史租户工具凭证。
② 工作流、HITL 与运行时:修复 HITL 恢复后的 tracing,增强 workflow run callback tracking,减少数据库往返,修复部分 Flask context 和 base64 文件查询问题。
③ 知识库、RAG 与文档处理:修复知识库命中测试渲染、空知识库创建、LLM 节点访问检索文件、文档摘要更新、RAG pipeline 凭证异常处理等问题。
④ 观测与追踪:隔离 Langfuse v3 SDK tracer providers,补充 Phoenix parent trace fallback。
⑤ 部署、依赖与开发体验:plugin-daemon 升级到 0.6.1,提高 GraphEngine 默认最小 worker 数,更新 Docker 文档引用,升级后端和 agent 依赖。
这五类更新放在一起,传递出的信号很清楚:
Dify 正在把 1.14 系列的大能力继续往可维护、可观测、可部署、可升级的方向打磨。
1.14.0 更像是能力边界的推进,比如协作、HITL、MCP、RAG、插件和自托管基础设施。
1.14.1 和 1.14.2 则更像是连续补生产环境细节。
这其实很正常。一个 AI 应用平台真正进入企业使用以后,最难的并不是再加几个漂亮功能,而是这些功能能不能稳定运行、能不能被团队维护、能不能被安全边界约束、出了问题能不能追踪。
二、安全更新:这次重点还是租户边界和工具凭证
这次 1.14.2 里,我首先关注的是安全和管理相关更新。
官方提到两类重点:
① 租户级敏感端点隔离加强;
② 工具凭证安全边界继续收紧。
第一类,是 app trace-config endpoints 和 FilePreview text extraction 的租户隔离增强。
这件事看起来偏底层,但放在企业里非常关键。
Dify 一旦接入真实业务,不只是一个工作流画布,它还会沉淀应用配置、运行日志、知识库文件、工具凭证、模型配置和 tracing 数据。如果租户隔离边界不严,就可能出现本不该访问的数据被访问。
第二类,是默认 builtin tool credential 的更新权限被限制到 workspace admins 和 owners,同时在 reset-encrypt-key-pair 时清理历史租户工具凭证。
这说明 Dify 正在继续收紧工具调用的管理边界。
企业 AI 应用里,工具凭证不是小事。因为工具往往意味着:
① 访问外部 API;
② 连接内部系统;
③ 调用模型服务;
④ 读取文件或知识库;
⑤ 执行业务动作。
如果工具凭证可以被不合适的角色修改,或者历史凭证没有清理干净,就可能带来安全和审计风险。
所以对自托管团队来说,这次安全更新不应该只当作“修了几个漏洞”。它更像是在提醒我们:
Dify 这类 AI 应用平台,后面一定要按照企业软件的方式管理权限、凭证、租户和审计。
三、工作流和 HITL:修的是生产流程的连续性
Dify 的工作流能力,已经是很多人选择它的核心原因。
但工作流进入真实场景以后,问题会变得很具体:
① 流程暂停后能不能恢复;
② HITL 人工审核后 tracing 会不会断;
③ 回调能不能准确追踪;
④ 大量消息更新会不会给数据库带来压力;
⑤ 节点执行时上下文会不会出错;
⑥ 文件查询和资源释放是否正确。
这次 1.14.2 在 workflow、HITL 和 app runtime 上,修的就是这些问题。
官方提到,1.14.2 恢复了 HITL workflow resume 之后的 tracing,改进了 workflow run callback tracking,减少了 message-update database roundtrips,修复了 Flask context 之外 memory fetch 的问题,并正确关闭 base64 file lookup sessions。
这些不是“看起来很酷”的功能,但它们决定工作流能不能在生产环境里稳定跑。
为什么 HITL 后 tracing 恢复很重要?
因为人机协同流程通常不是一口气跑完的。流程可能会在某个节点暂停,等待人工审核、补充信息、选择动作或确认风险。等人处理完以后,流程再继续执行。
如果 tracing 在这个过程中断掉,后面排查问题就会非常困难:
① 不知道流程卡在哪里;
② 不知道人工节点前后发生了什么;
③ 不知道模型调用、工具调用和回调之间的关系;
④ 不知道一次业务结果到底由哪些节点共同产生。
所以这类修复的意义,不是“日志好看一点”,而是让企业能真正追踪一条 AI 工作流从开始到结束的执行链路。
对已经在用 Dify 做工作流的团队,我建议重点看这部分更新。尤其是有 HITL、回调、文件处理、长流程、多节点编排的场景,1.14.2 不是可有可无。
四、RAG 和知识库:这次依然在补细节
Dify 1.14.2 里,知识库和 RAG 相关修复也不少。
官方列出的重点包括:
① 修复 knowledge hit-testing 渲染;
② 修复空 knowledge 创建问题;
③ 修复 recommended app category 排序和详情空值处理;
④ 允许 LLM 节点访问检索到的知识文件;
⑤ API 更新后重新生成文档摘要;
⑥ 修复 pipeline template rendering;
⑦ RAG pipeline 中凭证获取失败时更优雅地处理。
这里面最值得关注的,不是某一个单点修复,而是它们覆盖的环节比较完整。
从知识库创建,到命中测试;从文档摘要,到检索文件访问;从 pipeline 模板渲染,到凭证异常处理,都是企业 RAG 真正落地时会遇到的细节。
很多人第一次做 RAG,会把问题理解成:
① 文档能不能上传;
② 能不能切分;
③ 能不能向量化;
④ 能不能问答。
但真正用起来以后,问题会细很多:
① 命中测试能不能稳定展示;
② 文档更新后摘要是否同步;
③ LLM 节点能否拿到检索文件;
④ pipeline 模板是否能正确渲染;
⑤ 凭证失效时能否优雅失败;
⑥ 知识库编辑权限是否能正确处理;
⑦ 数据集 UI 是否能避免误操作。
Dify 这次继续修这些细节,说明它在往一个更真实的方向走:RAG 不是一次性搭建,而是长期维护。
这也给使用者一个提醒:
知识库和 RAG 不能只看首次搭建效果,更要看更新、测试、权限、异常处理和长期维护能力。
如果你的 Dify 知识库已经接了业务文档、产品手册、客服资料、制度流程、项目资料,这部分更新值得关注。
五、观测与追踪:AI 应用上线后,必须能解释发生了什么
这次 1.14.2 单独提到了 observability and tracing。
官方更新里有两个点:
① 隔离 Langfuse v3 SDK tracer providers,避免跨任务干扰;
② 增加 Phoenix parent trace fallback behavior。
这说明 Dify 继续在补 AI 应用上线后的可观测能力。
很多团队刚开始做 AI 应用时,注意力都在效果上:
① 回答准不准;
② 流程能不能跑;
③ 模型调用快不快;
④ 成本高不高。
但真正上线以后,团队更常遇到的是另外一类问题:
① 为什么这次回答和上次不一样;
② 哪个节点消耗最多;
③ 哪次调用失败了;
④ 检索到了哪些知识;
⑤ 哪个工具返回异常;
⑥ 人工审核前后流程状态是否一致;
⑦ 一次失败到底是模型、知识库、工具、网络还是权限的问题。
这些问题如果没有 tracing,很难排查。
所以可观测性不是高级功能,而是生产环境基本能力。
特别是当 Dify 工作流开始变长、工具开始变多、RAG 管道开始复杂,tracing 的价值会越来越明显。它不是为了开发者“看日志”,而是为了让企业能解释、定位和改进 AI 应用的运行过程。
六、部署和升级:自托管团队仍然要谨慎
1.14.2 还有一组部署、依赖和开发体验相关更新。
几个点值得注意:
① plugin-daemon 升级到 0.6.1;
② GraphEngine 默认最小 worker 数提高;
③ Docker README 引用更新;
④ 后端和 CI 维护继续推进;
⑤ 依赖更新包括 authlib、ujson、langsmith、urllib3 等。
同时,官方 Upgrade Guide 里仍然强调了几件事:
① 本次发布包含新的数据库 migration,用于可配置 Explore app categories;
② Docker Compose 环境变量已经拆分到 docker/envs/** 下;
③ 如果维护了自定义 docker-compose.yaml 或 .env,需要检查新布局并重新应用本地修改;
④ 自托管部署中,显式配置的 SECRET_KEY 会继续被尊重,如果为空,Dify 会自动生成并持久化运行时 key。
这部分对普通用户可能不显眼,但对自托管团队非常重要。
升级 Dify 不能只理解为“拉一个新镜像”。尤其是从 1.14 系列开始,Docker 环境变量布局、数据库 migration、plugin-daemon、GraphEngine、SECRET_KEY 等都在变化。
如果你是自托管,建议至少做四件事:
① 备份 docker-compose.yaml、.env 和 volumes;
② 阅读 docker/envs/** 新布局,确认本地自定义配置是否需要迁移;
③ 执行数据库 migration,不要跳过升级步骤;
④ 升级后重点验证工作流、知识库、RAG、插件和 tracing。
生产环境里,升级不怕慢一点,怕的是没备份、没看 migration、没验证关键流程。
七、和 1.14.0、1.14.1 连起来看,Dify 的路线更清楚
如果把 1.14.0、1.14.1、1.14.2 连起来看,Dify 最近几个版本的路线其实很清楚。
1.14.0 更像是能力推进:
① 协作模式;
② HITL Service API;
③ MCP 和插件能力;
④ RAG 与知识库增强;
⑤ 自托管基础设施优化。
1.14.1 更像是第一轮生产细节修补:
① 自托管安全;
② 工作流稳定性;
③ 知识库和 RAG 细节;
④ Docker 部署和升级路径。
1.14.2 则继续沿着这个方向往下补:
① 租户隔离;
② 工具凭证;
③ HITL 和 workflow tracing;
④ RAG pipeline 和文档处理;
⑤ observability;
⑥ plugin-daemon、GraphEngine 和依赖更新。
所以我不会把 1.14.2 说成“重大版本”,但它对正在严肃使用 Dify 的团队有价值。
因为企业 AI 应用平台真正的成熟,不是每次都发布一个新概念,而是持续把安全、可靠性、可观测性、部署和升级这些基础能力补齐。
这才是生产级平台的样子。
八、最后说几句
对 Dify 1.14.2,我的建议很简单。
如果你只是个人试用,可以关注但不必焦虑。
如果你正在自托管,或者已经把 Dify 用在工作流、知识库、RAG、HITL、工具调用和企业应用里,这次值得安排升级评估。
重点看三件事:
① 安全边界是否更稳;
② 工作流和 RAG 是否修到了你当前踩过的问题;
③ 升级路径是否涉及你的 Docker 配置、数据库 migration 和本地自定义环境变量。
Dify 1.14.2 最值得看的地方,不是它又多了什么新玩法,而是它继续在补企业 AI 应用平台的基本功。
这类更新可能不够热闹,但对真正上线的人来说,往往更重要。
参考来源:Dify GitHub Release v1.14.2。
我正在持续整理《AI时代数据治理实战库》。
它会围绕两条主线展开:
-
Data for AI:数据如何支撑 AI。
-
AI for Data:AI 如何反过来改造数据治理。
前者是基础,后者是新机会。
如果你关心 AI 时代的数据治理、企业 AI 数据底座、RAG、Agent、元数据、血缘、质量、标准、知识图谱、本体论和企业 AI Agent 工程化,可以扫码订阅知识库。

关注「大数据流动」,我们继续用大数据工程化和企业落地视角,拆解 AI 时代真正需要补的底层能力。

这里是“一人公司”的成长家园。我们提供从产品曝光、技术变现到法律财税的全栈内容,并连接云服务、办公空间等稀缺资源,助你专注创造,无忧运营。
更多推荐

 14
14 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)