Keel:AI Agent驱动的软件开发生命周期管理与协同平台
1. 项目概述:当软件开发生命周期遇上“智能体”
如果你和我一样,在软件工程领域摸爬滚打了十几年,从瀑布模型到敏捷,再到DevOps,你可能会觉得,我们已经把流程优化到了极致。但最近几年,随着AI Agent(智能体)技术的爆发,一个全新的挑战摆在了我们面前:如何管理那些能自主写代码、跑测试、甚至部署上线的“AI同事”?传统的项目管理工具,比如Jira、Confluence,或者CI/CD流水线,是为人类协作设计的。它们能追踪任务、管理文档、自动化构建,但它们无法理解一个AI Agent在执行“修复登录模块的Bug”这个任务时,到底在想什么、做了什么、卡在了哪里。
这就是“Keel”这个项目试图解决的问题。你可以把它想象成给一群高度自主、能力强大的AI Agent套上的“缰绳”或“牵引绳”。它的核心定位,是一个面向智能体驱动的软件开发生命周期(Agentic SDLC)的管理平台。简单来说, Keel不是替代现有的DevOps工具链,而是在其上增加一个“智能体管理层” ,专门用来观察、协调、审计和控制AI Agent在整个SDLC中的活动。
想象一下这个场景:你给一个代码生成Agent下达指令:“为购物车模块添加优惠券功能。”在Keel出现之前,这个Agent可能会默默地生成代码、尝试运行测试、遇到依赖问题后陷入死循环,或者生成不符合团队规范的代码风格。你作为人类开发者,只能在最后验收时才发现一堆问题,回溯和调试极其困难。而有了Keel,整个过程变得透明且可控:你能实时看到Agent分解了哪些子任务、调用了哪些工具(如代码库查询、单元测试运行器)、每一步的执行结果和“思考”过程(它的推理链),甚至在它即将做出一个有风险的修改(比如删除一个核心配置文件)时,及时进行人工干预或审批。
Keel解决的,正是智能体时代软件开发的核心矛盾:赋予AI高度自主权以提升效率,同时确保整个过程的可观测性、安全性与合规性。 它适合正在或计划将AI Agent深度集成到其开发流程中的技术团队、平台工程(Platform Engineering)团队以及研发效能(DevOps)负责人。无论你是想用Agent做自动化代码审查、智能测试生成,还是构建一个完全由Agent协作完成功能的“AI软件工厂”,Keel这类工具都是你不可或缺的“中枢神经系统”。
2. Keel的核心架构与设计哲学
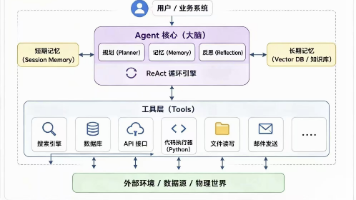
要理解Keel如何工作,我们不能只把它看成一个简单的监控面板。它的设计渗透了对Agentic SDLC本质的深刻理解。一个自主的AI Agent在软件开发中,本质上是一个 在特定约束下,通过感知环境、调用工具、执行动作来达成复杂目标的智能体 。Keel的架构就是围绕这个定义展开的。
2.1 分层管控模型:观察、理解、控制
Keel的架构通常可以抽象为三个核心层次,我将其称为“观察-理解-控制”模型。这个模型确保了管理的粒度从粗到细,适应不同的场景需求。
-
观察层(Observability Layer) :这是基础。Keel需要接入所有Agent的活动日志、工具调用记录、产生的工件(代码、配置、文档)以及其内部的“思维”过程(即Chain-of-Thought)。这不仅仅是收集日志,而是需要结构化的数据模型。例如,一个“代码生成”动作,需要记录:触发指令、关联的需求或任务ID、使用的代码库上下文、生成的代码片段、调用的代码模型(如GPT-4, Claude等)及其参数。这一层通常通过Agent SDK或中间件来实现无侵入式集成。
-
理解层(Comprehension & Orchestration Layer) :这是Keel的大脑。观察层收集的原始数据是杂乱且低语义的。理解层的作用是将其转化为有意义的“开发活动”。它需要:
- 活动关联 :将分散的工具调用(如“读取文件A”、“调用API B”、“写入文件C”)聚合成一个完整的“实现功能X”的活动。
- 状态追踪 :定义Agent任务的状态机(如:规划中、执行中、阻塞、成功、失败),并实时更新。
- 编排与路由 :在多个Agent协作的场景下(例如,一个需求分析Agent将任务拆解后分发给多个代码生成Agent),Keel需要充当协调者,负责任务的分配、依赖管理和结果汇总。这类似于一个面向Agent的“工作流引擎”。
-
控制层(Control & Governance Layer) :这是Keel作为“缰绳”的关键体现。基于理解层提供的上下文,控制层允许人类设置策略和边界。主要包括:
- 护栏(Guardrails) :定义Agent的“行动边界”。例如,禁止Agent修改
production分支的代码、禁止安装未经许可的NPM包、要求生成的代码必须通过ESLint检查等。护栏通常在动作执行前进行校验。 - 审批门(Approval Gates) :对于高风险操作,设置人工审批节点。例如,任何涉及数据库Schema变更或生产环境部署的Agent操作,必须经过资深工程师确认。
- 干预机制 :允许人类在Agent任务执行过程中随时暂停、修改指令或直接接管。这保证了人类始终拥有最高控制权。
- 护栏(Guardrails) :定义Agent的“行动边界”。例如,禁止Agent修改
实操心得 :在设计或选型类似平台时, “无侵入式集成” 是关键。理想情况下,团队现有的Agent(基于LangChain、LlamaIndex或自定义框架)只需要引入一个轻量级SDK或通过一个中间代理(Sidecar)发送遥测数据,就能被Keel管理,而不是要求重写整个Agent逻辑。这大大降低了 adoption 成本。
2.2 核心组件拆解
基于上述模型,一个典型的Keel系统会包含以下核心组件:
- Agent Registry(智能体注册中心) :管理所有已注册Agent的元信息,包括能力描述、可用工具、所属团队、负责领域(如前端、后端、测试)等。这是进行智能任务分配的基础。
- Activity Stream(活动流) :一个实时的事件总线,接收来自所有Agent的结构化活动事件。这是观察层的数据入口。
- Workflow Engine(工作流引擎) :预定义或动态生成Agent协作的工作流。例如,一个标准的“功能开发”工作流可能包含:需求分析Agent -> 技术设计Agent -> 后端实现Agent & 前端实现Agent -> 集成测试Agent。引擎负责驱动流程,处理分支、循环和错误重试。
- Policy Engine(策略引擎) :这是控制层的核心。它加载并执行团队定义的策略规则(通常用YAML或DSL编写),对Agent的活动进行实时评估和决策。例如:
policy_id: "no-prod-modify" description: "禁止Agent直接修改生产分支" condition: | activity.type == "git_commit" AND activity.branch == "main" action: "block" - Audit Trail(审计追踪) :不可篡改的、完整的操作日志。记录谁(哪个Agent或用户)、在什么时间、做了什么操作、基于什么上下文、产生了什么结果。这对于事后复盘、合规性检查和责任界定至关重要。
- Human-in-the-Loop(人机回环)界面 :一个直观的Dashboard。它应该展示:所有进行中/已完成的Agent任务看板、实时活动流、任务详情(包括完整的推理链和工具调用历史)、待审批项列表以及系统健康状态。
这个架构确保了Keel既能给予Agent广阔的发挥空间,又能让人类管理者心中有数,手中有闸。
3. 核心功能场景与实操解析
理解了架构,我们来看看Keel在真实开发流程中如何大显身手。我将通过几个核心场景,拆解其功能细节和实操要点。
3.1 场景一:端到端的AI功能开发任务管理
这是最复杂的场景。假设产品经理在Keel界面提交了一个需求:“用户可以在个人资料页上传头像。”
1. 任务解析与规划: Keel首先会将这个自然语言需求抛给一个“需求分析Agent”。这个Agent基于历史数据和团队规范,将需求拆解为结构化任务清单,并预估每个任务所需的Agent类型和依赖关系。输出可能如下:
任务清单:
1. [后端] 设计并实现头像上传API端点(RESTful POST /api/user/avatar)
- 依赖:无
- 负责Agent:后端开发Agent(Java/Spring)
2. [后端] 在用户模型中增加avatar_url字段,并更新数据库Schema
- 依赖:任务1的API设计确定
- 负责Agent:后端开发Agent
3. [前端] 在用户资料页添加头像上传UI组件
- 依赖:任务1的API接口定义
- 负责Agent:前端开发Agent(React)
4. [测试] 编写并执行头像上传功能的集成测试
- 依赖:任务1,2,3完成
- 负责Agent:测试生成Agent
Keel的工作流引擎会接收这个清单,自动创建任务项,并根据依赖关系生成一个有向无环图(DAG),调度相应的Agent开始工作。
2. 协同执行与上下文传递: 后端开发Agent开始处理任务1。它可能会进行以下活动,所有活动都被Keel捕获:
- 活动1(规划) :思考:“我需要一个接收multipart/form-data的控制器,一个服务来处理文件存储(可能用S3),以及更新用户实体。”
- 活动2(工具调用) :查询现有的
UserController和UserService代码,获取上下文。 - 活动3(执行) :生成新的
AvatarUploadController.java和AvatarService.java代码。 - 活动4(自检) :调用本地Maven编译,确保代码无语法错误。
- 活动5(提交) :将代码提交到特性分支
feat/user-avatar-upload。
关键点在于,当任务1完成并提交后,Keel会自动将相关的产出物(如API的Swagger文档、接口定义)作为“上下文”传递给依赖它的任务3(前端开发Agent)。前端Agent无需再向后端询问接口格式,直接从Keel提供的上下文中获取,确保了信息一致性。
3. 异常处理与人工干预: 假设后端Agent在任务2(更新数据库)时,尝试执行一个 ALTER TABLE 语句,而这条语句因为外键约束可能失败。Keel的策略引擎可能配置了规则:“任何数据库DDL操作需经人工审批”。于是,任务状态变为“阻塞-等待审批”,并向指定的数据库管理员(DBA)发送通知。DBA在Keel的界面上可以看到Agent试图执行的SQL语句、失败原因分析(由Agent或Keel提供),并决定是批准、修改后批准,还是驳回并让Agent重新规划。
注意事项 : 上下文管理是协同效率的核心 。设计时,需要定义清晰的“上下文契约”,明确每个任务产出哪些可被下游消费的“工件”(Artifact),如接口定义、数据模型、组件Props等。避免传递过时或冗余的上下文,否则会导致Agent confusion。
3.2 场景二:智能代码审查与合规性检查
传统的CI/CD流水线可以在合并请求(PR)时运行静态检查(Lint)和单元测试。Keel可以将这个过程智能化、前置化。
实操流程:
- 开发者(或一个代码生成Agent)向版本库推送了代码。
- Keel监听到推送事件,自动触发“代码审查Agent”。
- 该Agent不仅运行ESLint/SonarQube,还会做以下事情:
- 架构一致性检查 :分析代码变更是否遵循了团队定义的架构模式(如分层架构、Clean Architecture)。例如,检查
Service层是否直接引用了Controller层的类。 - 安全漏洞扫描 :使用类似Semgrep的规则,并结合LLM的语义理解,检测潜在的安全问题(如硬编码密钥、SQL注入风险)。
- 业务逻辑复审 :基于提交信息(Commit Message)和需求文档,判断代码变更是否完整实现了需求,是否存在明显的逻辑遗漏。
- 生成审查报告 :将发现的问题分类(阻塞项、警告项、建议项),并以注释的形式直接提交到PR中,或生成一份详细的报告。
- 架构一致性检查 :分析代码变更是否遵循了团队定义的架构模式(如分层架构、Clean Architecture)。例如,检查
核心优势 :与传统工具相比,Keel驱动的审查是 可解释的 。它不会只抛出一个“复杂度太高”的警告,而是会指出:“这个方法里 if/else 嵌套超过3层,建议拆分为 validateInput() 、 processData() 和 formatOutput() 三个独立方法以提升可读性。” 这种基于LLM的“原因解释”极大地提升了审查意见的可接受度和教育意义。
3.3 场景三:生产环境事故的智能诊断与修复
这是体现Keel“缰绳”价值的另一个高阶场景。当监控系统报警(如某API错误率飙升),Keel可以自动启动一个“事故响应”工作流。
-
诊断Agent出动 :Keel将报警信息(错误日志、指标图表)发送给诊断Agent。该Agent会:
- 查询近期部署记录,定位可能的问题变更。
- 分析错误堆栈和日志模式。
- 查询相关服务的依赖健康状况。
- 在几分钟内生成一份初步诊断报告,假设为:“疑似最新部署的
user-service v1.2.3中,数据库连接池配置参数maxPoolSize从50被误设为5,导致高并发下连接耗尽。”
-
修复方案生成与风险评估 :诊断报告触发修复Agent。修复Agent会:
- 生成一个修复PR:将
maxPoolSize改回50,并添加相应的配置说明注释。 - 关键一步 :运行一个“影响评估”模拟。它可能调用测试Agent,针对这个配置变更运行一波压力测试,预估修复后的性能表现。
- 将修复PR、诊断报告和影响评估报告一并提交给Keel。
- 生成一个修复PR:将
-
紧急审批与自动化修复 :由于是生产事故,团队可能预先在Keel中设置了策略:“对于P0级事故,若修复方案为简单的配置回滚且影响评估风险为低,可自动合并并部署至预发环境;生产环境部署仍需人工确认。” Keel根据策略,自动将修复合并到主分支,并触发CI/CD流水线部署到预发环境。同时,通知值班工程师在Dashboard上对生产部署做最终确认。
这个场景展示了Keel如何将AI的快速分析、决策能力与人类的最终控制权完美结合,实现“AI冲锋,人类掌舵”的应急响应模式。
4. 实施路径与集成考量
引入Keel这样的平台不是一个“一键安装”的过程,而是一个需要精心规划的工程实践。根据我的经验,建议采用分阶段、渐进式的实施路径。
4.1 阶段一:从可观测性开始(“看见”你的Agent)
不要一开始就追求全自动化的控制。第一步的目标是“透明化”。
- 动作 :为你团队现有的、最活跃的1-2个AI Agent(比如一个自动生成单元测试的Agent)集成Keel的SDK,开始收集其所有活动事件。
- 产出 :在Keel的Dashboard上,你能清晰地看到这个Agent每天被触发了多少次、执行了哪些任务、成功率如何、平均耗时多少、最常调用的工具是什么。
- 价值 :这个阶段能帮你发现很多意想不到的问题。例如,你可能会发现Agent 80%的时间都花在了处理依赖安装失败上,这提示你需要优化环境配置。或者发现它生成的测试用例对某个特定模块覆盖率始终很低,这可能是训练数据或提示词(Prompt)的问题。
4.2 阶段二:引入关键护栏与审批(“约束”你的Agent)
在有了可见性的基础上,针对高风险区域设置最基本的控制。
- 动作 :定义并实施3-5条核心安全策略。例如:
- 代码质量门禁 :任何Agent生成的代码,必须通过基础代码风格检查(如Prettier/Black格式化)才能被提交。
- 敏感操作审批 :任何涉及
DELETE操作、生产数据库变更、或修改核心认证逻辑的Agent行为,必须暂停并等待人工审批。 - 资源消耗限制 :单个Agent任务运行时间超过30分钟或消耗超过2GB内存,则自动终止。
- 产出 :一个初步的“安全网”。团队对使用Agent的信心会增强,因为知道它不会做出灾难性的行为。
4.3 阶段三:构建协同工作流(“编排”你的Agent)
当对单个Agent的管理得心应手后,可以尝试让多个Agent协作完成更复杂的任务。
- 动作 :设计一个简单的、线性的多Agent工作流。例如,一个“文档更新”工作流:
文档变更检测Agent->代码影响分析Agent->API文档同步Agent。 - 关键考量 :这个阶段的核心挑战是 定义清晰的Agent间接口和通信协议 。Agent A传递给Agent B的“上下文”应该是什么格式?是自然语言描述,还是结构化的JSON Schema?这需要仔细设计,通常建议采用结构化的数据契约,以减少歧义。
4.4 阶段四:全面融合与持续优化(“进化”你的系统)
将Keel深度融入团队的开发文化和工具链。
- 动作 :
- 将Keel的审批流程与团队的即时通讯工具(如Slack、钉钉)打通。
- 基于Keel收集的审计日志,定期进行复盘,优化Agent的提示词、工具集和工作流。
- 尝试更复杂的、带条件分支和循环的Agent工作流。
- 文化转变 :这个阶段不仅是技术集成,更是团队协作模式的转变。开发者需要习惯与AI Agent“共事”,并学会在Keel的界面上管理它们,就像管理一个实习生或初级工程师一样。
实操心得 : “从小处着手,快速迭代” 是成功的关键。切忌一开始就设计一个庞大无比的、涵盖所有可能场景的Keel平台。选择一个痛点明确、范围受限的场景(如“自动化生成API接口的单元测试”),快速实现从观测到控制的闭环,获取早期反馈和信任,再逐步扩大范围。工具链的集成(如与GitLab、Jenkins、K8s的对接)是工程量的重头,需要预留充足的时间。
5. 常见挑战、陷阱与应对策略
在实际引入和管理Agentic SDLC平台的过程中,你会遇到不少坑。以下是我总结的一些典型挑战及应对思路。
5.1 挑战一:“幻觉”与不可预测性
AI Agent基于大语言模型,天生具有“幻觉”(生成看似合理但错误或虚构的内容)和一定程度的不可预测性。
- 问题表现 :Agent生成了一段完全能编译通过但逻辑错误的代码;或者它“自信满满”地报告一个不存在的Bug。
- 应对策略 :
- 强化验证环节 :任何Agent生成的“产出物”(代码、配置、文档),都必须经过一个独立的、强制的验证步骤。这个验证可以是自动化的(如运行测试套件、静态分析),也可以是人工的(针对关键模块)。在Keel的工作流中,必须将“验证”作为一个独立节点。
- 设置置信度阈值与回退机制 :让Agent对其输出提供一个置信度分数。当分数低于某个阈值(如80%)时,工作流自动转入“人工处理”分支,或让另一个Agent进行交叉验证。
- 持续优化提示词与上下文 :Agent的不可预测性往往源于模糊的指令或不足的上下文。将每次失败的任务作为优化素材,持续迭代你的提示词工程和上下文提供策略。
5.2 挑战二:上下文管理与信息过载
随着任务复杂度和协作Agent数量的增加,如何有效地管理、传递和修剪上下文成为巨大挑战。
- 问题表现 :下游Agent因为收到了过多无关的上游信息而困惑,导致输出质量下降;或者因为缺少关键上下文而任务失败。
- 应对策略 :
- 设计上下文契约 :为每个任务类型明确定义其“输入上下文”和“输出上下文”的Schema。例如,一个“实现REST API”的任务,其输出上下文必须包含
endpoint_path,http_method,request_schema,response_schema等字段。使用JSON Schema等工具进行强类型约束。 - 实现上下文摘要与过滤 :在将上下文传递给下一个Agent前,可以使用一个轻量级的LLM来对冗长的上下文(如一大段代码文件)进行摘要,只提取与下游任务最相关的部分。或者,根据下游Agent的“能力描述”,自动过滤掉它不关心的信息。
- 建立共享知识库 :将常用的、稳定的信息(如项目架构图、编码规范、API目录)存入一个向量数据库,让Agent在需要时按需检索,而不是每次都全量传递。
- 设计上下文契约 :为每个任务类型明确定义其“输入上下文”和“输出上下文”的Schema。例如,一个“实现REST API”的任务,其输出上下文必须包含
5.3 挑战三:性能、成本与扩展性
Agent的每一步“思考”和工具调用都可能产生成本(API调用费用)和耗时。大规模应用时,成本和延迟可能失控。
- 问题表现 :一个简单的功能开发任务,因为Agent反复调用昂贵的GPT-4 API进行“深度思考”,导致成本高达数十美元,耗时数十分钟。
- 应对策略 :
- 分层模型策略 :并非所有步骤都需要最强大的模型。在Keel的策略中配置规则:规划阶段使用GPT-4以保证质量,简单的代码生成使用成本更低的Claude Haiku或本地模型,而格式检查、语法验证则使用完全免费的规则引擎。
- 缓存与复用 :对常见的、确定性的查询结果进行缓存。例如,Agent查询“项目当前的依赖列表”,这个结果在短时间内不会变化,可以缓存5分钟,避免重复调用包管理工具。
- 异步与批处理 :对于非实时性的任务(如夜间批量生成测试用例、代码重构建议),Keel可以将其排队,在资源空闲时批量处理,平滑负载。
- 细粒度监控与预算告警 :在Keel中集成成本监控,为每个Agent或每个项目设置API调用预算和告警阈值。当成本异常飙升时,自动暂停相关任务并通知管理员。
5.4 挑战四:安全与权限边界
赋予AI Agent操作代码库、基础设施的能力,无异于授予其高权限账户。安全漏洞可能导致严重后果。
- 问题表现 :Agent因提示词注入(Prompt Injection)被恶意引导,执行了删除数据、植入后门等操作;或者Agent的访问令牌泄露。
- 应对策略 :
- 最小权限原则 :为每个Agent分配仅能满足其功能需求的最小权限集。例如,一个只负责生成前端组件的Agent,不应该拥有后端数据库的写权限。在Keel中,这需要与团队的IAM(身份访问管理)系统深度集成。
- 输入净化与输出审查 :对所有来自外部的、可能影响Agent行为的输入(如用户需求描述、评论反馈)进行严格的净化和校验。对Agent生成的关键代码、命令,在执行前进行一轮基于规则的或简单AI的恶意代码扫描。
- 完整的审计溯源 :Keel的审计日志必须详尽且防篡改,确保任何事故发生后,都能清晰地回溯到是哪个Agent、在什么时间、基于什么指令、执行了什么操作。这是安全响应的基础。
- 定期安全演练 :像对待人类工程师一样,对AI Agent系统进行定期的渗透测试和安全审计,模拟攻击场景,检验防护措施的有效性。
引入Keel这样的平台,本质上是在管理一个由“数字员工”和人类员工组成的混合团队。它需要的不仅是技术架构,更是流程设计、风险管控和团队文化的全面升级。这条路充满挑战,但对于志在拥抱智能体时代、大幅提升研发效能的团队来说,这是一条必经之路。它让我们从繁琐、重复的流程性工作中解放出来,更专注于创造性的架构设计和复杂问题解决,而让AI去负责那些它们更擅长的、规则明确且需要大量重复劳动的执行环节。

这里是“一人公司”的成长家园。我们提供从产品曝光、技术变现到法律财税的全栈内容,并连接云服务、办公空间等稀缺资源,助你专注创造,无忧运营。
更多推荐

 5
5 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)