基于NeuroLink框架构建企业级Slack AI助手:从原型到生产的实战指南
1. 项目概述:从聊天机器人到生产力中枢的蜕变
最近我花了不少时间,把一个最初只是用来在Slack里查天气、讲笑话的“玩具”AI助手,打磨成了一个能真正处理复杂任务、融入团队工作流的“生产级”应用。这个项目的核心,是使用了一个名为NeuroLink的框架来构建。你可能没听过NeuroLink,这很正常,它不像LangChain或LlamaIndex那样声名显赫,更像是一个专注于“连接”与“编排”的后起之秀,特别适合处理从简单指令到多步骤工作流的复杂场景。
简单来说,这个项目就是 在Slack里造一个“超级员工” 。它不止能回答“公司年假政策是什么?”,更能理解“帮我把上周三销售会议的纪要总结一下,提取出行动项,并创建一个Jira任务分配给小李”这样的复合指令。从最初一个响应迟钝、时常“胡言乱语”的原型,到如今稳定、可靠、团队成员愿意主动依赖的生产力工具,中间踩过的坑、做出的架构抉择,远比代码本身更有价值。如果你也正尝试将生成式AI集成到像Slack、Teams这样的协作平台中,希望打造一个不只是“聊天”,而是能“做事”的智能体,那么我接下来的分享或许能帮你省下不少摸索的时间。
2. 核心架构与NeuroLink框架解析
2.1 为什么选择NeuroLink?一个编排优先的视角
在项目初期,我评估了市面上主流的几个框架。LangChain功能强大但略显臃肿,对于Slack这种以事件驱动为主的场景,其复杂的链式结构有时会引入不必要的开销。LlamaIndex在检索增强生成(RAG)上很出色,但我们的需求远不止文档问答。最终选择NeuroLink,是基于其几个鲜明的设计理念:
第一,事件驱动的智能体编排。 NeuroLink将每个用户交互视为一个“事件”,并围绕事件构建了一个清晰的生命周期:事件接收 -> 意图识别 -> 任务分解 -> 工具调用 -> 响应合成。这种模式与Slack的 Events API 天然契合。当用户在频道中 @ 你的助手时,Slack发送一个事件到你的服务端,NeuroLink能很自然地将其封装、路由到对应的处理流程。
第二,声明式的工具与技能管理。 在NeuroLink中,你不需要写冗长的代码来注册和描述一个工具(比如“查询数据库”或“调用外部API”)。它采用了一种近乎配置化的方式,让你用YAML或装饰器就能定义工具的输入、输出、描述以及错误处理方式。这使得团队中不同角色(比如产品经理)也能参与“技能”的定义,极大地提升了协作效率。
第三,内置的状态管理与上下文持久化。 这是从原型走向生产的关键。一个复杂的多轮对话(比如“帮我订会议室,并邀请项目组成员”),往往涉及多个步骤和中间状态。NeuroLink内置了一个轻量级的状态机,可以将会话状态(包括历史消息、已执行的操作、临时数据)与一个唯一的会话ID绑定,并支持持久化到Redis或数据库。这意味着即使用户中途离开,回来接着说“刚才那个会议,改成下午三点”,助手也能准确接上。
注意: 框架选择没有绝对的对错,更多是权衡。如果你的场景极度复杂,需要大量自定义逻辑,LangChain的灵活性可能更合适。但如果你追求快速构建一个结构清晰、易于维护、且专注于与外部系统(如Slack、Jira、CRM)集成的智能体,NeuroLink的“编排优先”思想会显得非常高效。
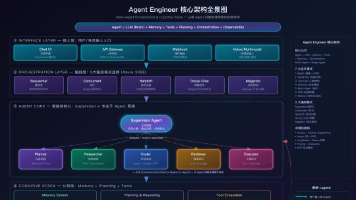
2.2 整体系统架构设计
我们的生产系统架构可以概括为以下几个核心组件,它们共同协作,将Slack的“消息”转化为“行动”:
-
Slack事件接收器(Event Receiver): 一个轻量的HTTP服务(使用FastAPI构建),专门接收来自Slack Events API的
url_verification、event_callback等请求。它的职责是验证请求签名(防止伪造)、解析事件类型(如app_mention,message),并将有效载荷快速转发给消息队列(我们用了Redis Streams,因其低延迟和简单性)。这一步的关键是 快速响应Slack (必须在3秒内返回200 OK),避免超时,所以所有耗时逻辑必须异步化。 -
异步消息处理器(Async Processor): 从Redis Streams中消费事件。这是NeuroLink智能体的主要入口。处理器根据事件中的频道ID、用户ID等信息,加载或创建对应的“会话”(Session)。然后,它将用户的消息文本和会话上下文,一并提交给NeuroLink的核心引擎。
-
NeuroLink智能体引擎(Agent Engine): 这是大脑。它接收用户输入,首先进行 意图识别(Intent Recognition) 。我们结合了规则匹配(针对高频、明确的指令如
/help)和一个微调的小型分类模型(用于理解更模糊的自然语言意图)。识别出意图后,引擎会从已注册的“技能”(Skills)库中,选取一个或多个来执行。NeuroLink负责管理这些技能的调用顺序、参数传递和结果整合。 -
技能库(Skills Registry): 这是智能体的“双手”。每个技能对应一个可执行的操作。例如:
SearchConfluenceSkill: 根据关键词搜索内部知识库。CreateJiraTicketSkill: 解析自然语言,填充Jira工单的标题、描述、负责人等字段并创建。SummarizeMeetingSkill: 接收一个会议录音文件ID,调用语音转文本服务,再调用大模型进行摘要。DataQuerySkill: 根据自然语言问题,生成SQL,查询数据仓库并返回可视化图表(通过生成图片链接)。 每个技能都通过NeuroLink的装饰器声明其所需的参数、权限和可能抛出的异常。
-
大模型服务与记忆层(LLM Service & Memory): 我们使用Azure OpenAI的GPT-4作为核心的“思考”模型。NeuroLink引擎在需要理解复杂指令、分解任务、或生成自然语言回复时,会调用此服务。 记忆层 至关重要,它由两部分组成:短期会话记忆(保存在Redis中,包含最近几轮对话)和长期向量记忆(使用Pinecone存储重要的对话结论、用户偏好等,供后续RAG检索)。
-
外部服务网关(External API Gateway): 一个统一的代理层,用于访问所有第三方服务(Jira, Salesforce, Google Calendar等)。它统一处理认证(OAuth令牌刷新)、请求重试、速率限制和日志记录,使得各个技能的实现更简洁、更专注于业务逻辑。
这个架构的核心思想是 解耦 和 异步化 。Slack事件接收器与核心业务逻辑解耦,通过消息队列通信;智能体引擎与具体的技能实现解耦;技能与复杂的外部API调用解耦。这保证了系统的可扩展性(新增技能很容易)和可靠性(一个技能失败不会导致整个请求崩溃)。
3. 从原型到生产的关键演进步骤
3.1 阶段一:快速验证原型的搭建
原型的目标只有一个: 用最短的时间证明想法可行,并收集用户最真实的反馈。 我们当时只做了三件事:
- 一个最简单的Flask应用 ,处理Slack的
/slash命令和@mention事件。 - 直接硬编码调用OpenAI API ,将用户消息原样发送,并将返回的文本直接贴回Slack。没有任何工具调用。
- 在提示词(Prompt)里简单描述 :“你是一个有帮助的Slack机器人,用简短友好的语气回答。”
这个“简陋”的原型上线后,我们邀请了一个小团队试用。几天内,我们就得到了几个关键洞察:
- 用户想要“做事”,而不是“聊天”。 最多的反馈是:“它能帮我查数据吗?”“能创建任务吗?”
- 上下文丢失是最大痛点。 用户说“把上面那个链接发给我”,机器人完全不知道“上面”指什么。
- 回复风格不稳定。 有时过于啰嗦,有时又太简略。
这个阶段,NeuroLink并未引入,因为过度工程化会拖慢验证速度。但我们已经明确了下一步需要强化的方向: 工具调用能力 和 上下文管理 。
3.2 阶段二:引入NeuroLink与核心技能开发
基于原型反馈,我们开始引入NeuroLink,并围绕两个最高优先级的技能进行开发: 信息检索 和 任务创建 。
3.2.1 构建第一个生产级技能:智能文档检索
单纯的RAG(检索增强生成)在Slack中体验不佳,因为用户可能问“我们项目的Q3目标是什么?”,而你的知识库里有十份相关文档。我们需要的是 精准检索+智能摘要 。
# NeuroLink 技能定义示例 (YAML格式)
skills:
- name: search_and_summarize
description: 从知识库中搜索与问题相关的文档,并生成一个简洁、准确的摘要。
parameters:
- name: query
type: string
description: 用户的搜索问题
- name: channel_id
type: string
description: Slack频道ID,用于权限过滤
steps:
- step: retrieve
action: vector_search
config:
index: confluence_pages
top_k: 5
filter: {"read_access": "{{channel_id}}"}
- step: rerank
action: cross_encoder_rerank # 使用交叉编码器对检索结果重排序,比简单向量相似度更准
config:
model: ms-marco-MiniLM-L-6-v2
- step: generate
action: llm_call
config:
prompt_template: |
基于以下文档片段,回答用户的问题。如果文档中没有足够信息,请明确说“根据现有资料无法找到相关信息”。
问题:{{query}}
文档:
{{#context}}
[{{index}}] {{content}}
{{/context}}
请给出直接、准确的答案,并注明来源文档的标题。
model: gpt-4-turbo
这个技能的实现,让我们意识到几个关键点:
- 权限过滤是必须的。 必须根据用户所在的Slack频道或用户组,动态过滤其可访问的文档,这是企业级应用的安全基线。
- 重排序(Reranking)大幅提升精度。 仅靠余弦相似度的向量检索,前三名结果可能都不相关。加入一个轻量级的重排序模型(如Cross-Encoder),能显著改善最终答案的质量。
- 引用来源至关重要。 在Slack回复中,必须附上答案所依据的文档标题和链接,这建立了信任,也方便用户追溯。
3.2.2 构建第二个技能:自然语言创建Jira任务
这是将自然语言转化为结构化动作的典型场景。难点在于 信息抽取的鲁棒性 。
# Python代码示例:使用Pydantic和NeuroLink装饰器定义技能
from neurolink import skill, SkillContext
from pydantic import BaseModel, Field
from typing import Optional
from .jira_client import JiraClient
class CreateJiraTicketInput(BaseModel):
description: str = Field(..., description="用户关于创建任务的原始描述")
project_key: Optional[str] = Field(None, description="Jira项目键,如'PROJ'")
@skill(
name="create_jira_ticket",
description="根据用户的自然语言描述,创建一张Jira任务工单。",
input_model=CreateJiraTicketInput
)
async def create_jira_ticket_skill(input_data: CreateJiraTicketInput, ctx: SkillContext):
"""
核心逻辑:
1. 使用LLM从自然语言描述中提取结构化字段(标题、描述、负责人、优先级、截止日期)。
2. 如果用户未指定项目,根据频道历史或默认规则推断。
3. 调用Jira API创建工单。
4. 返回创建成功的工单链接和关键信息。
"""
# 步骤1: 信息提取
extraction_prompt = f"""
你是一个Jira工单信息提取专家。从以下用户描述中提取信息:
描述:{input_data.description}
请以JSON格式返回,包含以下字段:
- summary: 工单标题(简洁明了)
- description: 详细描述(可包含用户原话)
- assignee: 负责人(邮箱前缀,如无则null)
- priority: 优先级('Highest', 'High', 'Medium', 'Low', 'Lowest',如无则'Medium')
- due_date: 截止日期(YYYY-MM-DD格式,如无则null)
"""
extracted_data = await ctx.llm_call(extraction_prompt, response_format="json_object")
# 步骤2: 项目推断(逻辑略)
project_to_use = input_data.project_key or infer_project(ctx.session)
# 步骤3: 调用Jira客户端(封装了重试、错误处理)
jira = JiraClient(ctx.config)
try:
ticket_key, ticket_url = await jira.create_issue(
project=project_to_use,
**extracted_data
)
return {
"success": True,
"message": f"已创建工单 {ticket_key}:{extracted_data['summary']}",
"ticket_url": ticket_url
}
except Exception as e:
ctx.logger.error(f"创建Jira工单失败: {e}")
# NeuroLink允许技能返回错误状态,引擎会进行统一处理(如告知用户失败,并提示重试)
return {
"success": False,
"error": "创建任务时遇到系统错误,请稍后重试或联系管理员。"
}
这个技能的开发让我们收获了宝贵的经验:
- 使用Pydantic进行强类型验证 ,在技能输入阶段就拦截掉格式错误,比在运行时解析字符串安全得多。
- LLM用于信息提取,而非直接执行。 让LLM做它擅长的事(理解自然语言并结构化),而让稳定的代码去执行具体的API调用。这种模式比让LLM直接生成API调用代码要可靠得多。
- 统一的错误处理与用户反馈。 技能内部捕获异常,返回结构化的结果(成功/失败),由NeuroLink引擎决定如何向用户呈现。这保证了即使用户描述模糊导致创建失败,也能得到一个友好的、可操作的错误提示,而不是机器人“沉默”或崩溃。
3.3 阶段三:状态管理、多轮对话与生产部署
当单个技能运行良好后,复杂的需求自然就来了: “帮我把昨天产品评审会的纪要,总结出三个要点,并分别创建Jira任务。” 这涉及多个技能的串联和中间状态的维护。
3.3.1 实现多步骤工作流
NeuroLink的“工作流”(Workflow)概念在这里派上用场。我们可以将上述复杂指令定义为一个工作流:
workflows:
- name: summarize_and_create_tasks
description: 总结会议纪要并创建相关任务。
triggers:
- intent: meeting_summary_to_tasks
steps:
- step: find_meeting_notes
skill: search_confluence
with:
query: "{{session.last_message}} 会议纪要"
max_results: 1
save_output_as: meeting_doc
- step: generate_summary
skill: llm_generate
with:
prompt: |
请总结以下会议纪要,提取出关键决策和行动项(Action Items)。
纪要内容:
{{steps.find_meeting_notes.output.content}}
model: gpt-4
save_output_as: meeting_summary
- step: extract_action_items
skill: llm_extract_structured
with:
input: "{{steps.generate_summary.output}}"
schema: |
[{"item_description": "string", "assignee_suggestion": "string"}]
save_output_as: action_items
- step: create_tasks_loop
for_each: "{{steps.extract_action_items.output}}"
skill: create_jira_ticket
with:
description: "{{item.item_description}} (来自会议总结)"
assignee: "{{resolve_assignee(item.assignee_suggestion)}}" # 调用一个自定义函数解析负责人
这个工作流清晰定义了步骤间的依赖关系和数据流。NeuroLink引擎会按顺序执行,并将每一步的输出(如 meeting_summary )保存到会话状态中,供后续步骤使用。 for_each 循环则优雅地处理了为每个行动项创建任务的需求。
3.3.2 生产环境部署与监控
将原型部署到生产环境,意味着对可靠性、性能和可观测性有极高要求。
- 部署架构: 我们使用Docker容器化所有服务,在Kubernetes上运行。Slack事件接收器(无状态)可以水平扩展以应对流量高峰。NeuroLink智能体引擎(有状态,因为关联会话)则采用固定数量的Pod,并通过Redis共享会话状态,从而实现一定程度的容错和扩展。
- 监控与日志: 这是生产的“眼睛”。我们做了三件事:
- 全链路追踪: 为每个Slack事件分配一个唯一的
trace_id,并贯穿整个处理流程(事件接收器 -> 消息队列 -> 智能体引擎 -> 各个技能 -> 外部API)。使用OpenTelemetry将追踪数据发送到Jaeger,任何环节的延迟或错误都能快速定位。 - 结构化日志: 所有日志都输出为JSON格式,包含
trace_id、user_id、channel_id、skill_name等关键字段。这方便我们使用ELK栈(Elasticsearch, Logstash, Kibana)进行聚合分析和告警。例如,可以设置当create_jira_ticket技能的错误率在5分钟内超过2%时触发告警。 - 关键指标(Metrics): 使用Prometheus收集指标,如:每秒请求数、各技能的平均响应时间与错误率、LLM调用的Token消耗与成本、会话活跃数等。这些指标是进行容量规划和成本优化的基础。
- 全链路追踪: 为每个Slack事件分配一个唯一的
- 速率限制与降级: 我们对LLM API的调用做了严格的速率限制和队列管理,防止因突发流量或某个技能循环调用导致成本激增。当LLM服务暂时不可用时,智能体会优雅降级,回复“思考服务暂时繁忙,您可以稍后再试,或直接描述您想完成的任务,我会记录下来”。
4. 避坑指南与性能优化实战
4.1 五个最常见的“坑”及其解决方案
-
Slack事件重复与乱序: Slack为了保证送达,可能会重发事件。如果你的处理不是幂等的,就可能创建重复的Jira任务或发送重复消息。
- 解决方案: 在事件接收器层,对每个事件的
event_id和event_time进行去重检查(利用Redis Set,设置一个合理的过期时间,如60秒)。确保核心的业务逻辑(如技能执行)是幂等的,例如,创建Jira任务前先检查是否已存在类似标题的任务。
- 解决方案: 在事件接收器层,对每个事件的
-
LLM上下文窗口的浪费与溢出: 盲目地将整个对话历史塞给LLM,既浪费Token(增加成本与延迟),又可能因超出上下文限制导致模型“失忆”。
- 解决方案: 实现 智能上下文窗口管理 。只保留最近N轮对话(例如5轮)作为“短期记忆”。对于更早但可能相关的内容,将其关键信息(通过LLM提取实体或摘要)存入向量数据库。当新问题到来时,先进行向量检索,将检索到的“长期记忆”片段与“短期记忆”一起作为上下文。这大大减少了Token消耗,并提升了历史信息的利用效率。
-
工具调用中的“幻觉”与参数错误: LLM在决定调用哪个工具、填充什么参数时,可能会“捏造”一个不存在的工具,或生成格式错误的参数。
- 解决方案: 严格的模式验证(Schema Validation) 。NeuroLink允许为每个工具定义严格的输入JSON Schema。在LLM生成工具调用请求后,必须先用JSON Schema验证其格式。如果验证失败,不是直接报错给用户,而是将错误信息反馈给LLM,要求它修正。这形成了一个“自我修正”的循环,大幅提高了工具调用的成功率。
-
外部API的延迟与失败拖累整体响应: 如果“查询天气”和“创建CRM商机”这两个技能在一个工作流中同步执行,前者很快(100ms),后者很慢(5s),那么用户需要等待5秒才能得到回复,体验很差。
- 解决方案: 异步技能执行与渐进式反馈 。对于耗时长(>2秒)或可能失败的外部调用,将其设计为异步技能。NeuroLink引擎可以先快速回复用户:“正在为您创建商机,请稍候...”,同时在后台触发异步任务。任务完成后,通过Slack的
response_url或直接发送消息到频道/私信,将结果告知用户。这完全改变了交互体验。
- 解决方案: 异步技能执行与渐进式反馈 。对于耗时长(>2秒)或可能失败的外部调用,将其设计为异步技能。NeuroLink引擎可以先快速回复用户:“正在为您创建商机,请稍候...”,同时在后台触发异步任务。任务完成后,通过Slack的
-
提示词(Prompt)的脆弱性: 一个在测试中表现良好的提示词,可能因为生产数据分布的不同而突然失效。
- 解决方案: 将提示词外部化与版本化 。不要将提示词硬编码在代码里。将其存储在数据库或配置文件中,并为每个提示词分配版本号。这样,你可以随时在不重启服务的情况下,动态调整、测试和回滚提示词。我们甚至建立了一个简单的内部界面,让产品经理可以基于少量样本数据(脱敏后)测试不同提示词的效果。
4.2 性能优化:让助手“快”起来
在生产环境中,用户对延迟的容忍度很低。我们的目标是 绝大多数请求在3秒内完成 。以下是几个关键的优化点:
- 向量检索优化: 这是RAG场景的常见瓶颈。我们做了两件事:一是对文档进行 更精细的分块(Chunking) ,并叠加滑动窗口,确保上下文完整性;二是为向量索引 启用HNSW(Hierarchical Navigable Small World)算法 ,这是一种近似最近邻搜索算法,在精度损失极小的情况下,能带来数十倍的检索速度提升。
- LLM调用优化:
- 缓存(Caching): 对频繁出现的、结果确定的查询进行缓存。例如,“公司总部地址是什么?”这种问题,答案几乎不变。我们使用Redis缓存LLM的输入和输出(以Prompt的哈希值为Key),缓存命中时直接返回,绕过LLM调用,响应时间从秒级降到毫秒级。
- 流式响应(Streaming): 对于需要LLM生成较长文本的回答,启用流式响应。NeuroLink支持将LLM返回的Token逐个推送到Slack,让用户看到“打字中...”的效果,这从感知上极大地提升了响应速度。
- 模型分级使用: 并非所有任务都需要GPT-4。对于简单的分类、信息提取任务,我们使用更小、更快的模型(如GPT-3.5 Turbo或微调的Claude Haiku)。通过一个路由层,根据任务的复杂度自动选择模型,在保证效果的同时降低成本与延迟。
- 会话状态存储优化: 会话状态频繁读写,必须低延迟。我们将会话状态存储在Redis中,但并非所有数据都全量存储。我们将状态分为“热数据”(当前对话轮次、临时变量)和“冷数据”(完整对话历史)。热数据存于Redis,冷数据定期归档到数据库。同时,为每个会话状态设置合理的TTL(生存时间),例如闲置24小时后自动清理,防止内存无限增长。
5. 安全、权限与成本控制
5.1 构建企业级安全防线
在Slack这样的企业环境中部署AI助手,安全是重中之重。
- 最小权限原则: 助手申请的Slack OAuth权限范围必须精确,只请求它完成功能所必需的最少权限(例如,
channels:history用于读取频道消息,chat:write用于发送消息)。同样,访问Jira、Confluence等外部系统的服务账号,其权限也被严格限定。 - 用户身份与权限传导: 助手不能以一个“超级管理员”的身份行事。它执行操作时,必须 代表触发它的用户 。例如,当用户A要求创建Jira任务时,助手应使用用户A的Jira访问令牌(或映射的服务账号)来创建,这样任务的责任人、可见性都符合用户A自身的权限。我们在NeuroLink的会话上下文中,始终绑定了
user_id,并在调用下游API时传递此信息。 - 输入输出审查与过滤: 所有用户输入在传递给LLM之前,都经过一层简单的敏感信息过滤(如尝试检测并脱敏信用卡号、身份证号等模式)。LLM的输出在发送回Slack前,也会进行二次检查,防止模型被“越狱”后生成不当内容。虽然不能100%杜绝,但这是一个必要的防御层。
- 审计日志: 所有助手执行的操作,尤其是创建、修改、删除等写操作,都必须记录详尽的审计日志,包括操作时间、用户、触发的技能、输入参数、输出结果等。这些日志存储在安全的、仅审计员可访问的存储中,满足合规要求。
5.2 精细化成本控制策略
使用大模型,成本是绕不开的话题。如果不加控制,一个活跃的助手每月可能产生惊人的API调用费用。
- 预算与配额管理: 我们为整个应用设置了每日、每月的Token消耗预算。在NeuroLink引擎调用LLM之前,会先检查当前周期内的消耗是否已超预算。同时,我们甚至为不同的Slack频道或用户组设置了软性配额,防止个别团队过度使用。
- 成本归属与展示: 在管理后台,我们提供了一个仪表板,清晰地展示成本按技能、按频道、按用户的分布情况。这让各个团队对自己的使用情况有直观认识,也能促使他们更有效地使用助手(例如,用更精确的提问来减少不必要的Token消耗)。
- 优化提示词与减少冗余: 通过分析日志,我们发现很多提示词中存在不必要的“礼貌用语”或重复的系统指令。我们发起了一次“提示词瘦身”行动,在保证效果的前提下,精简了所有常用提示词,平均减少了约15%的输入Token。积少成多,这是一笔可观的节省。
从最初一个简单的聊天回复原型,到今天这个能够理解复杂意图、安全可靠地调用多种工具、并融入团队核心工作流的Slack AI助手,NeuroLink框架提供的清晰编排能力和状态管理机制起到了关键作用。这个过程让我深刻体会到,构建生产级AI应用,技术选型只是起点,真正的挑战在于对细节的打磨:如何设计鲁棒的错误处理、如何管理状态与上下文、如何保障安全与权限、如何控制成本与性能。每一个决策都影响着最终用户的体验和信任。现在,团队已经习惯在Slack里向助手提问、派发任务,它不再是一个新奇玩具,而是一个沉默而高效的数字同事。

这里是“一人公司”的成长家园。我们提供从产品曝光、技术变现到法律财税的全栈内容,并连接云服务、办公空间等稀缺资源,助你专注创造,无忧运营。
更多推荐


 8
8 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)