中国AI编程反超GPT‑5,Kimi K2 Thinking成为榜一大哥!
大家好,我是羊仔,专注AI编程、智能体、AI工具。
Kimi K2 Thinking太能打了,这或许是开源界第一次正面干翻GPT‑5的模型。

一、榜一大哥降临
过去几年,大家都默认:真正顶尖的模型,比如 GPT‑5、Claude,要么贵、要么闭源。
而开源模型,更多是平替,够用,但不惊艳。
直到 Kimi K2 Thinking 出现。
它在各大榜单上,直接扎进全球第一阵营:
-
在Humanity’s Last Exam(人类最后的考试)里,拿下 44.9 分,超 GPT‑5 和 Claude 4.5 Sonnet。
-
在BrowseComp(自主搜索基准)上,直接翻倍人类评分。
-
在SWE‑Bench、LiveCodeBench等编程测试中,也是世界前几名。
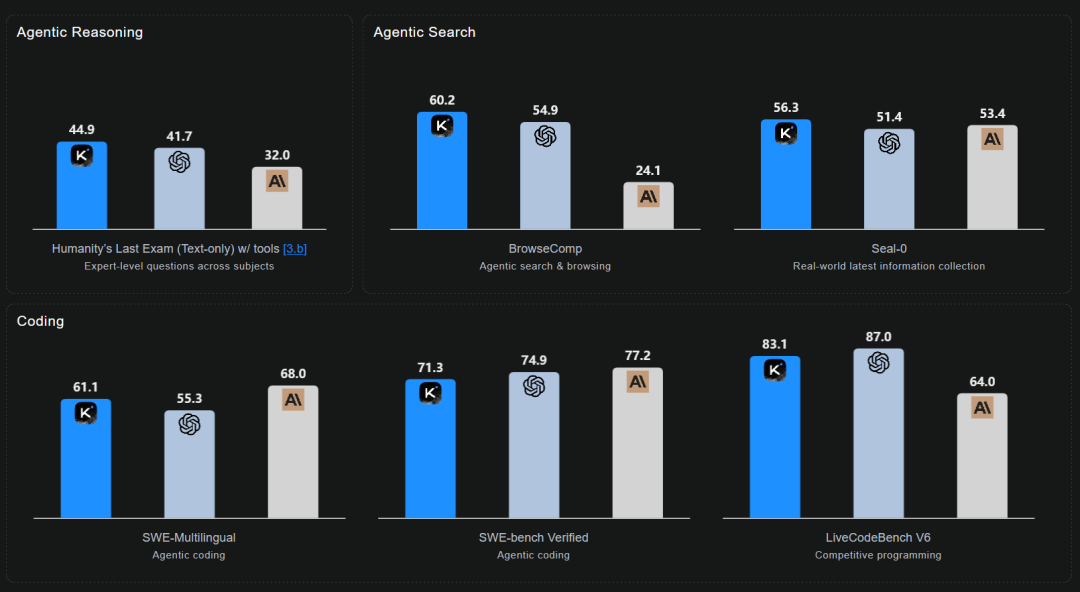
这是开源模型第一次硬刚闭源王者并赢了。
而最牛的是,它跑这些分时用的,还是INT4 量化版本。
也就说,它不是「实验室满血模式」,而是「出厂即实测」,没有开特权。
二、到底厉害在哪
表面上看,K2 Thinking 是个 MoE(混合专家)的大模型:
-
总参数 1T
-
激活参数 32B
-
上下文长达 256K
但真正厉害的,不在这里。
它的核心,是Thinking + Agent 双核运行机制。

说人话:
它不是等你一句话就直接回答,而是先想、再查、再试、再总结。
这一整套「思考 → 搜索 → 工具调用 → 验证 → 再思考」的流程,全程自动。
官方说它能一口气调用 200–300 次工具,我实测的时候也能看出雏形,比如羊仔让它写个天气小卡片:
1. 它先联网查了实时气象 API,
2. 再搜索一些当前流行的天气卡片设计灵感,
3. 最后自动写出 HTML + JS 代码一站搞定。
这时你就能感受到,它不是 GPT 那种「我给你讲原理」,而是真的会动手的 AI。
三、优雅的架构,不堆算力
过去 AI 的进化逻辑是:更大 → 更贵 → 更强。
但羊仔在看 K2 Thinking 的技术论文时,发现它在玩一条完全不同的路线:
它用的是叫做测试时扩展(Test‑Time Scaling)的新框架。
意思是:
不靠训练堆料,而是让模型在「使用时」分配更多思考token和工具调用步数。
于是,当别的模型靠 brute‑force 来解题时,K2 可以边想边查资料。
这就解释了它为什么能在Humanity’s Last Exam那种上千道高难学术题里,拿到最高分。

四、开源的野心:不是模仿,是共建
羊仔特别喜欢 Kimi 团队在开源模式上的那种「不怕比」的态度:
他们不只与开源比,而是直接把 GPT‑5、Claude 一起拉上榜单对决。
他们的逻辑是,如果闭源代表了「工业级极限」,那开源就要代表「全民级可得」。
你今天就能在 kimi.com 上用上 K2 Thinking。
API 版、网页版,甚至手机端都同步上线。
虽然为了速度,他们目前做了部分工具调用限制,但完整的 Agent 模式也已在路上了。

五、羊仔说:从追赶到改写
几年前我们还在讨论“国产能否平替”。
现在,K2 Thinking 已经在改写标准。
它让「开源 = 不如」这个公式失效,它证明了靠更优雅的架构设计,也能超越单纯的算力堆叠。
它还没完美,但它充满生命力。
这不是终点,只是开源智能体时代的序章。
共勉!
欢迎关注羊仔,一起探索AI,成为超级个体!
如果你喜欢这篇文章,不妨点赞,在看,转发。
你的每一次互动,对羊仔来说都是莫大的鼓励。

这里是“一人公司”的成长家园。我们提供从产品曝光、技术变现到法律财税的全栈内容,并连接云服务、办公空间等稀缺资源,助你专注创造,无忧运营。
更多推荐

 3
3 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)