Claude Sonnet 4.0 到 4.5:写作能力的工程级变化与实践选型分析
在实际使用大模型辅助写作的过程中,很多人会发现一个现象:
模型在第一次输出时表现尚可,但随着写作任务变长、轮次变多,质量开始出现波动。
在持续使用 Claude Sonnet 4.0 与 4.5 辅助完成技术文档、长文内容和复杂写作任务后,一个结论逐渐清晰:
Claude 4.5 的提升并不是“写得更像人”,而是更接近一种“工程级可持续写作能力”。
本文基于长期实操体验,并结合 Anthropic 公布的能力指标,从模型的日常写作使用场景出发,系统分析 Claude Sonnet 4.0 与 4.5 在写作任务中的能力差异,并给出更符合工程现实的选型建议。
一、模型写作场景的日常表现拆解
在日常使用大模型进行写作时,模型往往会被反复投入到以下几类高频场景中:
-
连续输出型写作:围绕同一主题,分多次生成内容,例如系列文章、多章节文档、连载式输出;
-
结构化写作:需要模型先构建整体结构,再逐段补全内容,且前后逻辑必须严格一致;
-
上下文依赖型写作:后续内容必须承接前文定义的概念、变量或设定,不能前后矛盾;
-
长时间会话写作:在数小时甚至跨会话的写作过程中,模型需要“记住”已经完成的内容,避免重复或跑偏。
这些使用方式有一个共同点:
模型不再只是一次性生成工具,而是被当作长期协作的写作参与者。
在这种前提下,模型是否具备稳定的上下文保持能力、结构感知能力和长期一致性,往往比单次输出的文笔好坏更重要。
二、真实痛点:为什么内容会“越写越难维护”?
在上述写作模式下,常见问题会逐步显现:
-
上下文逐渐失效
前文定义的概念,在后文被弱化、重复解释,甚至直接遗忘。 -
结构松散
内容在多轮生成后失去统一结构,同一主题被反复从不同角度描述。 -
逻辑链断裂
早期提出的问题或设定,在后续内容中无法自然回收。 -
人工校对成本上升
需要反复回看前文,人工检查是否存在自相矛盾的描述。
这些问题并不完全源于 Prompt 编写方式,而更多来自模型在长期写作任务中的能力边界。
三、核心能力对比:Claude Sonnet 4.0 与 4.5 的写作差异
从写作与工程输出视角,对两代模型的关键能力进行对比((满分 10 分,基于实操体验与公开指标综合评估):
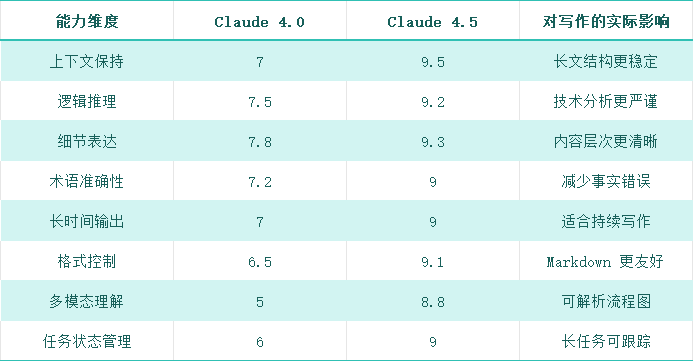
整体结论是:
-
Claude 4.0 更适合短文、草稿、灵感阶段;
-
Claude 4.5 在持续性、结构化与工程逻辑方面明显更强。
四、实战表现:技术写作场景下的差异体现
以一个典型技术写作任务为例(如缓存穿透解决方案分析):
Claude 4.0 的常见表现:
-
能列出常见方案
-
原理描述相对简略
-
缺乏参数选择依据和工程注意事项
Claude 4.5 的表现更偏工程化:
-
自动按「问题 → 原理 → 实现 → 注意事项」分层组织内容
-
补充复杂度分析与适用场景
-
给出可直接使用的示例代码
示例对比:
-
4.0:
布隆过滤器可以解决缓存穿透问题,通过哈希函数映射数据。
-
4.5:
在高并发场景下,布隆过滤器常用于减少无效请求对缓存和数据库的冲击。其核心在于通过多个哈希函数将元素映射到位数组中,实际使用时需根据数据规模计算位数组长度与哈希函数数量,避免误判率过高带来的业务风险。
在多轮写作中,这种差异会不断累积,最终显著影响整体内容质量。
五、实操技巧:如何在不同版本中获得稳定输出?
使用 Claude 4.0 时:
-
将长文拆分为独立章节
-
在每一轮生成中重复核心定义
-
使用示例约束输出风格,减少漂移
使用 Claude 4.5 时:
-
一次性提供完整大纲或设定
-
明确结构化输出要求
-
利用其长上下文能力完成整体写作
核心原则是:
不要用短测试决定长期写作方案。
六、选型与成本:工程现实下的折中解法
在实际工程中,更合理的做法通常是:
-
按写作阶段使用不同模型
-
将模型切换的复杂度下沉到 API 接入层
不少团队会选择通过 POLOAPI(poloapi.cn) 统一接入不同版本模型,在同一接口规范下灵活切换能力,从而在稳定性、效率与成本之间取得平衡,并降低工程维护复杂度。
七、总结
Claude Sonnet 4.5 的核心价值,并不在于“写得更华丽”,而在于:
-
能长期保持结构一致性
-
能按工程逻辑拆解复杂主题
-
能显著降低人工返工与校对成本
在模型快速演进的背景下,理解模型能力边界,并设计合理的使用方式,往往比单纯追求“更强的模型”更符合工程现实。

这里是“一人公司”的成长家园。我们提供从产品曝光、技术变现到法律财税的全栈内容,并连接云服务、办公空间等稀缺资源,助你专注创造,无忧运营。
更多推荐


 14
14 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)