Springboot+langchain4j的RAG检索增强生成
·
最终传递给构造器一个由springboot自动管理的自己配置的Bean容器即可
.contentRetriever(contentRetriever)
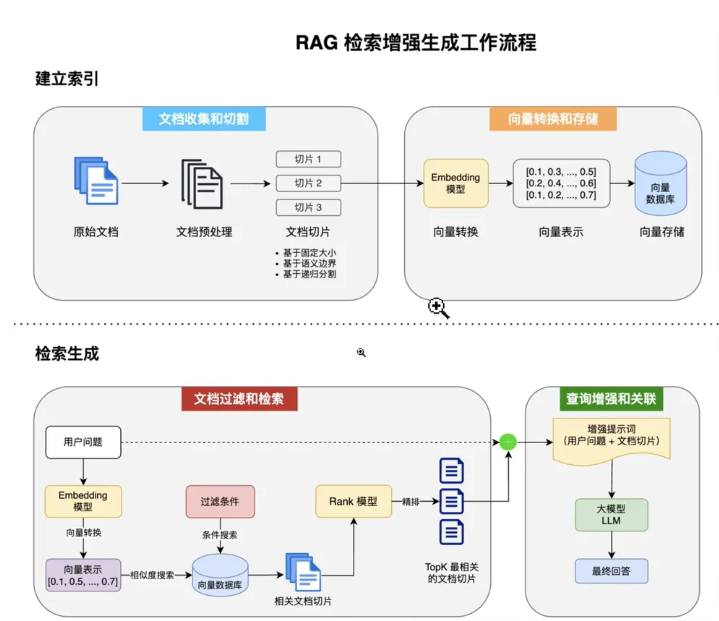
,所有的努力都是为了这个CR,作用是从你的文档知识库中获取到与你提问最相符的一个文档片段,其中包括了把文档切片,变成向量存入数据库中,把用户的问题通过Embedding模型进行向量转化,与文档向量进行相似度匹配,过滤,放入Rank模型,排出123来
@Configuration
public class RagConfig {
@Resource
private EmbeddingModel qwenEmbeddingModel;
@Bean
public EmbeddingStore<TextSegment> embeddingStore() {
// 这里使用内存存储,重启后数据会丢失。
// 如果需要持久化,后续可以换成 Chroma, Milvus, PGVector 等
return new InMemoryEmbeddingStore<>();
}
@Bean
public ContentRetriever contentRetriever(EmbeddingStore<TextSegment> embeddingStore){
//加载文档
List<Document> documents = FileSystemDocumentLoader.loadDocuments("src/main/resources/doc");
//文档切割器
DocumentByParagraphSplitter documentByParagraphSplitter =
new DocumentByParagraphSplitter(1000, 200);
//文档加载器
EmbeddingStoreIngestor ingestor = EmbeddingStoreIngestor.builder()
.documentSplitter(documentByParagraphSplitter)
.embeddingModel(qwenEmbeddingModel)
.textSegmentTransformer(textSegment -> TextSegment.from(
textSegment.metadata().getString("file_name")
+ '\n' + textSegment.text(), textSegment.metadata()))
.embeddingStore(embeddingStore)
.build();
//加载文档
ingestor.ingest(documents);
//存到向量数据库中:
return EmbeddingStoreContentRetriever.builder()
.embeddingStore(embeddingStore)
.embeddingModel(qwenEmbeddingModel)
.maxResults(5) //检索五条
.minScore(0.75) //匹配度
.build();
}
}

这里是“一人公司”的成长家园。我们提供从产品曝光、技术变现到法律财税的全栈内容,并连接云服务、办公空间等稀缺资源,助你专注创造,无忧运营。
更多推荐

 1
1 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)