多模态文档解析开源新进展-DeepSeek-OCR2.0架构、数据、训练方法
DeepSeek-OCR2.0是DeepSeek-OCR(《端到端的多模态文档解析模型-DeepSeek-OCR架构、数据、训练方法》)的后续,其是一个端到端的多模态文档解析模型,也是Vary、GOT-OCR2.0的后续,前期也有详细介绍《【多模态&文档智能】OCR-free感知多模态大模型技术链路及训练数据细节》。DeepSeek-OCR 2 对上一代的优化主要是编码器上的改进,如下图:用 LLM 式架构替换了 DeepEncoder 中的 CLIP 模块。通过定制化注意力掩码,视觉 token 采用双向注意力机制,而可学习查询则采用因果注意力机制。因此,每个查询 token 既能关注所有视觉 token,也能关注之前的查询,从而实现对视觉信息的渐进式因果重排序,初步验证了LLM-style 架构作为 VLM 编码器的可行性。
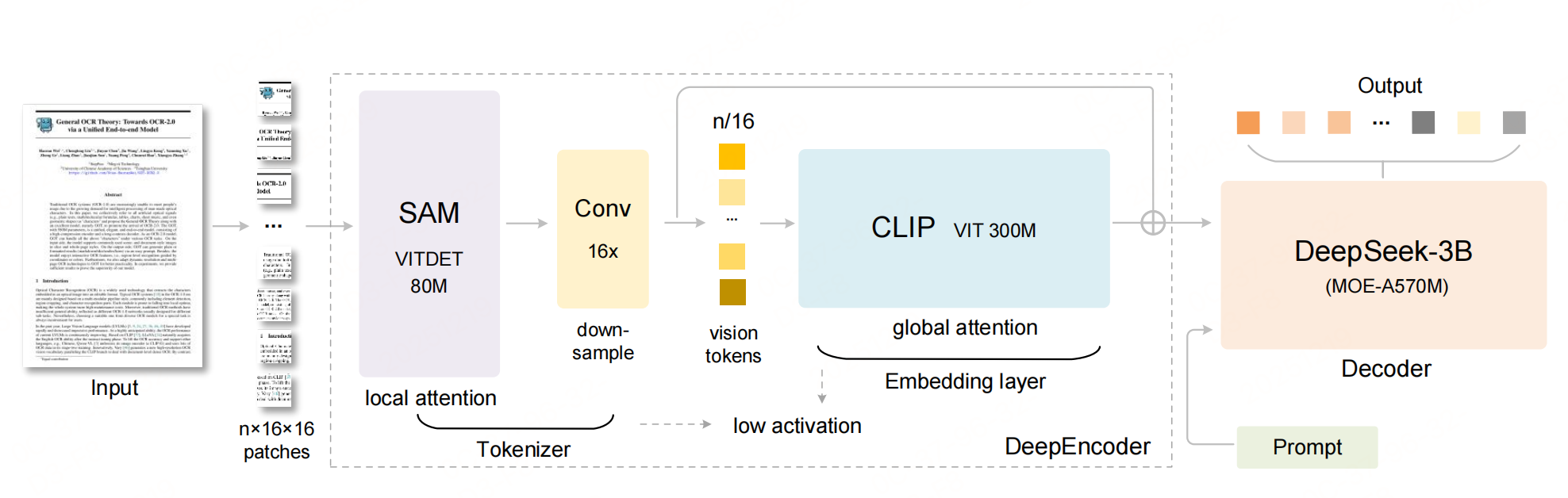
模型架构
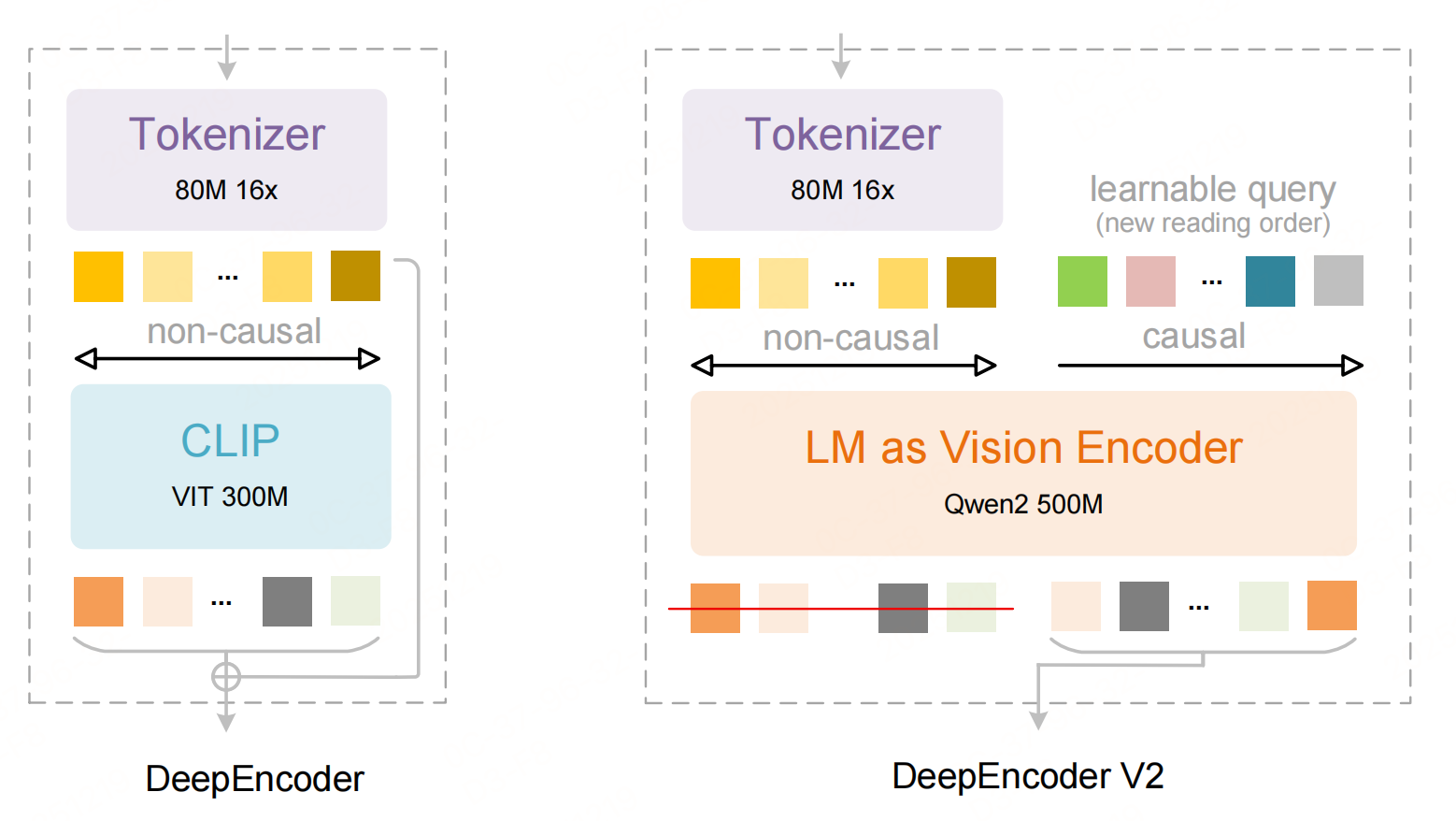
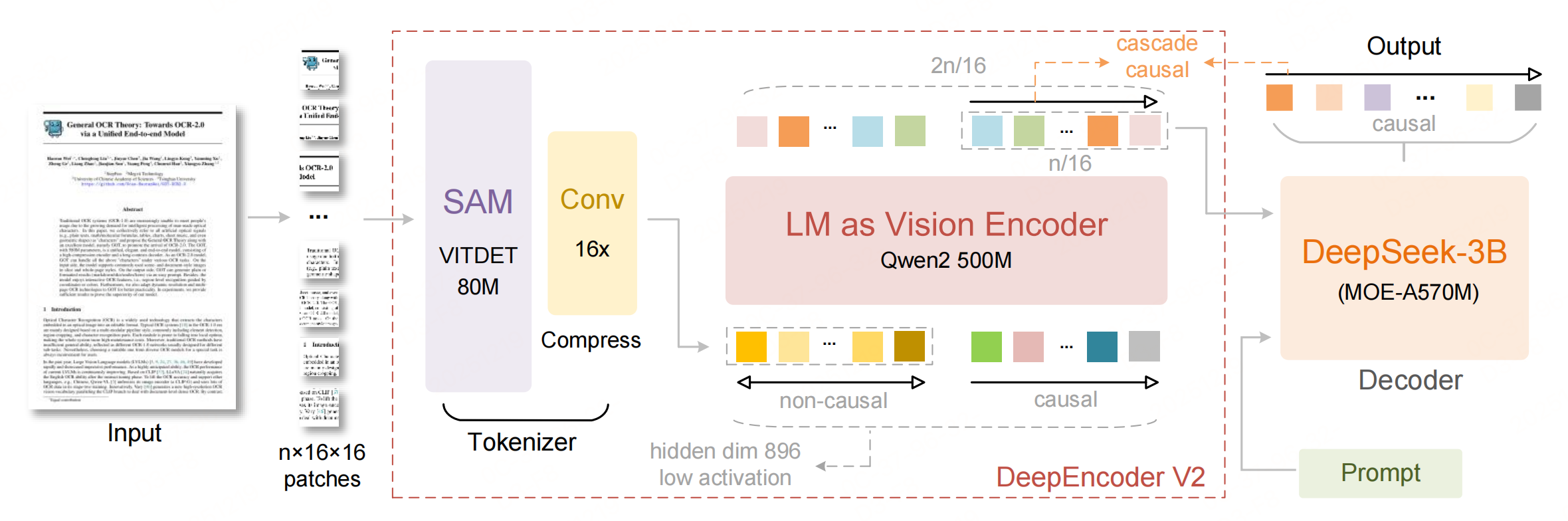
DeepSeek-OCR 2 继承了 DeepSeek-OCR 的【编码器-解码器】架构,但对核心的编码器进行了升级(DeepEncoder → DeepEncoder V2),解码器不变:
- 编码器(DeepEncoder V2):在DeepEncoder V1中,DeepEncoder专门解决现有VLMs视觉编码器(如Vary、InternVL2.0)的痛点:高分辨率输入时token过多、激活内存大、不支持多分辨率。DeepEncoder V2在功能上仍然继承了DeepEncoder V1,但引入了【图像离散化+语义重排序】——将输入图像转化为视觉token,并通过因果推理机制按图像语义重新排列token顺序,而非固定的“左上到右下”栅格顺序。
- 解码器(DeepSeek-MoE Decoder):基于重新排序后的视觉token和文本提示(Prompt),生成最终的OCR输出(文本、公式、表格等内容)。
DeepEncoder V2
DeepEncoder V2 是核心改进,下面具体看下各个组件:
1 Vision tokenizer
沿用 DeepEncoder 的基础结构,由【80M参数的 SAM-base 模型 + 两层卷积层】组成。有一点细微的改动:
- 输出维度调整:最终卷积层的输出维度从 DeepEncoder 的 1024 降至 896,适配LLM-style 编码器输入维度。
- 16倍token压缩比:通过窗口注意力(window attention)实现,在仅用80M参数的情况下,将图像patch压缩16倍,大幅降低后续全局注意力模块的计算成本和激活内存。
2 Language model as vision encoder
用紧凑LLM架构替换初代 DeepEncoder 中的 CLIP ViT 模块,实现“视觉因果建模”。
采用 Qwen2-0.5B(500M参数)作为视觉编码器,参数规模与 CLIP ViT(300M)接近,无额外计算开销。
- 双流注意力机制:
- 视觉token流:采用双向注意力(类似ViT),保留CLIP的全局建模能力(每个视觉token可关注所有其他视觉token)。
- 因果流查询(causal flow tokens):采用「因果注意力」(类似LLM解码器),新增的可学习查询(learnable queries)被作为“后缀”拼接在视觉token之后,每个查询仅能关注【所有视觉token + 之前的查询】,实现渐进式的token重排序。
仅将因果流查询的输出(编码器输出的后n个token)传入LLM解码器,视觉token不直接参与后续解码,确保解码过程基于“语义排序后的token”。
3 Causal flow query(因果流查询)
作为“语义排序的载体”,通过可学习查询捕捉图像的因果逻辑,动态调整视觉token顺序。
- 数量计算:查询数量 = 视觉token数量,计算公式为:
$ \text{查询数} = \frac{W \times H}{16^2 \times 16} $
其中 $ W、H $ 为输入编码器的图像宽高,16²对应SAM-base的patch分割,额外的16倍来自卷积层压缩。 - 多裁剪策略:为适配不同分辨率图像,避免为每种分辨率设计单独查询集,采用“全局+局部”双视图裁剪:
- 全局视图:分辨率 1024×1024,对应 256 个查询($ query_{global} $)。
- 局部视图:分辨率 768×768,对应 144 个查询($ query_{local} $),裁剪数量 $ k \in [0,6] $(图像宽高均小于768时不裁剪)。
最终传入LLM的token数 = $ k \times 144 + 256 $,范围为 256~1120:
- 下限256:仅全局视图(对应1024×1024图像),与初代 DeepSeek-OCR 一致。
- 上限1120:6个局部视图+全局视图,低于初代 DeepSeek-OCR(1156),与 Gemini-3-Pro 的最大视觉token预算持平。
4 Attention mask
通过掩码设计实现双流注意力机制的隔离与协同,确保视觉token的全局建模和因果查询的有序推理。
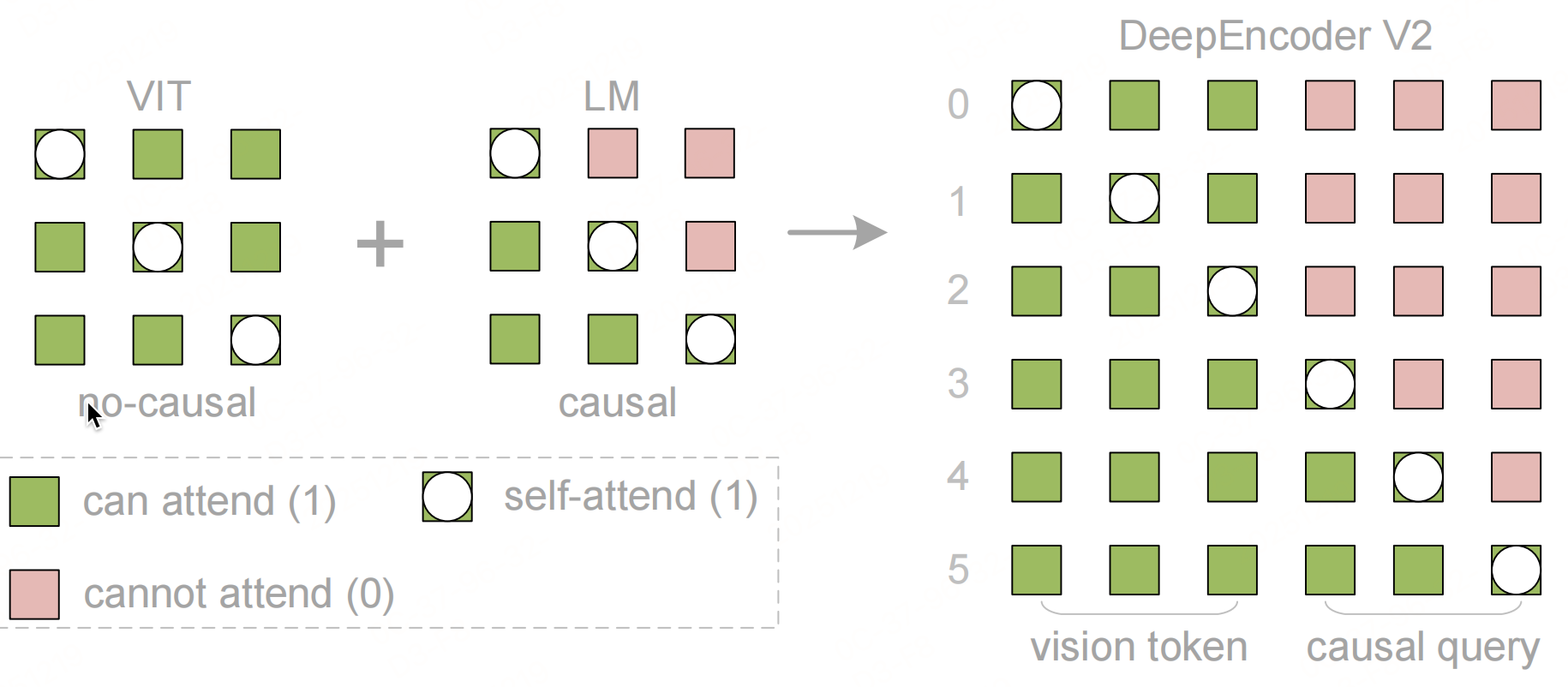
如上图,掩码 $ M $ 由两个区域拼接而成:
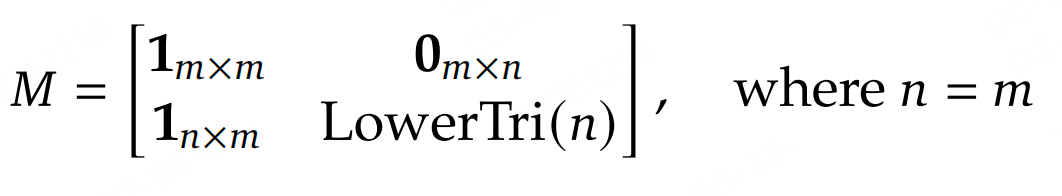
- $ m :视觉 t o k e n 的数量; :视觉token的数量; :视觉token的数量; n :因果流查询的数量( :因果流查询的数量( :因果流查询的数量( n=m $)。
- 左上块 $ 1_{m \times m} $:视觉token的双向注意力掩码(1表示可关注,0表示不可关注),允许所有视觉token互相关注。
- 右上块 $ 0_{m \times n} $:视觉token无法关注因果流查询,避免视觉token被查询的排序逻辑干扰。
- 左下块 $ 1_{n \times m} $:因果流查询可关注所有视觉token,确保查询能捕捉全局图像信息。
- 右下块 $ LowerTri(n) $:因果流查询的因果注意力掩码(下三角矩阵),每个查询仅能关注之前的查询,实现有序的因果推理。
数据侧
上一代采用 OCR 1.0、OCR 2.0 及通用视觉数据(OCR 数据占 80%),但存在 “采样不均衡”“标签冗余” 问题;新一代在继承相同数据源的基础上,做了两点优化:
- OCR 1.0 数据采样平衡
- 上一代:未明确区分内容类型的采样比例,可能导致文本数据过量、公式 / 表格数据不足;
- 新一代:按内容类型划分采样比例,文本:公式:表格 = 3:1:1,确保模型对复杂结构(公式、表格)的学习充分。
- 布局检测标签细化
- 上一代:布局类别标签存在语义重复(如 “figure caption”“figure title” 分开标注);
- 新一代:合并语义相似类别(统一为 “图相关标题 / 题注”),减少标签冗余与歧义,提升训练数据的标签准确性,进而优化布局理解能力。
训练pipline
训练分三个阶段:
阶段1:Encoder Pretraining(编码器预训练)
让视觉tokenizer和LLM-style编码器掌握三大基础能力——特征提取、token压缩、视觉token基础重排序。
- 训练目标:采用语言建模任务(next token prediction),编码器与轻量级解码器联合优化。
- 数据配置:双分辨率数据加载(768×768、1024×1024),约100M图像-文本对样本(序列长度8K)。
- 初始化:视觉tokenizer继承自DeepEncoder,LLM编码器初始化自Qwen2-0.5B-base。
输出仅保留训练后的编码器参数,用于后续阶段。
阶段2:Query Enhancement(查询增强)
强化因果流查询的语义重排序能力,同时提升编码器与解码器的协同性。冻结视觉tokenizer(SAM-conv结构),仅联合优化LLM编码器与DeepSeek-MoE解码器。
阶段3:Continue-training LLM(LLM续训)
冻结DeepEncoder V2所有参数,仅更新DeepSeek-LLM解码器参数。
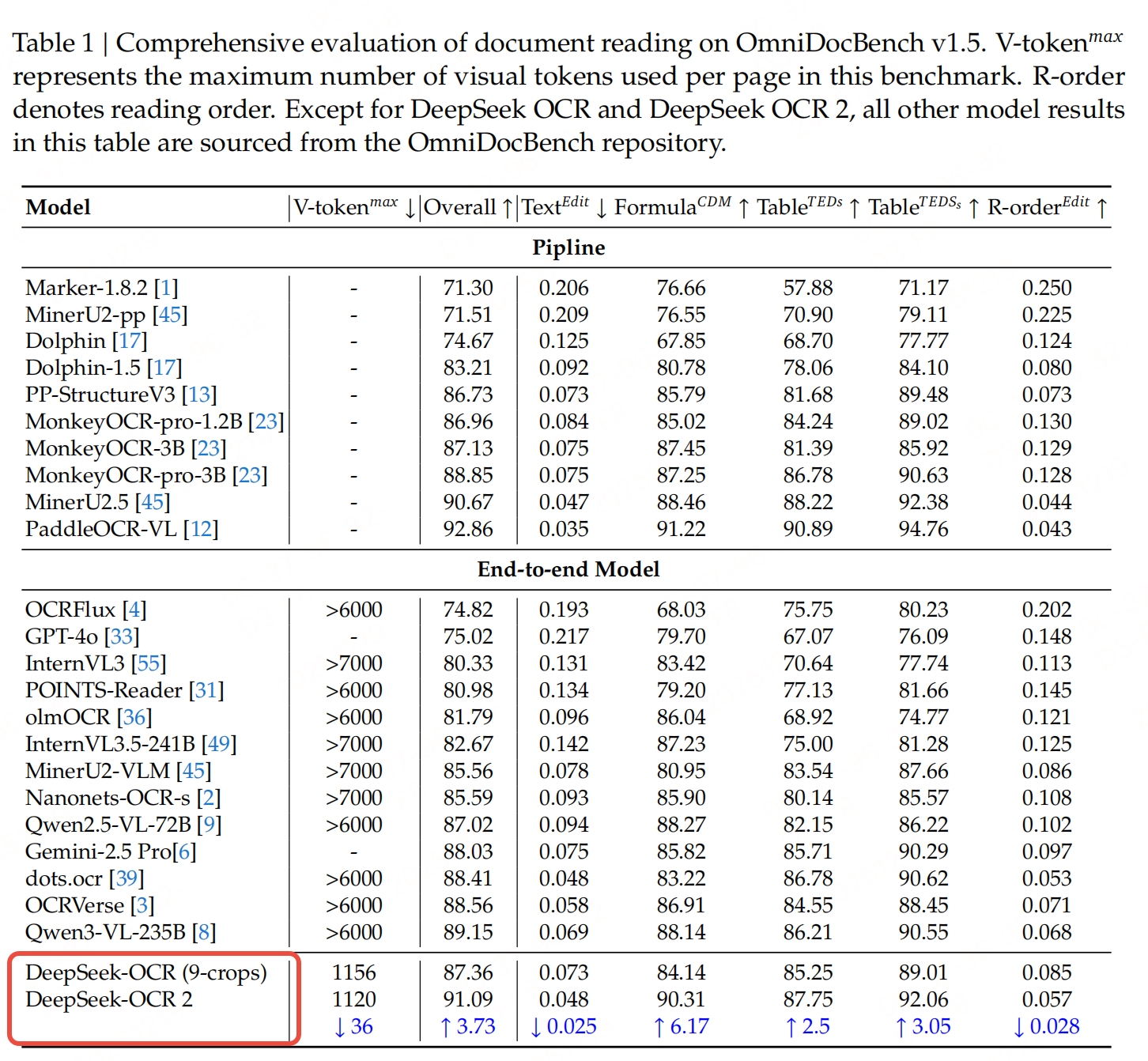
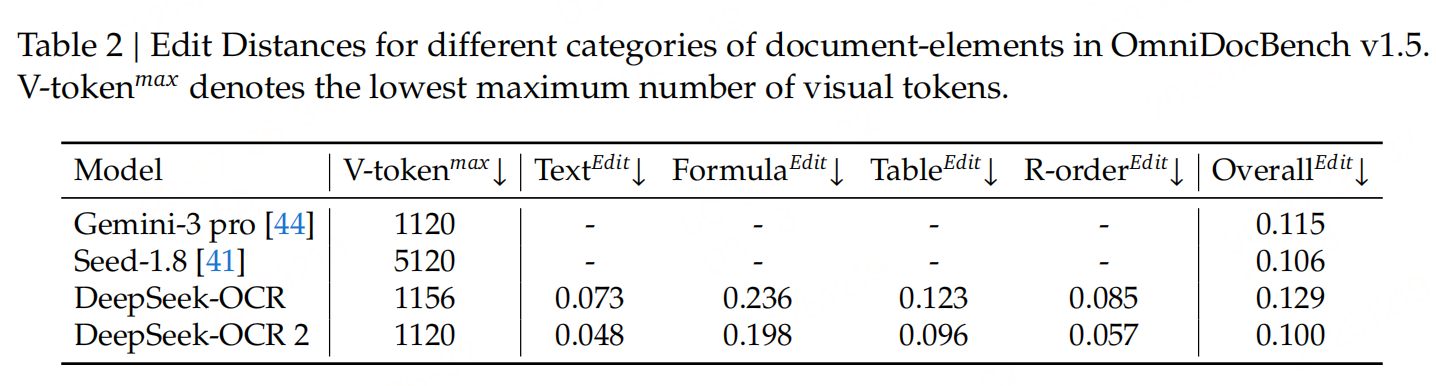
实验

参考文献
DeepSeek-OCR 2: Visual Causal Flow,https://github.com/deepseek-ai/DeepSeek-OCR-2/blob/main/DeepSeek_OCR2_paper.pdf
往期相关
多模态文档解析的开源项目模型技术方案都在《文档智能专栏》,如:
- 再看两阶段多模态文档解析大模型-PaddleOCR-VL架构、数据、训练方法
- 如何打造一个文档解析的多模态大模型?MinerU2.5架构、数据、训练方法
- 端到端的多模态文档解析模型-DeepSeek-OCR架构、数据、训练方法
- 多模态文档解析模型新进展:腾讯开源HunyuanOCR-1B模型架构、训练配方
- 强化学习GRPO(格式奖励)在多模态文档解析中的运用方法
…

这里是“一人公司”的成长家园。我们提供从产品曝光、技术变现到法律财税的全栈内容,并连接云服务、办公空间等稀缺资源,助你专注创造,无忧运营。
更多推荐

 11
11 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)