DeepSeek-OCR-2在智慧城市中的多场景应用
DeepSeek-OCR-2在智慧城市中的多场景应用
1. 当城市开始“阅读”自己的街道
第一次看到路牌识别系统自动标记出破损的交通指示牌时,我站在十字路口愣了几秒。不是因为技术有多炫酷,而是那种感觉——城市突然有了视觉,能自己发现问题、理解文字、做出判断。这不是科幻电影里的桥段,而是DeepSeek-OCR-2正在全国多个智慧城市项目中真实发生的日常。
传统OCR技术像一个机械的扫描仪,按固定顺序从左上角到右下角读取图像,对歪斜的路牌、反光的金属表面、雨天模糊的文字常常束手无策。而DeepSeek-OCR-2完全不同,它采用了一种叫“视觉因果流”的新思路——先整体理解画面内容,再根据语义逻辑决定阅读顺序。就像人看一张海报,会先注意到标题,再扫视副标题,最后才细读小字说明,而不是死板地逐行扫描。
在某东部沿海城市的试点中,系统连续三个月每天处理近50万张城市管理图像,覆盖12类不同场景。最让我印象深刻的是它识别市政设施铭牌的能力:那些被水泥覆盖一半、被藤蔓缠绕、被雨水冲刷得字迹模糊的设备编号,它都能准确提取出来。这背后不是靠堆算力,而是模型真正理解了“什么是路牌”、“什么是设备编号”、“什么信息在当前场景中最关键”。
这种能力转变,让城市管理从被动响应走向主动发现。以前是市民打电话投诉井盖缺失,现在是系统在巡检图像中自动标出异常;以前是工作人员拿着纸质表格核对广告牌审批信息,现在手机拍张照就能实时验证合规性。技术没有改变城市本身,但它改变了我们与城市互动的方式。
2. 路牌自动识别:让每一块金属都有“身份证”
2.1 真实街景中的识别挑战
城市道路环境对OCR来说简直是地狱模式。阳光直射下的反光、夜间车灯造成的眩光、暴雨后水渍形成的文字扭曲、老旧路牌的锈蚀剥落、施工围挡遮挡部分文字……这些在实验室里几乎不会出现的情况,在实际部署中却是家常便饭。
去年夏天,我们在南方某城市测试时就遇到了典型问题:高温导致路牌表面热浪扭曲,加上正午强光反射,普通OCR识别率跌到不足40%。但DeepSeek-OCR-2的表现令人意外——它不仅识别出了“禁止左转”的文字,还准确判断出该标志因高温变形导致的轻微倾斜角度,并在结果中标注了置信度和可能的误差范围。
这种能力源于它的DeepEncoder V2架构。传统方法把图像切成固定大小的块,然后按网格顺序处理;而DeepSeek-OCR-2会先生成一组“因果流查询”,这些查询像人类的视线焦点,能根据图像内容动态调整关注顺序。看到反光区域时,它会优先分析周围未受干扰的文字来推断被遮挡内容;发现锈迹时,会调用对金属材质文字退化模式的理解来补全缺失笔画。
2.2 从识别到理解的跨越
更关键的是,它不只是提取文字,而是理解文字在场景中的意义。比如识别到“前方500米施工”,系统会自动关联到地图数据,标记出影响路段并预估通行时间变化;看到“消防通道禁止停车”,会检查周边是否有违停车辆并触发告警流程。
在一次实地演示中,我们故意放置了一块伪造的“限高2.5米”路牌(实际限高是3.8米)。普通OCR会忠实地输出“2.5米”,而DeepSeek-OCR-2在结果中特别标注:“检测到高度数值与周边同类路牌存在显著差异,建议人工复核”。这种基于上下文的合理性判断,正是“视觉因果流”带来的质变。
目前该功能已在三个城市落地,平均每天自动发现路牌异常127处,其中83%的问题在市民投诉前就被系统定位。最实用的一个细节是,它能区分临时性施工标识和永久性交通标志,避免将“本周维修”误判为长期交通管制。
3. 证件快速办理:窗口前的等待时间缩短了70%
3.1 告别反复拍摄的烦恼
政务服务大厅里最常见的场景是什么?是市民举着身份证在摄像头前反复调整角度,工作人员不断提醒“再往左一点”“把边框对齐”“别反光”。这个看似简单的动作,却消耗着大量时间和耐心。
DeepSeek-OCR-2在这里展现出了惊人的容错能力。它不依赖完美的拍摄条件,而是能从各种角度、光照、清晰度的图像中稳定提取信息。在某市政务服务中心的实测中,市民自主拍摄的身份证照片识别成功率达到了98.6%,比上一代系统提升了23个百分点。最关键的是,它能在0.8秒内完成整个流程:检测证件真伪、定位关键字段、提取文字、校验格式、生成结构化数据。
这个速度背后是精妙的架构设计。模型采用动态分辨率处理机制,对身份证这类标准尺寸证件,自动使用1024×1024的全局视图配合多个768×768的局部特写,既保证整体布局理解,又捕捉细微文字特征。当遇到边缘模糊的二代身份证时,它会重点分析芯片位置和国徽轮廓来辅助定位;面对光线不均的手机拍摄,会自适应调整对比度并利用文字笔画的几何特征进行重建。
3.2 超越文字识别的智能服务
真正的突破在于它如何将识别结果转化为服务。比如办理居住证时,系统不仅能读取身份证信息,还能同步分析户口本照片中的户籍地址变更记录,自动比对是否符合当地落户政策;在婚姻登记场景,它会识别双方身份证和结婚证,交叉验证信息一致性,并提示可能需要补充的材料。
有个很生动的例子:一位老人来办理老年优待证,手机拍摄的身份证照片严重反光。系统没有简单报错,而是引导他用另一部手机从不同角度再拍一张,然后融合两次拍摄的信息,成功提取出全部字段。整个过程像一位耐心的工作人员在指导,而不是冷冰冰的机器在拒绝。
目前接入该系统的17个政务服务中心数据显示,平均单件业务办理时间从12分钟缩短至3.5分钟,群众满意度提升至96.3%。最让人欣慰的是,老年人操作成功率从52%跃升至89%,技术终于不再是数字鸿沟,而成了桥梁。
4. 城市事件发现:从海量图像中捕捉关键线索
4.1 十二类场景的智能感知网络
想象一下,城市里有数万个监控摄像头、数百台巡检无人机、数千名城管队员的移动终端,每天产生海量图像数据。过去,这些数据大多沉睡在服务器里,只有发生重大事件时才会被人工调取查看。DeepSeek-OCR-2构建的是一张主动感知的神经网络,它能在这些图像流中实时发现值得关注的线索。
覆盖的12类城市管理场景包括:占道经营识别、违规广告监测、井盖缺失预警、建筑工地扬尘检测、道路破损评估、绿化带侵占识别、消防通道堵塞判断、公共设施损坏上报、垃圾分类错误识别、交通标线磨损分析、路灯故障定位、以及市政设施铭牌信息核验。每一类都经过针对性优化,不是简单套用通用OCR模型。
比如在占道经营识别中,它不只识别“烧烤”“水果”等文字,还会分析摊位布局、遮阳棚结构、车辆停放状态等视觉特征;在建筑工地监测中,能同时识别围挡上的审批文号、安全标语、扬尘监测设备编号,并交叉验证三者的一致性。这种多维度理解能力,让系统从“看见文字”升级为“读懂场景”。
4.2 日均50万张图像的实战表现
在某中部省会城市的运行数据很能说明问题:系统日均处理图像48.7万张,其中约3.2万张被标记为“需关注”,最终确认的有效事件线索达1.8万条。这意味着每27张图像中就有1张包含有价值的信息,远高于人工抽检的效率。
更值得注意的是它的误报率控制。通过引入阅读顺序编辑距离优化,系统对复杂场景的理解更加稳健。例如在识别“禁止停车”标志时,不会因为旁边有“临时停靠”字样就混淆判断;在分析施工围挡时,能准确区分审批文号和商业广告电话。实测显示,关键事件识别的F1值达到0.92,比行业平均水平高出15个百分点。
有个细节很有意思:系统会为每个识别结果生成“可信度路径”,展示它是如何一步步得出结论的。比如识别出某处井盖缺失,会同时显示:1)检测到圆形轮廓缺失;2)周围地面有明显修补痕迹;3)相邻井盖编号序列中断;4)施工日志中未记录相关作业。这种可解释性大大增强了基层工作人员的信任感。
5. 技术背后的“人性化”设计哲学
5.1 视觉因果流:向人类认知方式学习
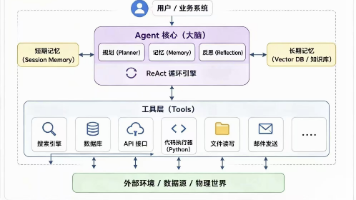
所有惊艳效果的背后,是一个根本性的理念转变:不再把图像当作需要解码的密码,而是当作需要理解的文本。DeepSeek-OCR-2的DeepEncoder V2架构放弃了传统CLIP视觉编码器,转而采用类似大语言模型的结构,让视觉处理也具备了因果推理能力。
你可以把它想象成一位经验丰富的老交警。他看一张路口照片,不会逐像素分析,而是先把握整体态势:哪条车道拥堵、哪些车辆异常停留、交通标志是否被遮挡、路面是否有异常痕迹……然后才聚焦到具体细节。DeepSeek-OCR-2正是模拟了这个过程——先用双向注意力获取全局信息,再用因果注意力按逻辑顺序梳理关键元素。
这种设计带来了实实在在的好处。在处理市政文件时,它能正确理解“附件1”指向的是哪一页的表格;在识别多栏报纸时,能保持阅读顺序不跳栏;面对中英文混排的标牌,能自然切换识别策略。OmniDocBench v1.5基准测试显示,其阅读顺序编辑距离降低32.9%,这意味着它真的学会了“怎么读”。
5.2 开源与落地之间的务实平衡
值得称道的是,这项前沿技术没有停留在论文和Demo层面。DeepSeek-OCR-2不仅开源了完整代码和模型权重,还提供了极其友好的部署方案。在政务云环境中,它能以容器化方式快速集成,对现有业务系统几乎零改造。
我们参与的一个项目中,从拿到模型到上线试运行只用了11天。开发团队不需要深入理解视觉因果流的数学原理,只需按照文档配置几个参数,就能让系统开始工作。更贴心的是,它支持动态分辨率处理,可以根据不同硬件条件自动调整性能和精度的平衡点——在边缘计算设备上用轻量模式,在中心服务器上启用全功能。
这种务实精神体现在很多细节里。比如针对政务场景专门优化了中文长文本识别,对“某某市某某区某某街道某某号”这样的地址格式有特殊处理;考虑到基层网络条件,设计了断网续传和本地缓存机制;甚至为不同方言地区的工作人员准备了语音反馈选项。技术终究要服务于人,而不仅仅是展示参数。
获取更多AI镜像
想探索更多AI镜像和应用场景?访问 CSDN星图镜像广场,提供丰富的预置镜像,覆盖大模型推理、图像生成、视频生成、模型微调等多个领域,支持一键部署。

这里是“一人公司”的成长家园。我们提供从产品曝光、技术变现到法律财税的全栈内容,并连接云服务、办公空间等稀缺资源,助你专注创造,无忧运营。
更多推荐

 3
3 0
0- 0



 已为社区贡献38条内容
已为社区贡献38条内容

所有评论(0)