轻量级大数据架构——个人开发者最推荐的一种架构
Kappa架构就是纯流式架构或者批流一体架构,它把所有的内容都放在了流式计算的过程中,数据的来源通常是Binlog(二进制日志文件),展现还是通过APP,存储仍然通过MySQL,hive和elasticsearch等数据库或数据仓库完成,批处理则通过flink的重放来实现。爬虫的框架也就是Requests,BS4,Selenium,Scrapy,lxml,在爬的过程中可通过BS4和lxml进行ET
常见的大数据架构是这两种:Lambda架构和Kappa架构。
其中Lambda架构如下:
其中是批、流相分离的,具有实时计算和离线数据仓库两个部分;离线数仓用hive建成数据仓库,分了很多个粒度~
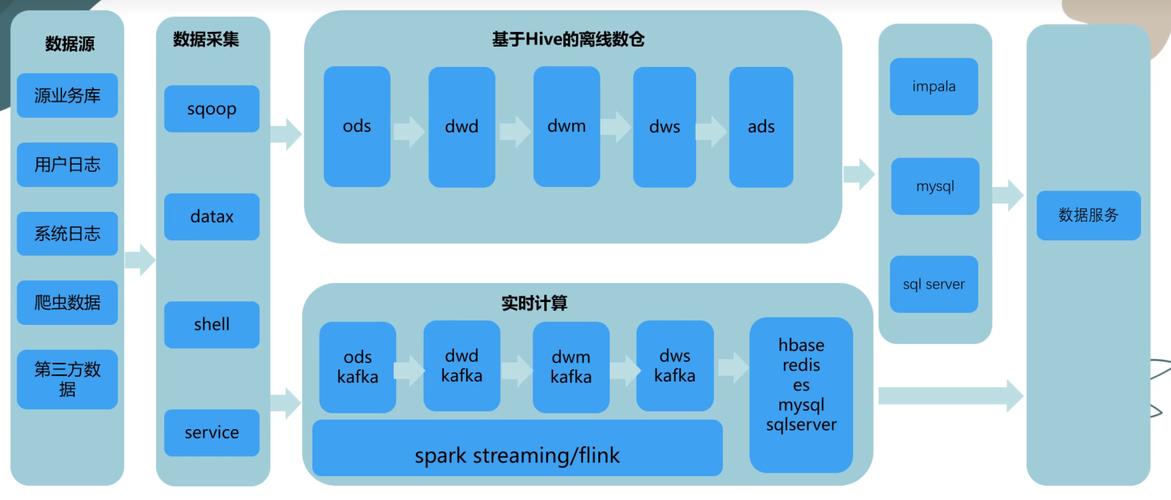
Kappa架构如下:
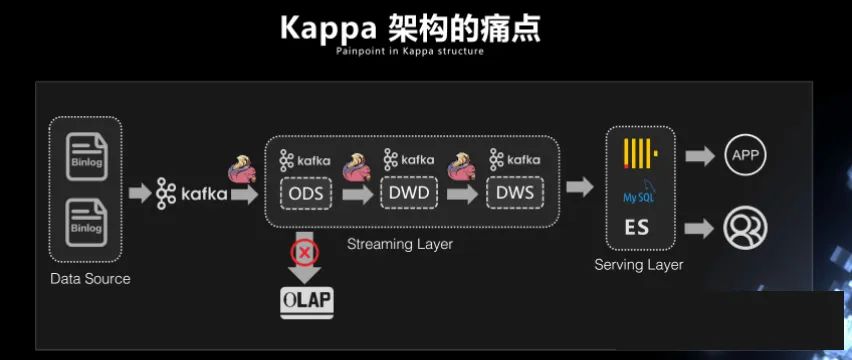
Kappa架构就是纯流式架构或者批流一体架构,它把所有的内容都放在了流式计算的过程中,数据的来源通常是Binlog(二进制日志文件),展现还是通过APP,存储仍然通过MySQL,hive和elasticsearch等数据库或数据仓库完成,批处理则通过flink的重放来实现。
这两者之间其实还有一堆混合架构,其表现可以是这样的形式,通过企业的需求进行比例的调整。
这两种系统架构的共同特征如下:
能够存储海量数据,并且都具有大量的大数据工具作为支撑,从Hadoop到Spark再到Flink/Kafka,还要上Hbase和Hive,简直是重中之重,采集数据时一般还要用Flume和Nifi进行采集。
具有内外两种数据源;
需要通过数据服务层并开发APP来给用户展现。
配置的服务器数量起码在10台以上,造价起码超过10万,需要至少2-3台交换机;
要处理网络延迟、broker性能卡上限、数据流量突增、节点协调、消费者处理达到上限之类的乱七八糟的一堆问题。
更主要的是——个人开发者压根玩不起这套架构图。
因此对于个人版大数据开发者来说,需要通过其他的方式平替企业架构,说白了就是用不起集群才需要平替。平替需求为:
不启动任何集群,成本仅限于一台轻薄本到3台轻薄本之间,有轻薄本的情况下,成本接近0。
保证不会弱于企业架构的速度。
个人开发者拿来玩玩。
功能要和企业的Kappa架构、Lambda架构一样齐全。
下面是一张更为轻量的架构图,大抵如下:
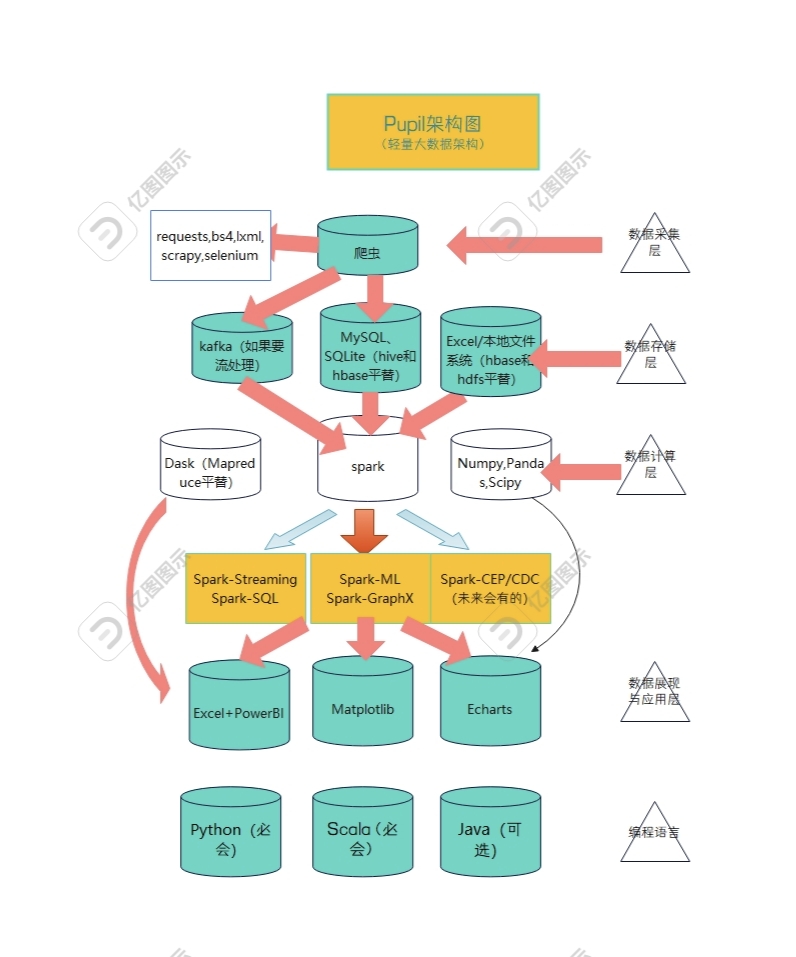
这个大数据架构是非常轻量级的架构,暂且叫他pupil架构吧。
Pupol架构同样有数据源、数据采集层、数据存储层、数据计算层、数据展现与应用层,同样要ETL。
数据源:主要来自互联网数据等外部数据,因为个人并没有企业那么大量的日志或用户行为数据。而企业通常有大量日志或用户行为数据,乃至设备数据。
这种情况下,就可以简化数据的采集层,Flume和Nifi等全部砍掉不要。
采集层直接换成爬虫——由于没了内部数据源,也就没有用Flume和Nifi采集的必要性,此时用爬虫获取数据就是必然的选择。
爬虫的框架也就是Requests,BS4,Selenium,Scrapy,lxml,在爬的过程中可通过BS4和lxml进行ETL,当然也可以通过Scrapy框架搭建pipeline实现ETL。
但是需要注意的是:数据采集时只能获取公开评论和其他的数据,且仅允许个人学习和研究,禁止作为他用;且能够调用API尽量调用API,能获取更精细的公开数据。(ps:Name字段和ID字段任何时候都不应获取)(下期再讲)
数据传输层用Kafka或Redis不变,但是:
Kafka是单节点的,Redis同理;如果不想要zookeeper依赖,可考虑Redis或者socket进行平替。
数据存储层直接平替:
Excel->平替Hbase
MySQL和SQLite->平替Hive,运用MySQL来存储真实数据,用SQLite来存储元数据。
本地文件系统->平替HDFS,但建议安装hadoop(可不选)
数据计算层:
Spark:保持不变,能够进行批流一体的计算,机器学习以及图计算。
Dask->平替Mapreduce,将大批量数据分块传输。
Numpy,Pandas:该咋玩咋玩,小数据量下也可以加入Sklearns,但Spark作为速度是刚需。
数据展现与应用:
Excel:实现简单可视化
PowerBI:实现简单可视化
Echarts、Matplotlib:实现交互可视化
这套架构的好处在于:大部分内容不需要别的编程语言,只需要Python配合SQL即可玩转大部分框架。
如果要谈什么编程语言要学,就考虑Python和scala,毕竟scala是spark原生语言,速度比pyspark要略快40%。Java可选,但并非一定要学。
想要看平替框架的架构,等下回分解~

这里是“一人公司”的成长家园。我们提供从产品曝光、技术变现到法律财税的全栈内容,并连接云服务、办公空间等稀缺资源,助你专注创造,无忧运营。
更多推荐



 26
26 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)