Dify × PaddleOCR:强强联手,深度集成重塑 Agent 工作流智能文档底座
依托工作流编排、智能体框架、数据管理与模型接入等核心能力,Dify 降低了先进 AI 技术的使用门槛,使从独立开发者到大型组织都能够以更经济、更可持续的方式应用生成式 Al,并在运营自动化、知识服务、客户支持和智能分析等领域创造可规模化的价值。在 Dify 的标准处理流水线中,PaddleOCR 作为前置节点,将非结构化文档转化为高质量的结构化中间层,有效解决了文本噪声、版式压平、结果难回溯等问题

当前,基于 Agent 与 Workflow 的大模型应用正快速兴起,任务型系统逐渐成为企业落地 AI 能力的重要形态。在这一趋势中,如何高效、精准地处理非结构化文档,成为制约系统性能的关键环节。
作为飞桨生态中成熟的 OCR 与文档智能引擎,PaddleOCR 提供从文字识别到复杂文档解析的全流程解决方案。目前,PaddleOCR 已深度集成至开源 LLM 应用开发平台 Dify,以官方插件形式为开发者提供稳定、可复用的“文档智能入口”,助力构建更可靠、更高精度的文档驱动型 AI 应用。
👉体验 PaddleOCR 官方插件:
https://marketplace.dify.ai/plugins/langgenius/paddleocr
从文档到结构数据,PaddleOCR 为 Dify 注入 OCR 硬实力
在真实业务中,合同、票据、扫描 PDF 等非结构化文档仍占据关键信息载体的重要角色。如果无法在进入 Agent 或 RAG 流程前被准确解析,后续的语义理解、检索与推理效果将大打折扣。
PaddleOCR 凭借其全场景文字识别模型 PP-OCRv5、文档结构解析模型 PP-StructureV3 以及多模态文档解析模型 PaddleOCR-VL,为 Dify 平台带来三项核心能力支持:
-
高精度文本提取:支持图片、扫描 PDF 等多种格式,覆盖中英文及多语言场景;
-
结构化输出:不仅输出文本,还保留段落、表格、标题等版式信息,便于后续分块与向量化;
-
企业级部署友好:支持本地化与私有化部署,满足数据安全与合规要求。
在 Dify 的标准处理流水线中,PaddleOCR 作为前置节点,将非结构化文档转化为高质量的结构化中间层,有效解决了文本噪声、版式压平、结果难回溯等问题,为下游任务提供清晰、可信的输入。为构建高效、稳定的文档处理应用提供了有力保障。

快速上手
在 Dify 工作流中调用 PaddleOCR
开发者无需单独部署 OCR 服务或进行额外适配,只需在 Dify 工作流中选择并接入 PaddleOCR 提供的解析工具,即可完成文本识别与结构化解析。PaddleOCR 插件同时提供三种工具能力,且配置方式与使用路径均保持一致。以「多模态文档解析」工具为例,以下是快速搭建工作流的操作步骤:
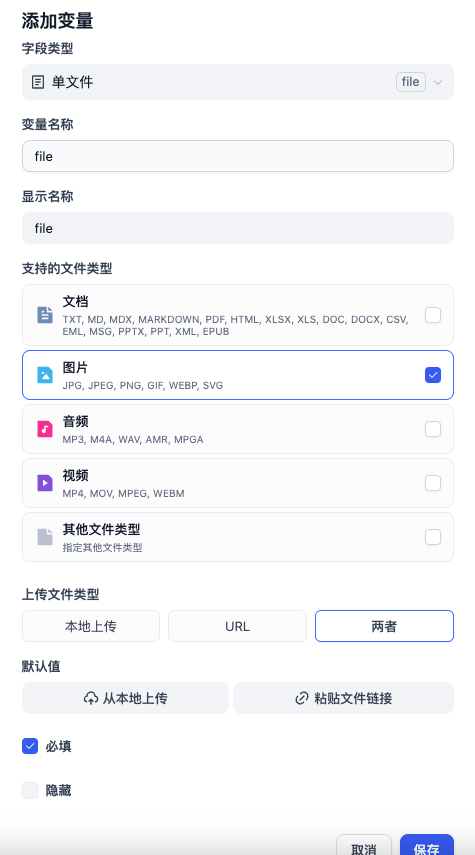
1. 创建 Workflow 应用,定义文档输入
在 Dify「工作室」中创建空白应用,选择「工作流」作为应用类型。进入工作流编辑页面后,以「用户输入」节点作为流程起点,新增一个图片文件输入字段(单文件,类型为图片),用于接收待解析的文档。
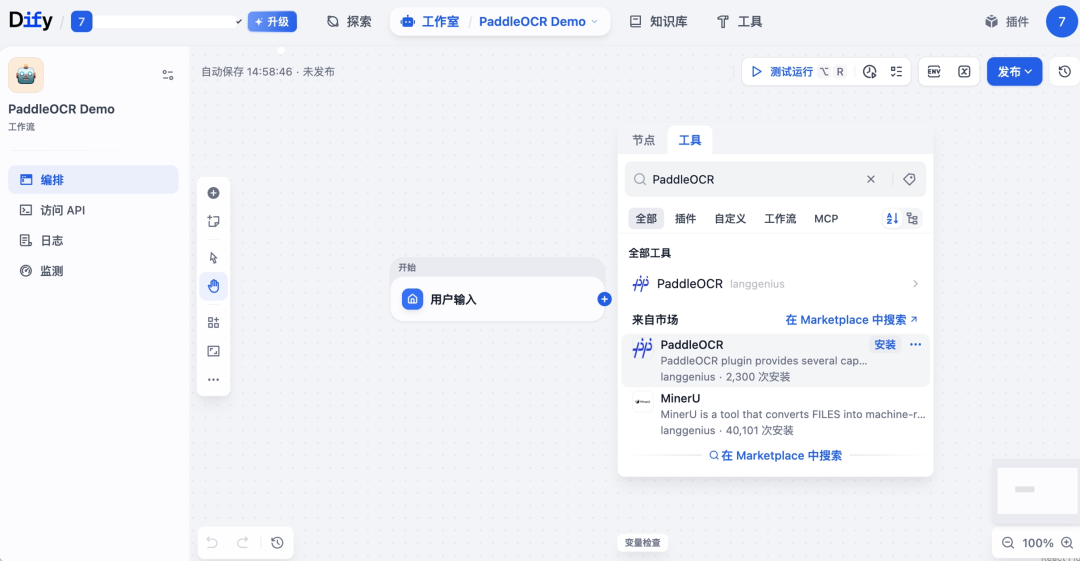
2. 接入 PaddleOCR「多模态文档解析」工具
在工作流中添加工具节点,搜索并启用 PaddleOCR 插件,选择「多模态文档解析」工具并插入流程。
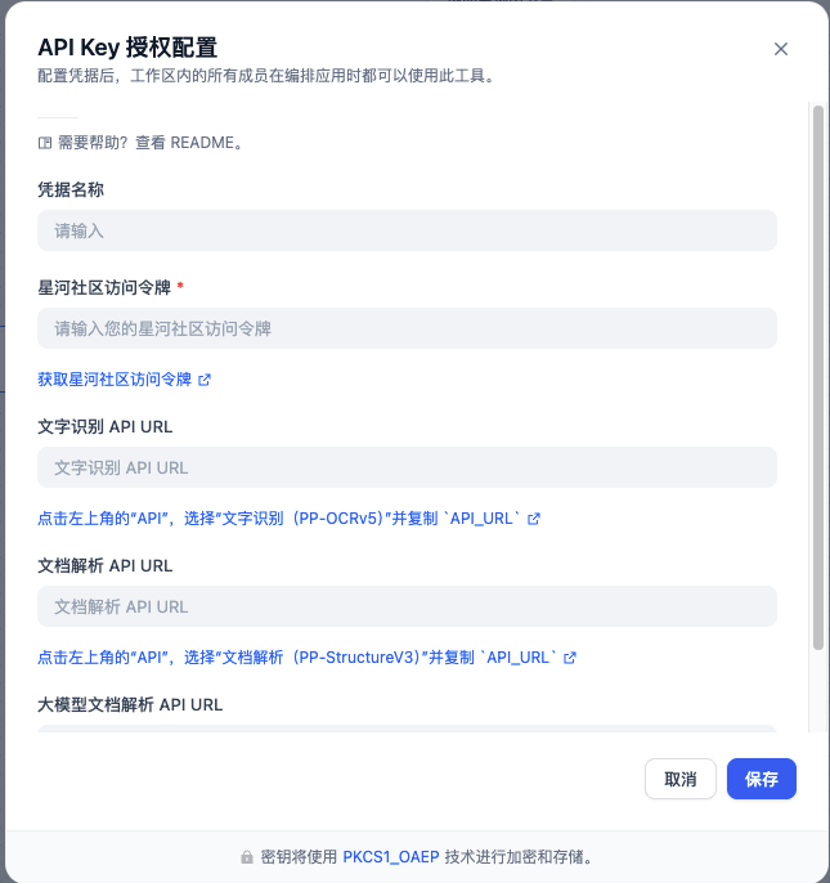
3. 完成API授权并绑定输入参数
在「多模态文档解析」节点中完成以下授权配置:
-
填写星河社区访问令牌(用于接口鉴权),支持申请每天免费解析数万文档页数;
-
配置多模态文档解析 API URL(PaddleOCR-VL)。
随后,将该节点的文件输入参数绑定至用户输入节点生成的文件 URL,并将文件类型固定为图片类型,以确保解析稳定性。
4. 输出解析结果,构建最小可运行链路
在流程末尾新增「输出」节点,并将「多模态文档解析」的核心输出字段(如文本结果、结构化 JSON)映射为应用输出,完成“图片输入→文档解析→结构化输出”的文档解析链路。
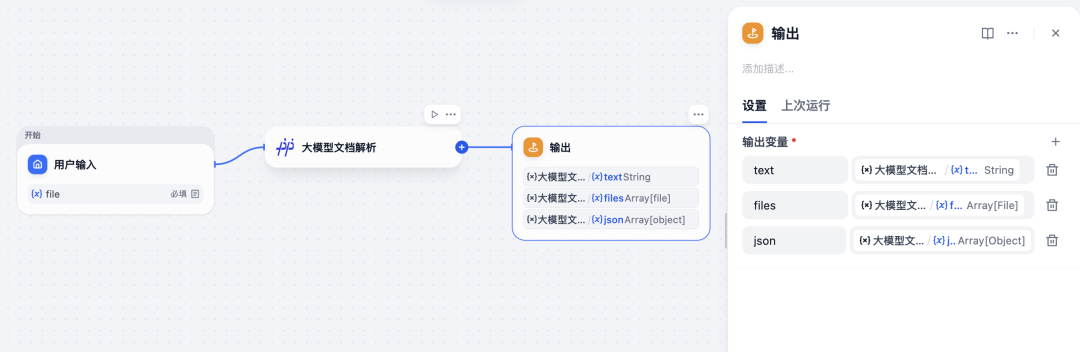
5. 测试与工作流发布
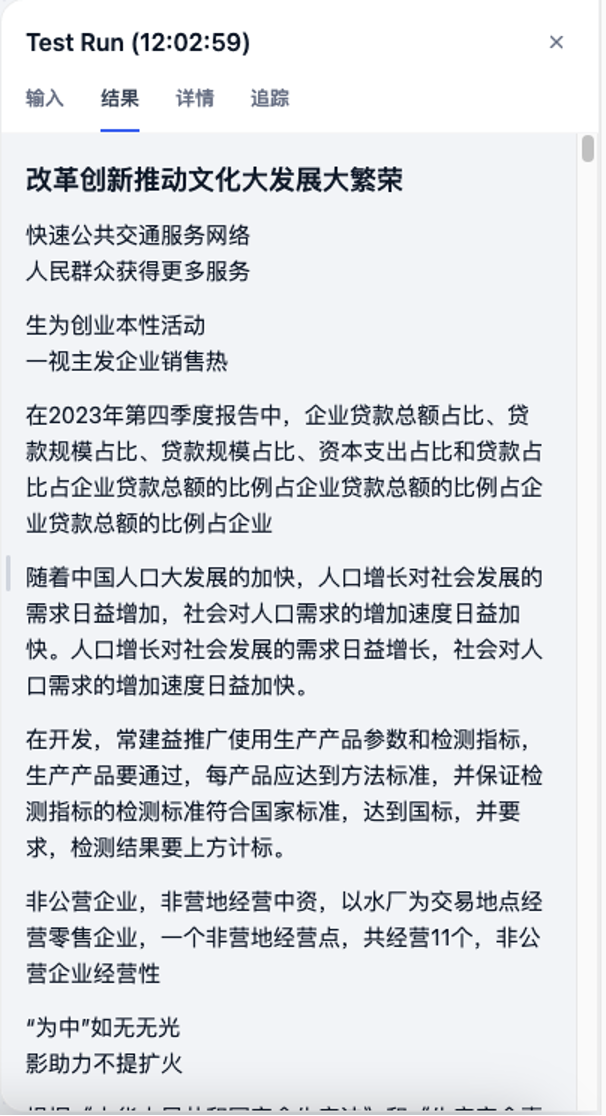
通过「测试运行」上传图片文档,可直接查看解析后的 Markdown 文本与 JSON 结构化结果。验证无误后,即可发布该 Workflow,作为可复用的文档解析应用或下游 Agent / RAG 的输入模块。

PaddleOCR 开源协作
作为 Agent 工作流标准文档入口
通过本次深度集成,PaddleOCR 将领先的文档解析能力注入 Dify 平台,为平台补齐了高精度、多场景的非结构化文档处理环节,使其工作流在应对复杂文档时具备更强的可靠性与完整性。同时,为开发者提供了开箱即用、配置简易的标准化文档解析节点。显著降低了在 Agent 应用中集成专业 OCR 能力的技术门槛与工程成本,让开发者能够更专注于业务逻辑的创新与实现。
此次 PaddleOCR 与 Dify 的深度集成,不仅展示了文档解析能力如何以模块化方式融入 Agent 工作流,并支持不同场景中的灵活组合与扩展,更是一次技术上的深度融合与开源生态层面的重要协作实践。
-
关于 Dify
Dify 是一个开源、可投产的 Agentic Al 应用搭建平台,通过低代码方式帮助企业与开发者快速构建、部署和运营生成式 Al 应用。截至2026年1月,Dify 在 GitHub 上已获得超过12万星标,是全球最受关注的开源生成式 AI 项目之一。依托工作流编排、智能体框架、数据管理与模型接入等核心能力,Dify 降低了先进 AI 技术的使用门槛,使从独立开发者到大型组织都能够以更经济、更可持续的方式应用生成式 Al,并在运营自动化、知识服务、客户支持和智能分析等领域创造可规模化的价值。

了解 Dify:
https://github.com/langgenius/dify
-
关于 PaddleOCR
PaddleOCR 是百度飞桨生态中的 OCR 与文档智能引擎,提供从文本识别到文档理解的全流程解决方案。聚焦真实业务场景中的文档数字化需求,提供可规模化部署的文字识别与语义解析能力。它覆盖109种语言的精准识别,支持图文混排、表格结构、公式符号等复杂文档元素的语义边界精准解析,能够输出符合 JSON / Markdown 等标准格式的结构化数据,实现从图像输入到后续业务系统数据处理与智能应用无缝衔接的全流程自动化。
PaddleOCR 支持 RESTful API、 SDK 集成及 Docker 容器化部署等多种部署与集成方式,满足从轻量级应用到企业级系统的全场景需求,加速 AI 能力在实际业务中的落地应用。
了解 PaddleOCR:
https://github.com/PaddlePaddle/PaddleOCR
加入我们
诚挚邀请全球相关开源项目、开发者工具链团队及各类行业伙伴,与文心大模型、飞桨共建开源生态,共同推进文档解析、知识智能与企业级AI技术的普及与落地。
与文心大模型(ERNIE)、飞桨(PaddlePaddle)开展相关开源生态合作,伙伴可获得:
-
与文心大模型、飞桨的深度技术对接与集成支持;
-
覆盖模型、框架、推理、文档解析、数据治理等全栈生态资源;
-
面向行业的联合解决方案打造与联合发布机会;
-
内容生态、市场活动、行业推广等多渠道赋能。
让我们一起,以开源与技术的力量,构建下一代智能化知识生态。




关注【飞桨PaddlePaddle】公众号
获取更多技术内容~

这里是“一人公司”的成长家园。我们提供从产品曝光、技术变现到法律财税的全栈内容,并连接云服务、办公空间等稀缺资源,助你专注创造,无忧运营。
更多推荐



 1
1 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)