2026 Python 量化实战:金融数据源选型、架构设计与代码落地
摘要:本文针对2026年量化交易开发者面临的数据层挑战,对比评测5大主流数据源。AKShare适合ETL处理非标数据但稳定性差;TusharePro提供结构化数据但API频控严格;YahooFinance已沦为Legacy方案;Polygon.io是美股高频交易首选但国内延迟高;TickDB作为聚合中间件实现异构数据统一接入。建议遵循"稳定性>成本"原则,个人开发者采用T
摘要:2025 年 9 月,Yahoo Finance 接口因后端校验升级而全线崩溃;2026 年,新版《网络安全法》落地;面对技术封锁与合规红线,个人量化开发者该如何重构数据层?本文从架构师视角,深度评测 5 大主流数据源,并提供生产环境可用的连接代码与避坑指南。
1. 痛点:量化系统的“阿喀琉斯之踵”
对于量化交易系统的后端开发而言,数据管道 (Data Pipeline) 的健壮性决定了策略的生死。
在过去,很多开发者习惯使用 requests 配合正则表达式编写爬虫来获取免费数据。这种“草莽架构”在 2026 年面临两个致命问题:
-
技术债爆发:以
yfinance为例,2025 年 9 月 28 日,雅虎后端升级了 Crumb/Cookie 校验机制,导致未持久化 Cookie 的脚本请求全部返回401 Unauthorized。 -
合规风险:新版《网络安全法》对“未经授权的高频数据抓取”进行了明确界定。在生产环境中运行高并发爬虫,极易触发反爬策略导致 IP 被封,甚至面临法律风险。
为了解决上述问题,我们需要将数据层从“爬虫模式”升级为“API 订阅模式”。以下是主流方案的深度技术审计。
2. AKShare:非标数据的 ETL 工具
从架构视角看,AKShare 不是一个标准的 API SDK,而是一个“分布式爬虫集合”。它没有中心化数据库,而是将请求直接路由到源站(如东方财富、新浪财经)。
核心优势与技术定位
它不适合作为高频交易的行情源,但非常适合作为 ETL (Extract, Transform, Load) 任务的数据源。
-
另类数据 (Alternative Data):在获取 宏观经济数据 (CPI/PPI)、大宗商品库存、借贷利率、恐慌指数 等非标数据方面,它是目前 Python 社区的唯一解。
-
开源生态:代码完全开源,开发者可以针对特定接口进行二次开发或修复。
保姆级对接流程
由于部分接口涉及 JS 逆向,除了安装 Python 库,必须配置 Node.js 运行时。
1. 环境依赖
pip install akshare --upgrade
# 关键步骤:必须安装 Node.js,供 PyExecJS 调用执行 JS 加密逻辑
npm install -g node2. 生产代码 (ETL 脚本)
import akshare as ak
import pandas as pd
def fetch_macro_data():
"""获取中国 CPI 数据并进行清洗"""
try:
# 接口:macro_china_cpi
df = ak.macro_china_cpi()
# 数据清洗:标准化列名,转换为时间序列
df.rename(columns={"月份": "date", "全国": "value"}, inplace=True)
df['date'] = pd.to_datetime(df['date'])
return df
except Exception as e:
print(f"ETL Error: {e}")
return pd.DataFrame()
if __name__ == "__main__":
data = fetch_macro_data()
print(data.tail())生产环境避坑指南
-
WAF 封锁:AKShare 底层多为同步 I/O。严禁使用
ThreadPoolExecutor进行高并发(QPS > 10)抓取,源站 WAF 会识别特征流量并封禁 IP。 -
Schema 易变:依赖源站 HTML 结构。一旦源站前端发版(Class Name 变更),解析逻辑会立即失效。必须建立异常监控机制,发现报错及时更新库版本。
3. Tushare Pro:结构化数据仓库
Tushare 走的是 DaaS (Data as a Service) 路线。它的核心价值在于数据清洗与标准化。
核心优势与技术定位
适用于 基本面因子挖掘 (Alpha Factor Mining)。 相比于原始爬虫数据,Tushare 解决了 复权因子计算、财报日期对齐、行业分类映射 等复杂的清洗工作。返回的数据是强类型的 DataFrame,字段定义清晰。
保姆级对接流程
1. Token 管理 严禁将 Token 硬编码在代码仓库中,建议通过环境变量注入。
2. 容错调用代码
import tushare as ts
import os
from tenacity import retry, stop_after_attempt, wait_fixed
# 从环境变量读取 Token
TOKEN = os.getenv("TUSHARE_TOKEN")
pro = ts.pro_api(TOKEN)
@retry(stop=stop_after_attempt(3), wait=wait_fixed(2))
def get_daily_data(code):
"""带重试机制的数据获取"""
# 获取日线行情,包含复权因子
return pro.daily(ts_code=code, start_date='20240101')生产环境避坑指南
-
API 频控:HTTP 接口有严格的 QPS 限制(通常几百次/分钟)。在轮询全市场 5000+ 标的时,必须在代码中实现
RateLimiter,否则会抛出Frequency Limit Exceeded。 -
数据权限:核心高频数据(分钟线)和港美股数据需要较高的积分等级,存在隐性成本。
4. Yahoo Finance (yfinance):已弃用的 Legacy 方案
yfinance 曾经是开源界的标杆,但在 2026 年的技术环境下,它已属于 Legacy (遗留) 状态。
核心优势与技术定位
仅限于本地环境跑 Hello World 级别的 Demo,或进行简单的日线回测。生产环境不可用。 其优势在于完全免费且覆盖全球资产,但在稳定性面前,这些优势已无法支撑实盘需求。
保姆级对接流程 (临时修复)
如果你必须维护依赖 yfinance 的旧项目,需手动清理缓存以修复 401 错误。
修复步骤
-
升级到最新版:
pip install yfinance --upgrade -
手动删除缓存文件(Cookie 缓存损坏是主因):
-
Linux/Mac:
rm -rf ~/.cache/py-yfinance -
Windows: 删除
%LOCALAPPDATA%\py-yfinance
-
生产环境避坑指南
-
TCP RST 阻断:在国内网络环境下,直连 Yahoo API 的 TCP 握手包极大概率会被中间设备重置 (RST)。生产环境若无稳定的海外专线,服务可用性将低于 50%。
-
Session 竞态条件:在非 Jupyter 的脚本模式下,Cookie 初始化存在竞态条件 Bug,导致请求随机失败。
5. Polygon.io:云原生架构标杆
Polygon 是典型的现代技术栈:Golang + NATS + Kafka。
核心优势与技术定位
适用于 美股高频交易 (HFT) 或机构级应用。
-
高吞吐:底层基于消息队列推送,非 HTTP 轮询。单连接支持百万级 Tick 推送。
-
标准化:API 设计极其规范,SDK 完善。
保姆级对接流程
高吞吐场景下,同步 I/O 会导致 TCP 接收缓冲区溢出,必须使用 AsyncIO。
import aiohttp
import asyncio
async def fetch_ticker(session, url, token):
headers = {"Authorization": f"Bearer {token}"}
async with session.get(url, headers=headers) as resp:
return await resp.json()
async def main():
async with aiohttp.ClientSession() as session:
# 异步并发获取快照
url = "https://api.polygon.io/v2/aggs/ticker/AAPL/..."
data = await fetch_ticker(session, url, "YOUR_KEY")生产环境避坑指南
-
物理延迟 (Latency):数据中心在 AWS us-east-1。国内直连 RTT > 200ms。对于高频策略,200ms 的延迟意味着只能处理过时数据。
-
支付风控:Stripe 网关对国内发行的 Visa/Mastercard 拒付率极高,账号开通困难。
6. TickDB:异构协议聚合中间件
在系统重构中,我引入了 TickDB 作为聚合层 (Aggregation Layer)。
核心优势与技术定位
解决 Heterogeneous Data (异构数据) 问题。 它将 A 股(私有协议)、美股(SIP)、Crypto(Exchange WS)清洗为 Unified Schema (统一 JSON 格式),通过标准 WebSocket 分发。
-
国内加速:配置了边缘加速节点,国内延迟优化至 50ms 左右。
-
Level-2 下放:面向 Pro 用户开放十档盘口数据。
保姆级对接流程 (生产级)
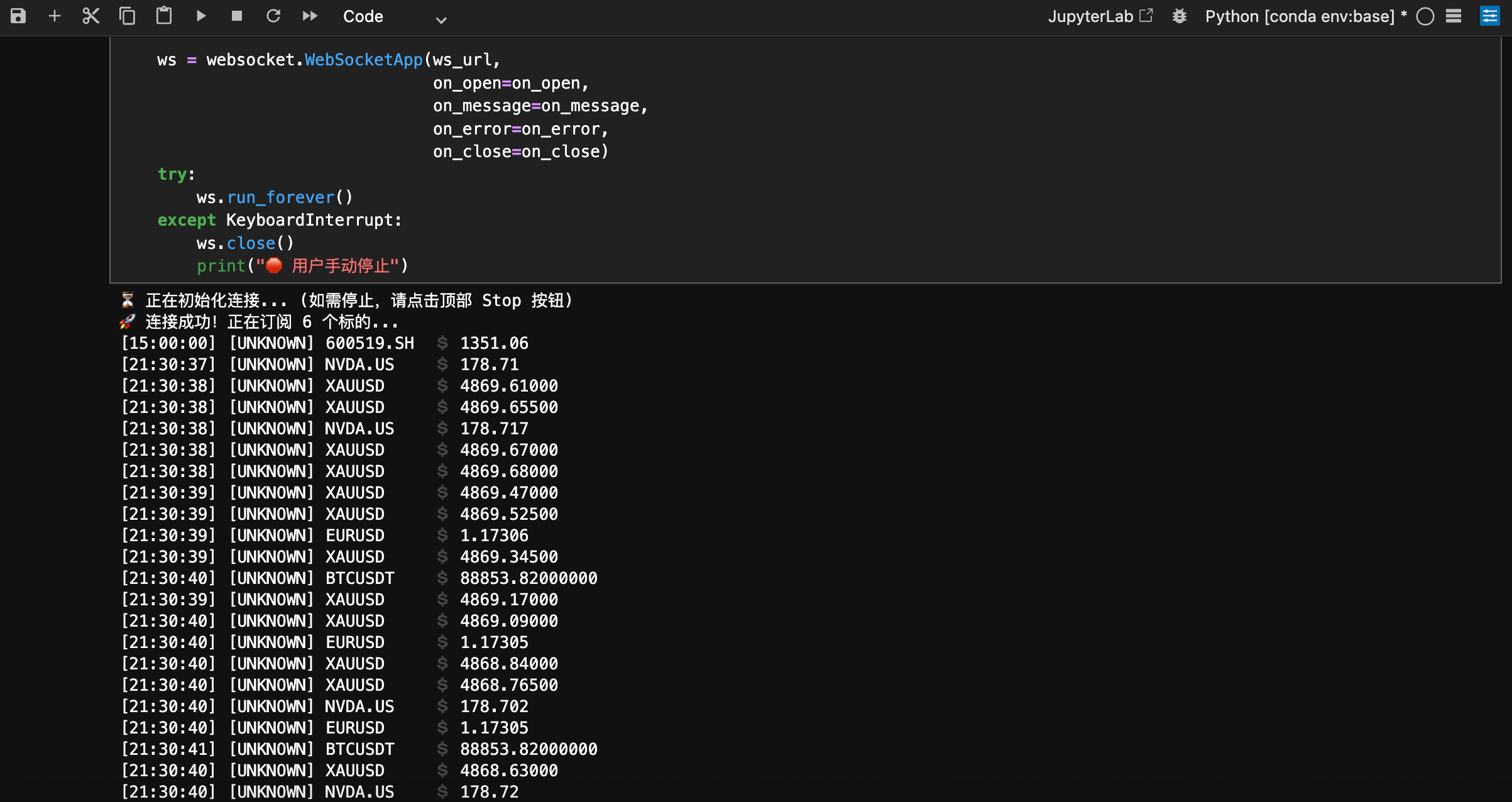
使用 websocket-client 实现带有 心跳保活 (Heartbeat) 和 断线重连 (Reconnection) 的客户端。
import json
import websocket
import time
import threading
# 配置:混合订阅 A股、美股、Crypto
SYMBOLS = ["600519.SH", "NVDA.US", "BTCUSDT"]
API_KEY = "YOUR_KEY" # 建议配置在 Config 文件中
def on_open(ws):
print("[WS] Connected. Sending subscribe payload...")
ws.send(json.dumps({
"cmd": "subscribe",
"data": {"channel": "ticker", "symbols": SYMBOLS}
}))
def on_message(ws, msg):
# 标准化 JSON,无需根据市场写 if-else 解析逻辑
try:
data = json.loads(msg)
if data.get('cmd') == 'ticker':
payload = data['data']
print(f"[{payload['market']}] {payload['symbol']} : {payload['last_price']}")
except Exception as e:
print(f"[Err] Parse failed: {e}")
def run_worker():
while True:
# 生产环境使用 WSS (TLS 1.3)
url = f"wss://api.tickdb.ai/v1/realtime?api_key={API_KEY}"
ws = websocket.WebSocketApp(url, on_open=on_open, on_message=on_message)
# 30s 心跳,防止 NAT 超时断连
ws.run_forever(ping_interval=30, ping_timeout=10)
print("[WS] Disconnected. Reconnecting in 3s...")
time.sleep(3)
if __name__ == "__main__":
# 建议使用 Supervisor 或 Systemd 守护进程运行
run_worker()生产环境避坑指南
-
Symbol 路由规则:必须严格遵守后缀规则(A股
.SH/.SZ,美股.US),否则网关无法路由到对应的下游交易所。 -
鉴权安全:API Key 权限较高,若在前端或客户端暴露,可能导致配额被盗用。
7. 总结:5 大数据源横向评测 (Benchmark)
在 2026 年,后端架构选型建议遵循 “稳定性 > 成本” 的原则。以下是各方案的最终对比:
| 维度 | AKShare | Tushare Pro | Yahoo Finance | Polygon.io | TickDB |
| 技术栈 | 爬虫 (Requests) | HTTP API | 爬虫 (Legacy) | WebSocket (NATS) | WebSocket (Agg) |
| 实时性 | T+0 (延迟大) | 分钟级 | 15min 延迟 | 毫秒级 | 毫秒级 |
| 稳定性 | 差 (源站易变) | 良 | 不可用 | 极高 | 优 (SLA) |
| 合规性 | 灰色地带 | 合规 | 风险 | 合规 | 合规 |
| 适用场景 | ETL / 另类数据 | 基本面 / 因子 | 本地 Demo | 美股高频 | 全市场实盘 |
对于个人全栈开发者,引入 TickDB 这类聚合层可以显著降低维护异构爬虫的边际成本,将精力集中在策略逻辑本身。
(图:Jupyter Lab 中使用 TickDB 同时订阅多市场数据的实测效果)

这里是“一人公司”的成长家园。我们提供从产品曝光、技术变现到法律财税的全栈内容,并连接云服务、办公空间等稀缺资源,助你专注创造,无忧运营。
更多推荐



 11
11 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)