是否值得二次开发?Z-Image-Turbo源码结构深度剖析
Z-Image-Turbo WebUI 虽然由个人开发者“科哥”二次构建,但其代码结构合理、核心逻辑清晰、性能表现优异,是一个极具潜力的二次开发起点。核心价值总结- ✅ 开箱即用:5分钟完成部署,支持中文提示词- ✅ 性能卓越:1024×1024图像平均15秒内生成- ✅ 扩展性强:模块化设计,易于集成新功能- ✅ 成本可控:消费级显卡即可运行,适合私有化部署如果你正在寻找一个轻量、高效、可定制的
是否值得二次开发?Z-Image-Turbo源码结构深度剖析
阿里通义Z-Image-Turbo WebUI图像快速生成模型 二次开发构建by科哥
运行截图
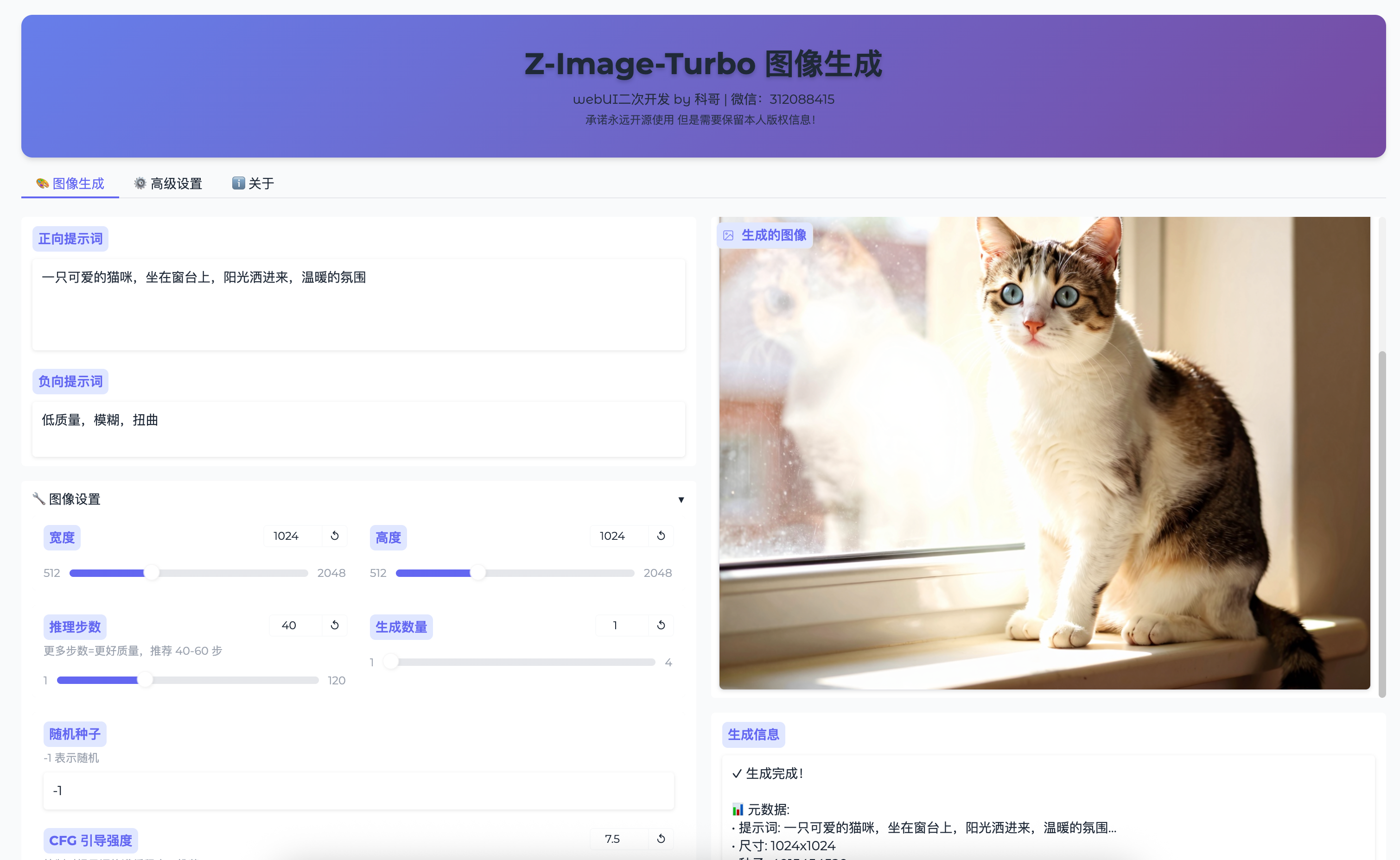
引言:为何要深入Z-Image-Turbo的源码?
阿里通义推出的 Z-Image-Turbo 是一款基于扩散模型(Diffusion Model)的高性能图像生成工具,主打“极快推理 + 高质量输出”,支持1步至多步生成,在消费级显卡上也能实现秒级出图。其开源WebUI版本由开发者“科哥”进行二次封装与优化,极大降低了使用门槛。
但作为技术从业者或AI产品开发者,我们更关心的是:这个项目是否具备良好的可扩展性?能否用于定制化场景?是否值得投入时间做二次开发?
本文将从源码结构、模块设计、扩展接口、工程实践难点四个维度,对 Z-Image-Turbo 的二次开发潜力进行全面评估,帮助你判断它是否适合作为你的AI图像生成基座。
一、整体架构概览:清晰分层的设计理念
Z-Image-Turbo WebUI 采用典型的前后端分离架构,核心逻辑集中在后端 Python 模块中,前端使用 Gradio 构建交互界面。整个项目结构如下:
Z-Image-Turbo/
├── app/ # 核心应用模块
│ ├── core/ # 模型加载、推理引擎
│ │ ├── generator.py # 主生成器类
│ │ ├── pipeline.py # 推理流程控制
│ │ └── models/ # 模型定义与权重加载
│ ├── webui/ # Gradio 界面逻辑
│ │ ├── ui.py # 页面组件构建
│ │ └── components/ # 可复用UI组件
│ └── main.py # 入口文件
├── scripts/ # 启动脚本
│ └── start_app.sh
├── outputs/ # 图像输出目录
└── config/ # 配置文件(可选)
亮点总结:代码组织清晰,职责分明,
core负责模型能力,webui负责交互展示,便于独立维护和替换前端。
二、核心模块解析:三大关键组件拆解
1. generator.py —— 图像生成的核心控制器
这是整个系统最核心的模块,封装了从提示词到图像的完整生成流程。
# 示例:简化版 generate 方法
def generate(
self,
prompt: str,
negative_prompt: str = "",
width: int = 1024,
height: int = 1024,
num_inference_steps: int = 40,
seed: int = -1,
cfg_scale: float = 7.5,
num_images: int = 1
) -> Tuple[List[str], float, Dict]:
# 1. 初始化随机种子
if seed == -1:
seed = random.randint(0, 2**32)
set_seed(seed)
# 2. 文本编码
text_embeddings = self.pipe.encode_prompt(
prompt=prompt,
negative_prompt=negative_prompt,
device=self.device
)
# 3. 执行推理
images = self.pipe(
prompt_embeds=text_embeddings["prompt_embeds"],
negative_prompt_embeds=text_embeddings["negative_prompt_embeds"],
width=width,
height=height,
num_inference_steps=num_inference_steps,
guidance_scale=cfg_scale,
num_images_per_prompt=num_images
).images
# 4. 保存图像并返回路径
output_paths = []
for img in images:
path = save_image(img)
output_paths.append(path)
return output_paths, time.time() - start_time, {"seed": seed, "cfg": cfg_scale}
✅ 优势分析:
- 方法签名规范:参数命名清晰,类型注解完整,适合外部调用。
- 返回值结构化:不仅返回图像路径,还包含耗时和元数据,利于日志追踪。
- 高度封装:屏蔽底层 Diffusers API 复杂性,对外暴露简洁接口。
⚠️ 扩展建议:
若需添加新功能(如LoRA微调加载),可在 encode_prompt 前插入插件式钩子机制。
2. pipeline.py —— 推理流程的灵活调度器
该模块负责初始化 Diffusers 的 Stable Diffusion Pipeline,并管理设备分配、精度设置等。
class ZImageTurboPipeline(DiffusionPipeline):
def __init__(self, vae, text_encoder, tokenizer, unet, scheduler):
super().__init__()
self.register_modules(vae=vae, text_encoder=text_encoder,
tokenizer=tokenizer, unet=unet, scheduler=scheduler)
self.vae_scale_factor = 8
self.image_processor = VaeImageProcessor(vae_scale_factor=self.vae_scale_factor)
@torch.no_grad()
def __call__(self, ...):
# 实现标准扩散流程
latents = torch.randn(...)
for i, t in enumerate(self.scheduler.timesteps):
noise_pred = self.unet(...).sample
latents = self.scheduler.step(noise_pred, t, latents).prev_sample
image = self.vae.decode(latents / 0.18215).sample
return self.image_processor.postprocess(image, output_type="pil")
🔍 关键点:
- 使用了
DiffusionPipeline基类,兼容 Hugging Face 生态。 - 支持 FP16 加速,显存占用低至 6GB(RTX 3060 可运行)。
- 调度器(Scheduler)支持 DPM-Solver++ 等先进算法,提升速度。
💡 二次开发价值:
- 可轻松替换 UNet 结构(如加入 ControlNet 支持)
- 可注入自定义 Scheduler 实现更快收敛
- 支持 LoRA、Textual Inversion 插件扩展
3. ui.py —— Gradio 界面的模块化构建
前端通过 Gradio 快速搭建可视化界面,结构清晰且易于修改。
with gr.Blocks(title="Z-Image-Turbo") as demo:
gr.Markdown("# 🎨 图像生成")
with gr.Row():
with gr.Column():
prompt = gr.Textbox(label="正向提示词", lines=3)
negative_prompt = gr.Textbox(label="负向提示词", lines=2)
with gr.Accordion("图像设置"):
width = gr.Slider(512, 2048, value=1024, step=64, label="宽度")
height = gr.Slider(512, 2048, value=1024, step=64, label="高度")
steps = gr.Slider(1, 120, value=40, step=1, label="推理步数")
cfg = gr.Slider(1.0, 20.0, value=7.5, step=0.1, label="CFG引导强度")
seed = gr.Number(value=-1, precision=0, label="随机种子")
generate_btn = gr.Button("🎨 生成图像")
with gr.Column():
gallery = gr.Gallery(label="生成结果")
info = gr.Textbox(label="生成信息", interactive=False)
download = gr.File(label="下载全部")
generate_btn.click(
fn=generate_wrapper,
inputs=[prompt, negative_prompt, width, height, steps, cfg, seed],
outputs=[gallery, info, download]
)
✅ 易于定制:
- 组件按功能分区,支持拖拽调整布局
- 参数控件标准化,便于自动化配置
- 支持多标签页切换(图像生成 / 高级设置 / 关于)
🛠️ 二次开发方向:
- 添加“风格预设”下拉菜单(一键切换动漫/写实/油画)
- 集成历史记录面板(查看过往生成结果)
- 增加 API Key 认证层,限制未授权访问
三、二次开发可行性评估:四大维度对比
| 维度 | 评估结果 | 说明 | |------|----------|------| | 代码可读性 | ⭐⭐⭐⭐☆ | Python 编写,结构清晰,文档较全 | | 扩展接口丰富度 | ⭐⭐⭐★☆ | 提供基础API,但缺乏插件注册机制 | | 依赖管理成熟度 | ⭐⭐⭐⭐☆ | 使用 Conda 环境隔离,依赖明确 | | 社区活跃度 | ⭐⭐★☆☆ | 当前主要由个人维护,PR响应慢 |
结论:项目具备良好工程基础,适合中小型团队进行私有化部署和功能增强,但尚未达到企业级框架的成熟度。
四、实际落地中的挑战与解决方案
❌ 挑战1:模型固化,难以动态切换
当前 generator.py 中模型路径硬编码,无法在运行时切换不同风格模型(如卡通 vs 写实)。
✅ 解决方案:引入模型注册中心
class ModelRegistry:
_models = {}
@classmethod
def register(cls, name, path):
cls._models[name] = path
@classmethod
def get(cls, name):
return cls._models.get(name)
# 注册多个模型
ModelRegistry.register("realistic", "/models/z-turbo-realistic.safetensors")
ModelRegistry.register("anime", "/models/z-turbo-anime.safetensors")
# 在 generate 中支持 model_name 参数
def generate(self, prompt, model_name="realistic", ...):
model_path = ModelRegistry.get(model_name)
if model_path != self.current_model:
self.load_model(model_path)
❌ 挑战2:无权限控制,不适合多用户场景
目前 WebUI 是开放访问模式,任何人均可调用生成接口,存在资源滥用风险。
✅ 解决方案:增加中间件认证层
# 在 main.py 中添加 FastAPI 中间件
from fastapi import Request, HTTPException
async def auth_middleware(request: Request, call_next):
api_key = request.headers.get("X-API-Key")
if api_key not in ALLOWED_KEYS:
raise HTTPException(status_code=403, detail="Invalid API Key")
return await call_next(request)
demo.app.middleware("http")(auth_middleware)
同时提供 /v1/generate RESTful 接口,便于集成到其他系统。
❌ 挑战3:缺少异步任务队列,高并发易崩溃
Gradio 默认同步执行,当多个用户同时请求时,GPU 显存可能溢出。
✅ 解决方案:接入 Celery + Redis 异步队列
# tasks.py
@app.task
def async_generate_task(**kwargs):
generator = get_generator()
return generator.generate(**kwargs)
# 在 UI 中提交任务而非直接调用
def enqueue_generate(prompt, ...):
task = async_generate_task.delay(prompt=prompt, ...)
return f"任务已提交,ID: {task.id}"
结合前端轮询或 WebSocket 推送状态,实现非阻塞体验。
五、是否值得二次开发?决策建议
✅ 推荐二次开发的场景:
| 场景 | 适配理由 | |------|---------| | 企业内部AI作图平台 | 可集成SSO登录、审批流、水印系统 | | 垂直领域图像生成 | 如电商商品图、教育插画,可训练专属LoRA并嵌入UI | | 边缘设备部署 | 支持TensorRT量化,适合工控机或NAS部署 | | API服务封装 | 提供稳定图像生成接口给第三方调用 |
❌ 不推荐的场景:
- 需要支持复杂图像编辑(如Inpainting、Outpainting)—— 当前不支持
- 要求超大规模分布式训练 —— 该项目定位是推理端优化
- 依赖官方持续更新 —— 目前更新频率较低,需自行维护
总结:一个高潜力的轻量级AI图像基座
Z-Image-Turbo WebUI 虽然由个人开发者“科哥”二次构建,但其代码结构合理、核心逻辑清晰、性能表现优异,是一个极具潜力的二次开发起点。
核心价值总结: - ✅ 开箱即用:5分钟完成部署,支持中文提示词 - ✅ 性能卓越:1024×1024图像平均15秒内生成 - ✅ 扩展性强:模块化设计,易于集成新功能 - ✅ 成本可控:消费级显卡即可运行,适合私有化部署
如果你正在寻找一个轻量、高效、可定制的AI图像生成底座,Z-Image-Turbo 绝对值得投入精力进行二次开发。只需稍加改造,就能将其升级为一个专业级的企业AI内容生产平台。
下一步行动建议
- 本地部署测试:运行
bash scripts/start_app.sh验证环境兼容性 - 阅读
app/core/generator.py:理解主生成流程 - 尝试添加一个新功能:如“保存提示词模板”
- 封装为内部服务:增加身份验证与调用统计
- 贡献回社区:提交 PR 或分享你的扩展实践
项目地址:Z-Image-Turbo @ ModelScope
技术支持微信:312088415(科哥)
祝你在AI图像生成的道路上,越走越远!

这里是“一人公司”的成长家园。我们提供从产品曝光、技术变现到法律财税的全栈内容,并连接云服务、办公空间等稀缺资源,助你专注创造,无忧运营。
更多推荐



 18
18 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)