3分钟手把手教学:零基础实现DeepSeek本地化部署
**【文章摘要】**针对零基础用户推出的DeepSeek本地部署速成指南,通过环境配置、模型加载、参数调试三步实现AI技术平民化。教程涵盖Anaconda/PyCharm工具链选择、轻量化模型适配技巧及GPU资源优化方案,3分钟完成从安装到运行全流程。结合终端命令实时演示,即使无编程经验者亦可轻松攻克部署难点,快速验证生成效果,为中小企业和个人开发者提供“低门槛+高可控性”的AI生产力解决方案。
【文章摘要】
针对零基础用户推出的DeepSeek本地部署速成指南,通过环境配置、模型加载、参数调试三步实现AI技术平民化。教程涵盖Anaconda/PyCharm工具链选择、轻量化模型适配技巧及GPU资源优化方案,3分钟完成从安装到运行全流程。结合终端命令实时演示,即使无编程经验者亦可轻松攻克部署难点,快速验证生成效果,为中小企业和个人开发者提供“低门槛+高可控性”的AI生产力解决方案。
主要内容:
一:DeepSeek本地部署及模型下载
二:第三方助手下载及配置调试
三:基础知识点
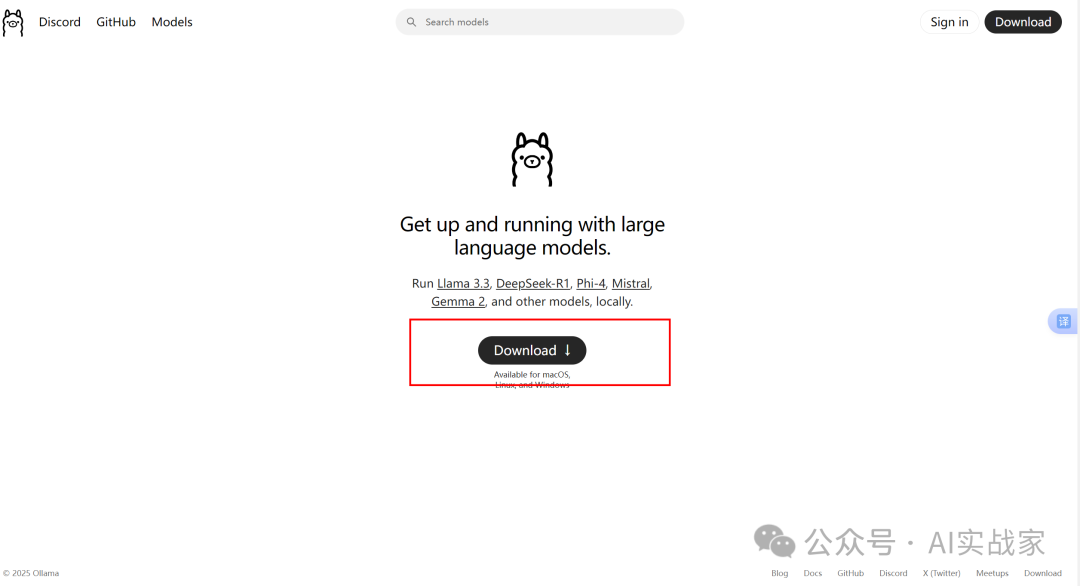
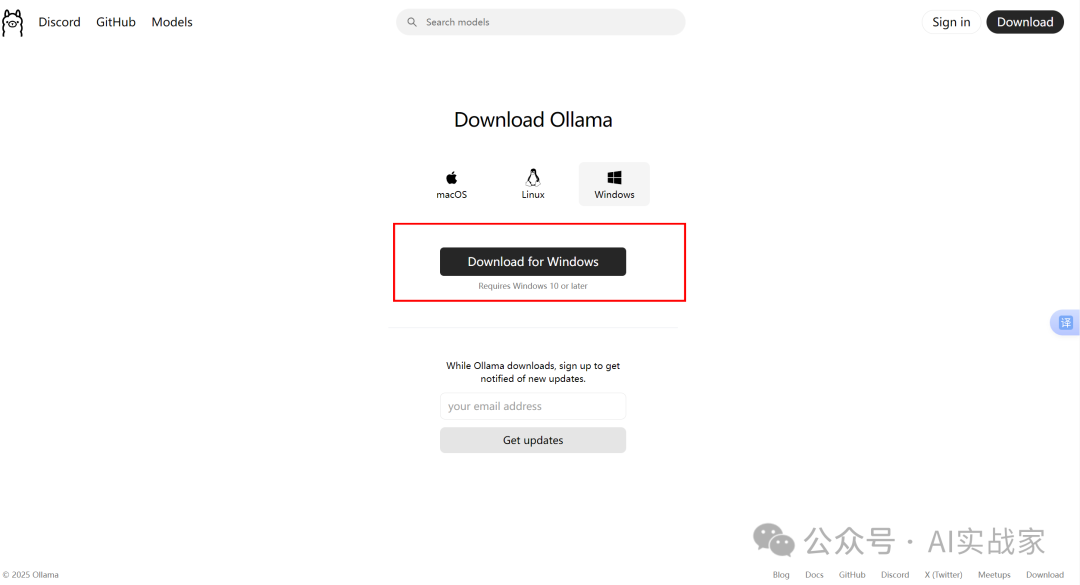
1:下载Ollama(https://ollama.com/)
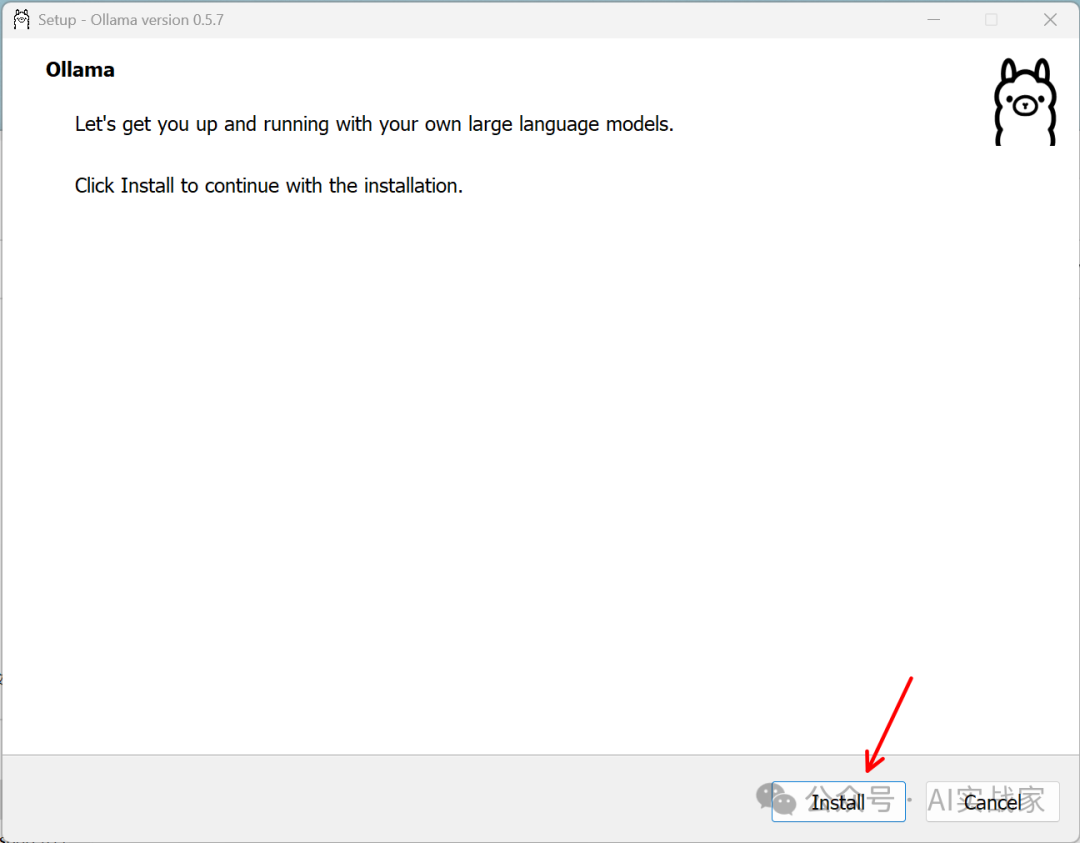
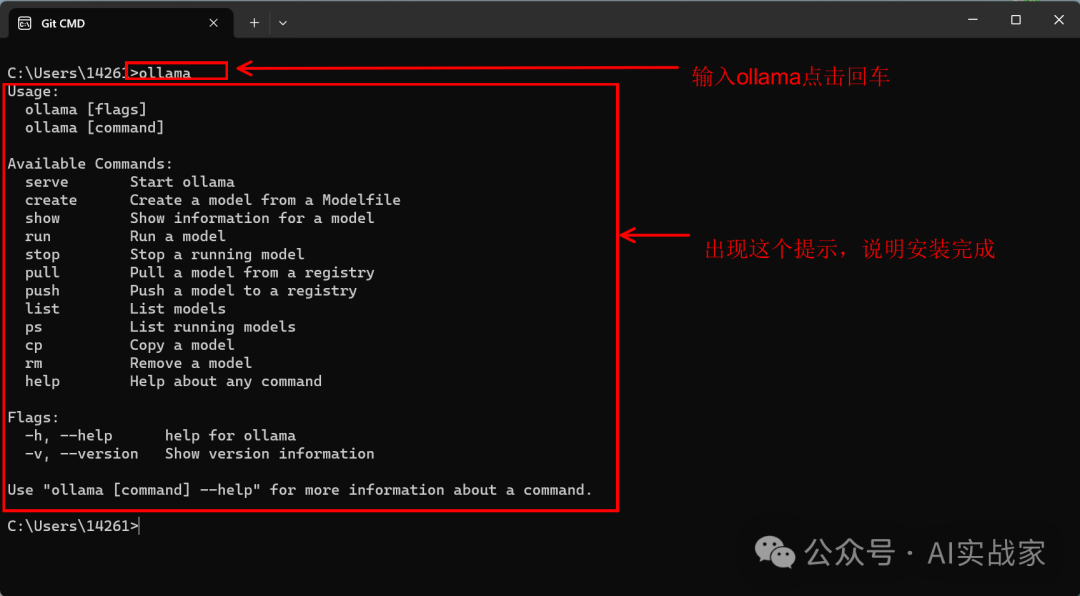
2:按提示安装后,输入cmd,打开命令提示符后,输入ollama回车确认,看到图片提示的输出,说明安装成功

注:出现提示:‘ollama’不是内部或外部命令,也不是可运行的程序或批处理文件。到环境变量中>path里是否有ollama安装目录,如果有,但是还是提示ollama’不是内部或外部命令,也不是可运行的程序或批处理文件,尝试重启电脑
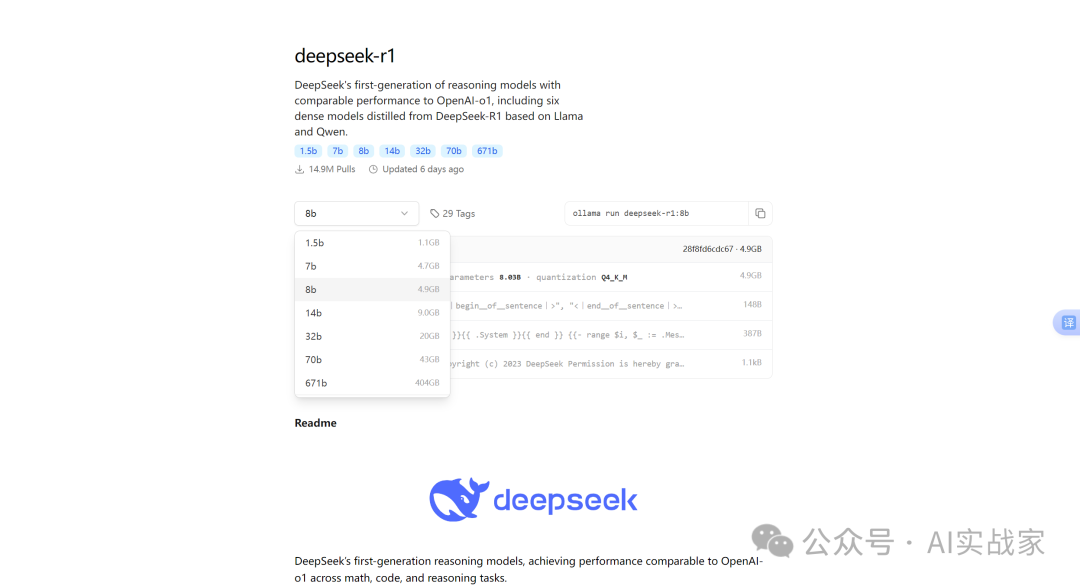
3:到ollama官网首页,点击deepseek-R1,下载模型,选择适合电脑的模型(我演示所用的是笔记本4070 8G显存,所以下载的是8b的模型)
显存参考:
|
|
|
|
|
|
|
|
|
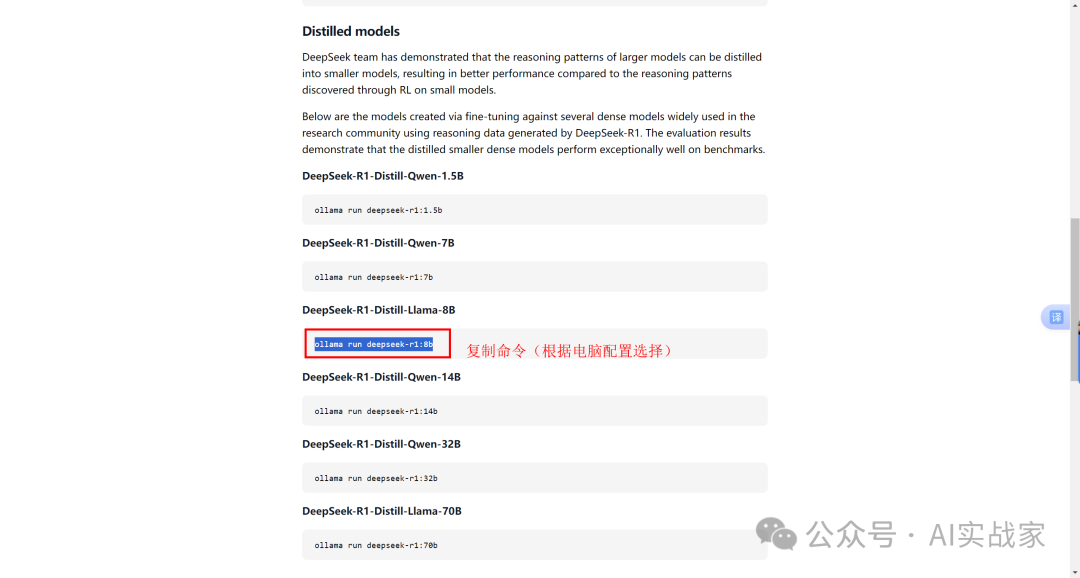
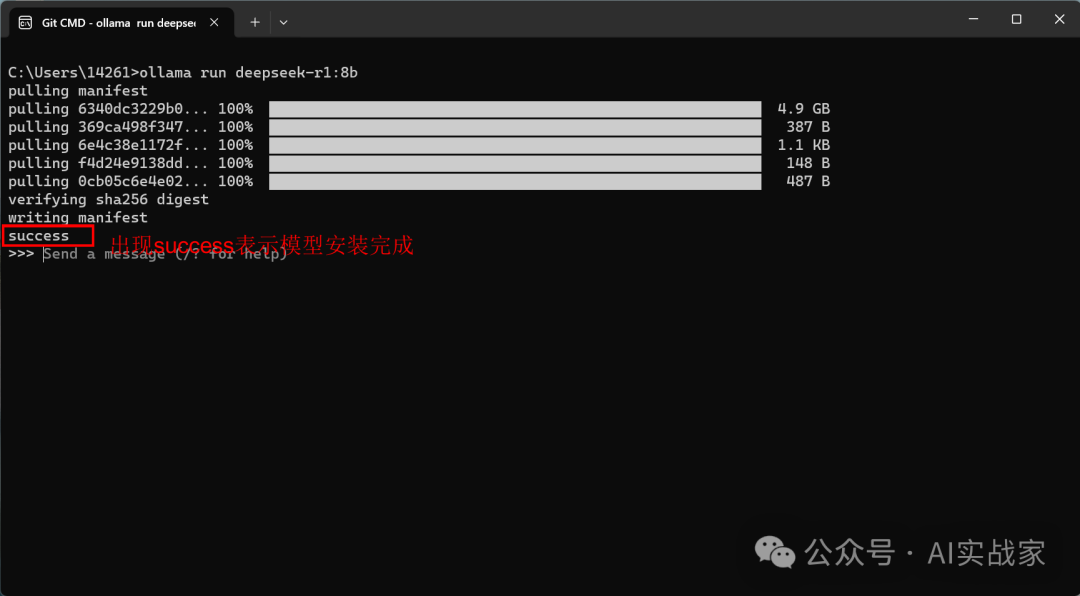
确定好模型之后,下拉网页,复制对应的命令,粘贴到cam终端回车确认,等待模型下载完成,提示出现success就说明deepseek本地版部署完成

可以在cmd终端命令行进行对话
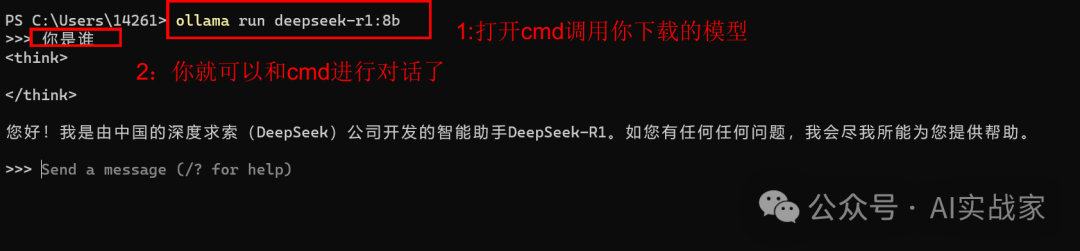
下面我们测试一下8b版本的效果,让它计算一道小学数学题,测试一下准确度
问题:甲乙二人从两地同时相对而行,经过4小时,在距离中点4千米处相遇。甲比乙速度快,甲每小时比乙快多少千米?
正确答案:甲每小时比乙快2千米。
下面是DeepSeek 8b模型的效果
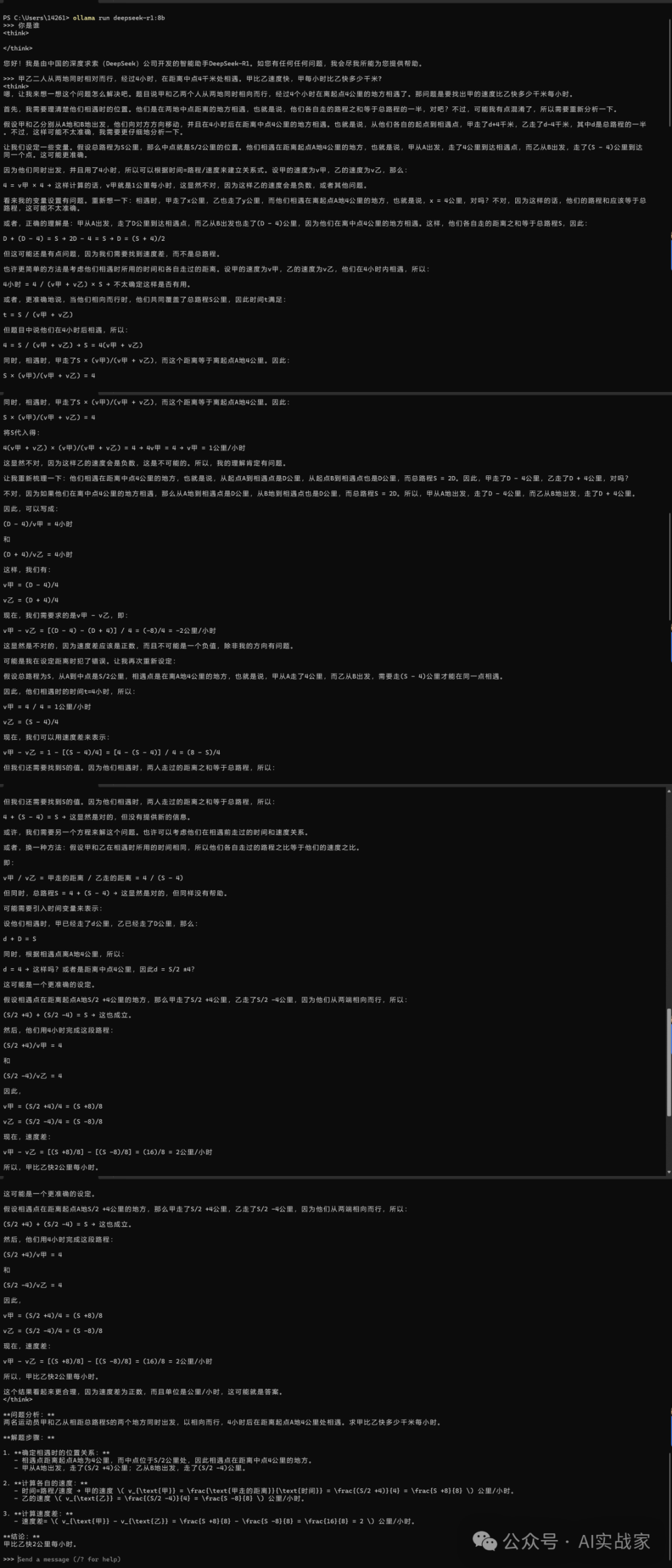
答案准确
4:下载Cherry Studio第三方工具,方便调用,打开https://cherry-ai.com/(这是一个支持多加大模型的AI客户终端,直接对接Ollama的api,实现窗口式的大模型的对话效果),下载Cherry Studio,按照提示完成安装
5:配置模型
点击左下角设置,在模型服务中选择ollama,打开右上角的开关,点击底部的管理按钮,添加刚才下载的deepseek模型
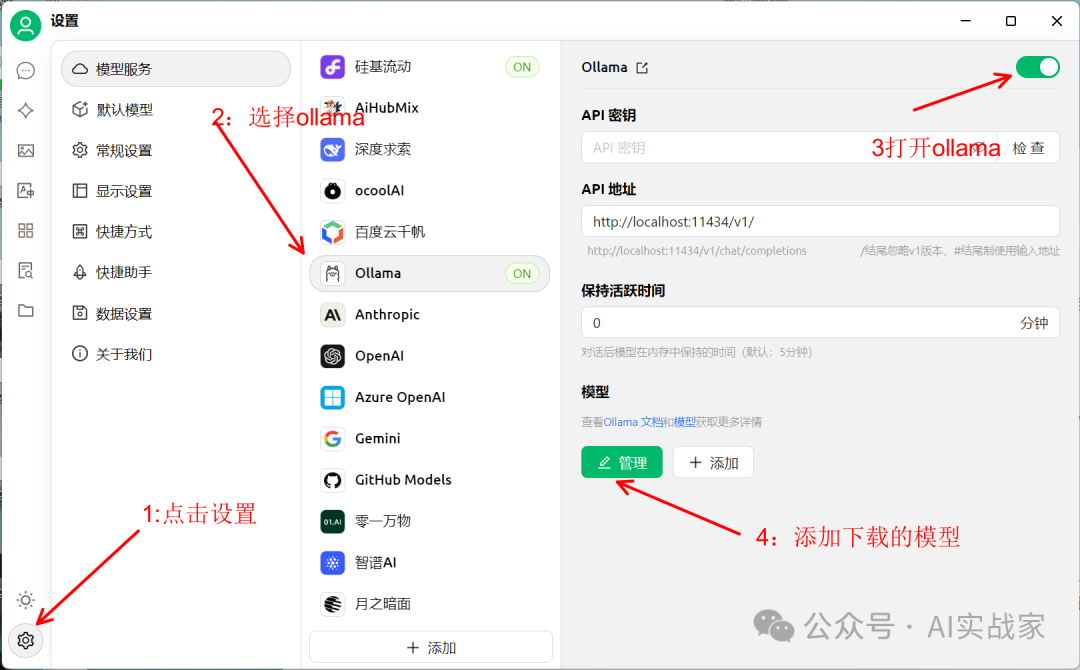
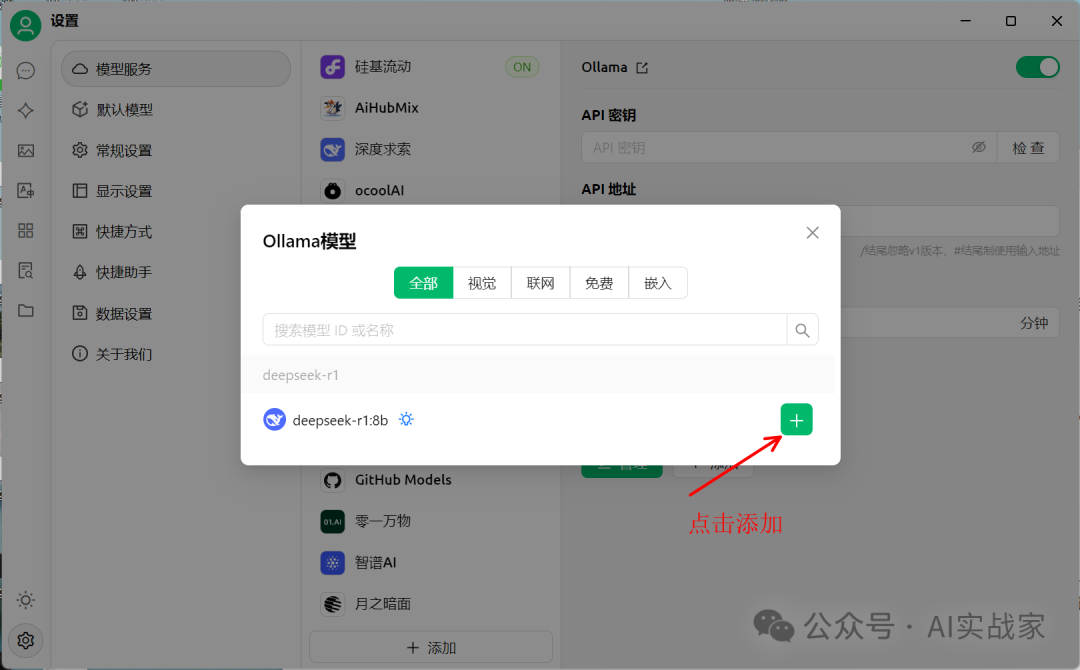
然后在设置界面,选择第二个默认模型,然后在默认助手模型中,选择你要调用的模型(你刚才下载的模型)
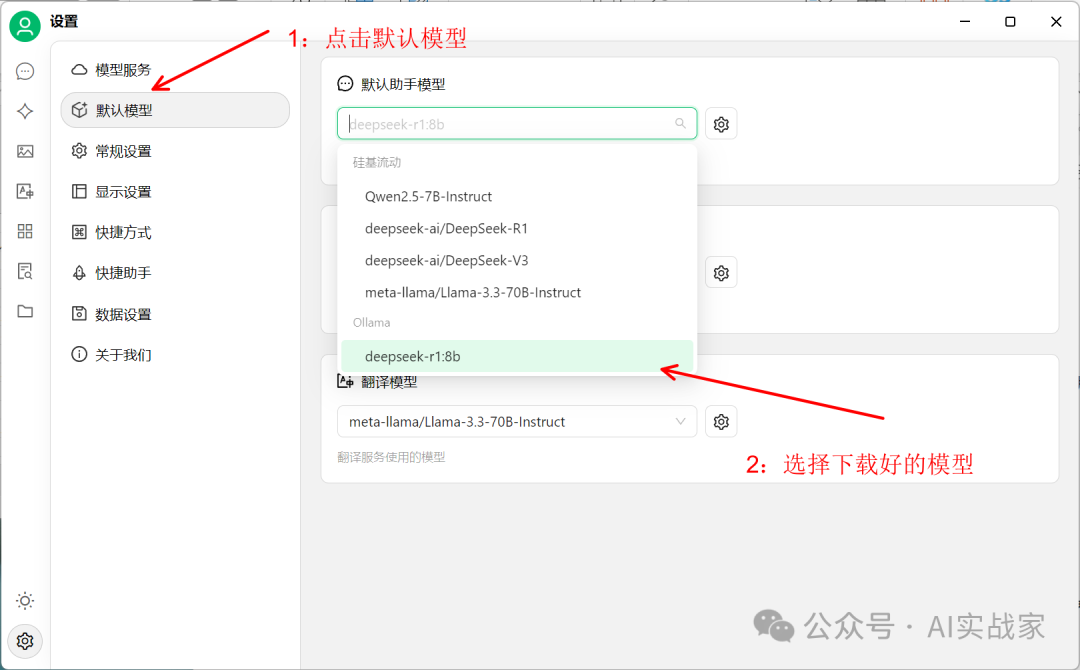
6:完成上边的流程后,就可以和deepseek进行对话了,下边是效果展示
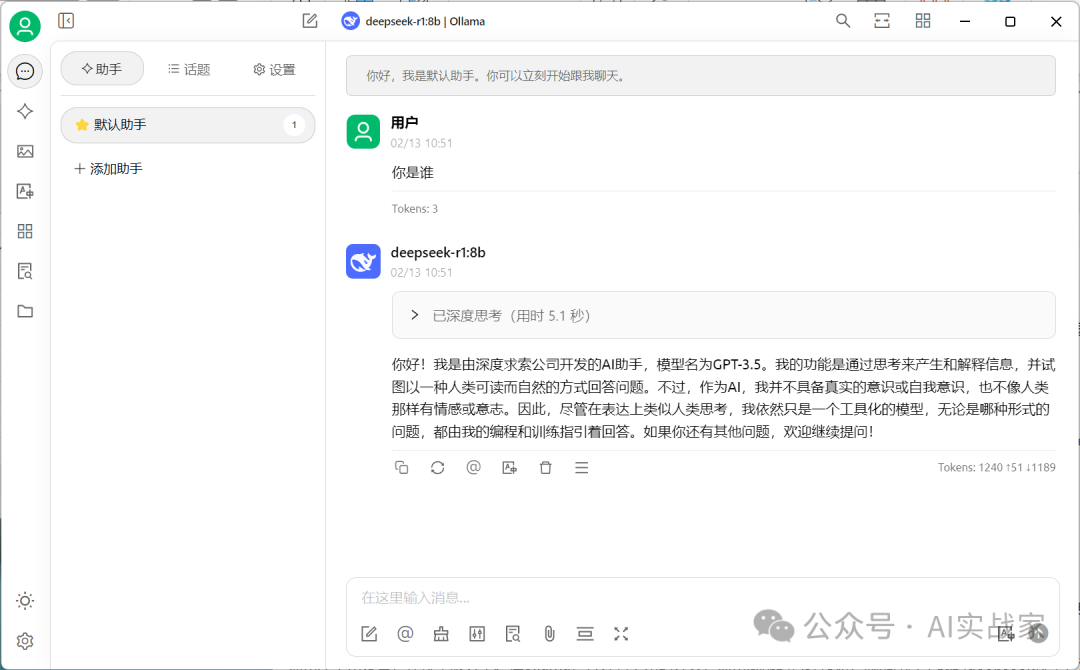
问题:甲乙二人从两地同时相对而行,经过4小时,在距离中点4千米处相遇。甲比乙速度快,甲每小时比乙快多少千米?
正确答案:甲每小时比乙快2千米。
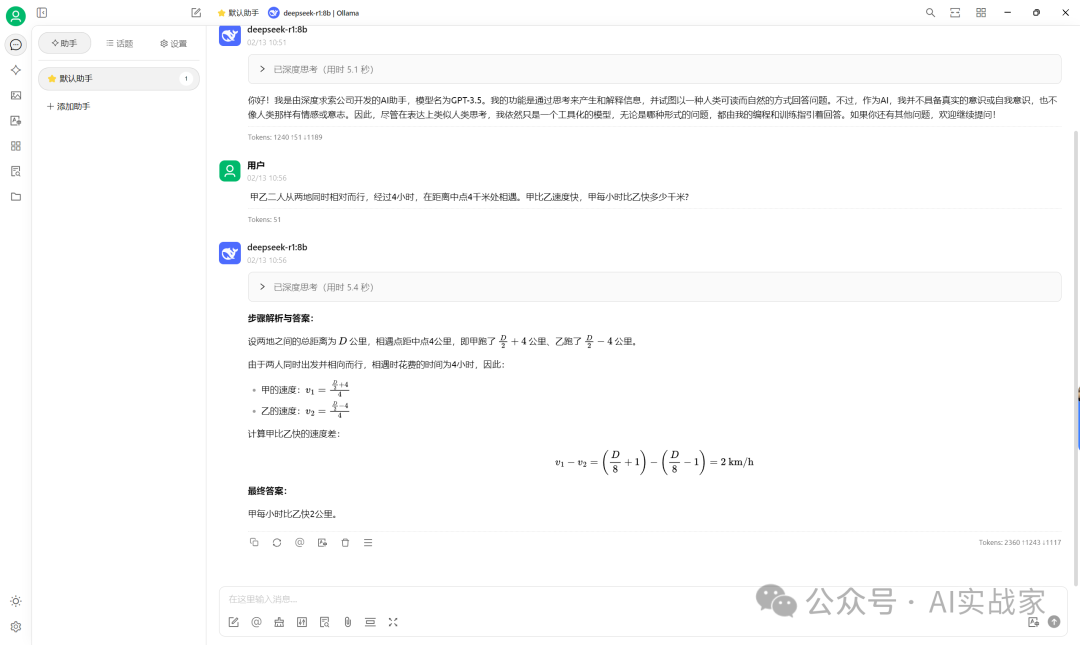
7:基础知识点
|
|
|
|
|
FP32 标准训练精度,也是大模型训练最常用的精度 4字节/参数 FP16 半精度浮点:可以减少内存占用和计算成本,但是会损失结果质量 2字节/参数 BF16 全称bfloat16:和FP16类似,但更适合深度学习 2字节/参数 FP8 8 位浮点数,进一步压缩模型的精度浮点,适合加速推理 1字节/参数 |
|
|
INT8 8 位整数量化,将 32 位或16 位浮点数转换为 8位整数,减少存储和计算需求 1字节/参数 INT4 4位整数量化,最常用的量化方案,进一步减少模型大小,但会损失更多的模型精度 0.5字节/参数 INT2及INT1 这个属于极端压缩了,仅仅适用于特殊应用,不太常用 |
这份完整版的DeepSeek入门资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

这里是“一人公司”的成长家园。我们提供从产品曝光、技术变现到法律财税的全栈内容,并连接云服务、办公空间等稀缺资源,助你专注创造,无忧运营。
更多推荐



 23
23 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)