文献阅读(3)——CLIP(动作感知增强(动作三元组+动作状态提示)+LLM外部知识)——(2)
简单来说,大语言模型生成动作三元组,是一个将其强大的语言理解能力、知识储备和逻辑推理能力,通过提示工程的引导,转化为结构化信息输出的过程。它已经超越了简单的模式匹配,成为一种能够理解上下文和隐含信息的强大工具。MLP 通过“拼接 + 非线性变换”将动作的 “抽象语义” 和 “具体执行细节” 深度融合,为后续模块提供更具表达力的特征,是 “从分开学到联合理解” 的关键
文章目录
- 一:问题
-
- 12:大语言模型(LLM)是怎么根据输入的原始文本描述去生成动作三元组的?
- 13:图中,当动作三元组经过编码之后,变成了向量表示,输入到提示适配器中,它的输出是怎么样的?
- 14:图中动作感知自适应交互模块,当经过提示适配器输出的N个提示向量(向量组)与N个图像嵌入是怎么作用的(先经过交叉注意力,之后经过自注意力)?
- 15:如图所示,动作状态提示和图像嵌入,经过交叉注意力,自注意力,生成向量(n,d),动作三元组和图像嵌入,经过交叉注意力,自注意力,也生成向量(n,d),这两个向量在注意力融合模块中,是怎么工作的?
- 16:如图所示,动作状态提示和图像嵌入,经过交叉注意力,自注意力,生成向量(n,d),动作三元组和图像嵌入,经过交叉注意力,自注意力,也生成向量(n,d),这两个向量在MLP中是怎么工作的?请举例说明?
- 17:MLP输出的Vout和经过注意力融合产生的向量是怎么做matmul的,为什么要怎么做?
- 18:MLP 融合的语义特征” 和 “注意力融合的关联特征有什么不同?他们代表了什么?举例说明。
- 19:注意力融合模块输出的特征和MLP输出的特征做matmul,输出为Action-aware Token,这个Action-aware Token和可学习的视觉提示做Concatenate,具体是怎么做的?
一:问题
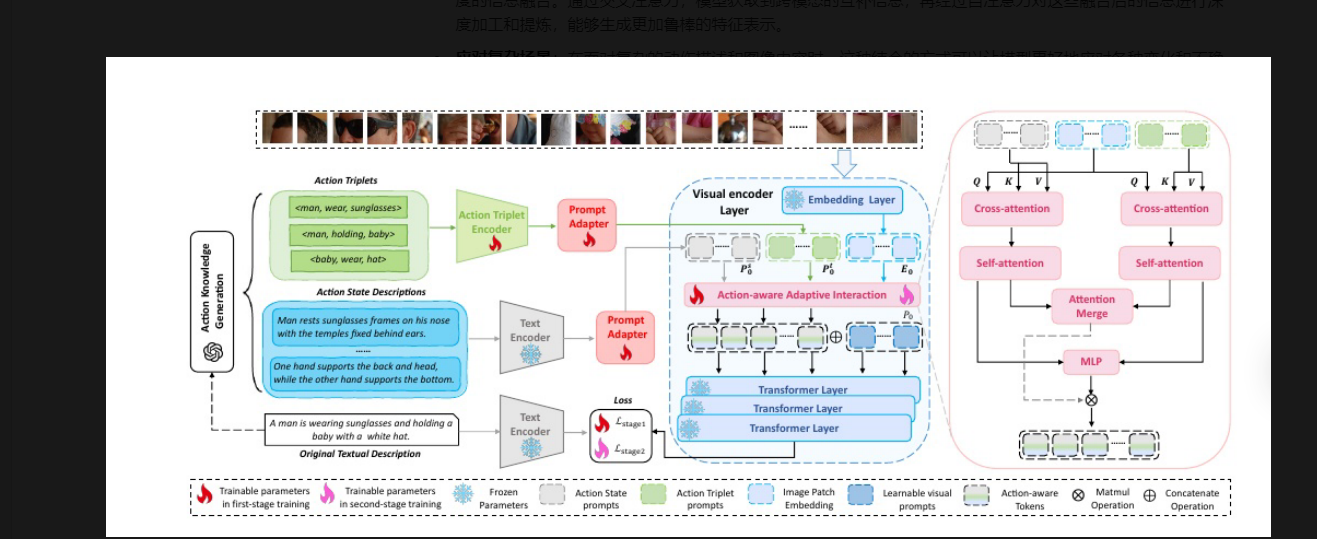
12:大语言模型(LLM)是怎么根据输入的原始文本描述去生成动作三元组的?
大语言模型(LLM)将原始文本描述转换为结构化的动作三元组(通常呈<主语, 谓语, 宾语>或<主体, 动作, 对象>格式),是一个结合了其语言理解能力与特定任务引导的精细过程。下面这个流程图清晰地展示了这一过程的核心步骤与关键决策点,你可以先通过它来建立整体概念。
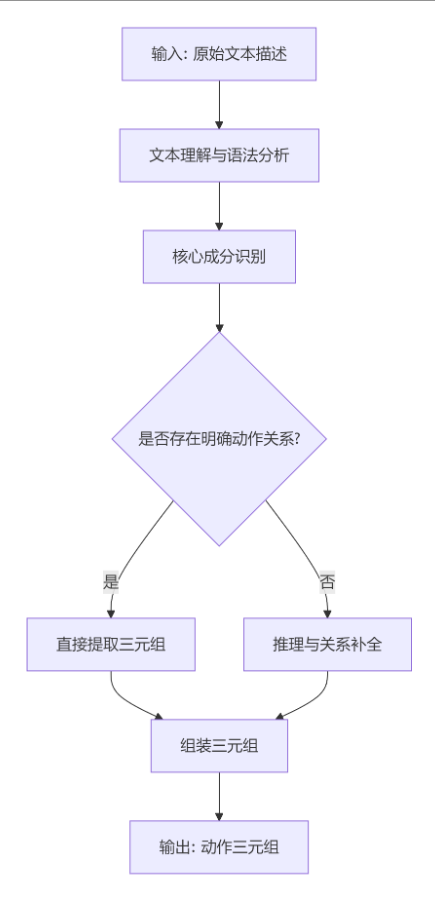
下面,我们来详细拆解图中的每一个关键环节,看看LLM究竟是如何工作的。
1:第一步:文本理解与语法分析
当LLM接收到一句原始文本(例如,“教练把篮球传给了中锋”)时,它首先会进行深度的文本理解。这个过程并非简单的关键词匹配,而是基于其在海量数据上训练所得的语言模型能力。
LM会将句子分解成基本的语言单元(如词或子词),并分析它们之间的语法结构。它会识别出句子的主谓宾骨架、动词的时态和语态、以及各类修饰成分。更重要的是,LLM会利用其学到的语言规律和常识,去理解词语在特定上下文中的确切含义。例如,它能明白这里的“传”指的是“传递球”,而不是“传授知识”。
2:第二步:核心成分识别与三元组提取
在理解句子的基础上,LLM会执行核心的信息抽取任务,即识别出构成三元组的三个核心元素。这个过程可以细分为几种不同的策略:
1:直接提取:对于结构简单、动作关系明确的句子,LLM会直接定位这些成分。例如,从“猫追老鼠”中,可以直接提取出<猫, 追, 老鼠>。
2:推理与关系补全:面对复杂或隐含信息时,LLM会展现其强大的推理能力。
指代消解:当句子中出现代词(如“他”、“它”)或省略时,LLM需要推断其指代的具体实体。例如,处理“她发现了镭并因此获奖”时,LLM能推断出两个“她”都指代“玛丽·居里”,并可能生成<玛丽·居里, 发现, 镭>和<玛丽·居里, 获得, 诺贝尔奖>这样的三元组。
常识推理:有些信息并未直接写在文本中。例如,看到“为庆祝胜利,运动员开启了香槟”,LLM能够基于常识推断出“开启”这个动作的隐含目的是“庆祝”。
3:关键助力:提示工程与任务定制
LLM能高效完成这项任务,离不开提示工程的引导。我们不会只丢给LLM一句“教练传球”就指望它输出三元组,而是会提供清晰的指令模板。这个模板会明确告诉LLM:
任务定义:“你是一个信息抽取专家,请从以下文本中提取所有动作三元组。”
输出格式:“严格按照主语, 谓语, 宾语的JSON格式输出,且所有值转为小写。”
处理规则:“解析代词,保持动作具体化。”
通过这种精心设计的提示,我们实际上是在为LLM设定一个明确的“角色”和“工作流程”,引导它进行结构化思考,从而确保输出结果的规范性和准确性。
4:深入理解:从“关系检索”到“知识生成”
值得注意的是,基于LLM的三元组生成方式,与传统基于规则或统计模型的方法有本质区别。如LightPROF
和LGTM这类先进框架所展示的,LLM并非仅仅进行表面的模式匹配。它能够深入理解动作的局部语义(例如,“传球”与“投篮”是不同的篮球动作),并在知识图谱不完整时,利用其内部参数化的世界知识进行推理,甚至生成缺失的关系,从而补全三元组。这使得LLM在处理复杂、隐含或需要常识的文本时表现出更强的鲁棒性。
5:总结
简单来说,大语言模型生成动作三元组,是一个将其强大的语言理解能力、知识储备和逻辑推理能力,通过提示工程的引导,转化为结构化信息输出的过程。它已经超越了简单的模式匹配,成为一种能够理解上下文和隐含信息的强大工具。
13:图中,当动作三元组经过编码之后,变成了向量表示,输入到提示适配器中,它的输出是怎么样的?
在该流程中,动作三元组经过编码后得到向量表示,输入到提示适配器(Prompt Adapter)后,输出通常是融合了动作信息的提示向量(prompt vectors),这些提示向量会进一步用于与视觉编码器等模块进行交互,以引导模型对视觉内容中动作相关信息的理解和处理。
提示适配器将输入的向量表示,输出的维度和格式要和动作感知自适应交互中的图像嵌入相匹配。
1:举例说明
假设动作三元组是 <man, wear, sunglasses>,经过动作三元组编码器(Action Triplet Encoder)编码后,得到一个向量 v_triplet(比如维度为 [768] 的向量,模拟常见的 transformer 类模型输出维度)。
当这个向量输入到提示适配器时,提示适配器会对其进行处理,生成与该动作三元组相关的提示向量。例如,生成的提示向量可能是一组用于后续跨注意力(Cross-attention)等操作的可学习向量,这些向量能够 “提示” 视觉编码器在处理图像补丁(Image Patch)时,关注与 “人戴太阳镜” 这个动作相关的视觉区域或特征。
具体来说,提示适配器可能通过一些线性变换、注意力机制等操作,将动作三元组的向量 v_triplet 转换为若干个提示向量 p_1, p_2, …, p_n(这些提示向量的维度可能与视觉编码器的输入维度相匹配,以便进行后续的交互计算)。
1:经过提示适配器之后输出的提示向量是怎么样子的?
1:向量的形式与维度
提示向量的维度通常会与后续要交互的模块(比如视觉编码器中的嵌入层、Transformer 层等)的输入维度相匹配。假设视觉编码器中嵌入层输出的图像补丁向量维度是 d(例如常见的 768、1024 等,对应 Transformer 模型的隐藏层维度),那么提示适配器输出的提示向量维度也会是 d,这样才能在后续的 “Action-aware Adaptive Interaction” 等过程中,与图像补丁向量、其他提示向量等进行诸如拼接、注意力交互等操作。
从向量的数量来看,可能会输出一组提示向量(而非单个向量)。例如,为了与视觉编码器中的多个图像补丁或多个 Transformer 层的输入进行交互,提示适配器可能会生成 n 个维度为 d的提示向量,形成一个形状为 (n,d) 的向量组。
2:向量的语义与作用
提示向量融合了动作三元组或动作状态描述的语义信息,其作用是 “提示” 后续的视觉处理模块(如视觉编码器、Transformer 层等)关注与动作相关的视觉内容。

3:向量的动态性
提示向量通常是可训练的(尤其是在模型的训练阶段,如图中标注的 “Trainable parameters in first-stage training”“Trainable parameters in second-stage training”)。在训练过程中,提示向量的数值会不断调整优化,以更好地适配动作语义与视觉内容的关联,使得模型在处理不同的动作相关视觉任务(如动作识别、动作描述生成等)时,都能生成最有效的提示信息。
总之,提示适配器输出的提示向量是融合了动作语义、维度匹配且可动态优化的向量(或向量组),旨在为后续视觉与动作语义的交互提供精准引导。
14:图中动作感知自适应交互模块,当经过提示适配器输出的N个提示向量(向量组)与N个图像嵌入是怎么作用的(先经过交叉注意力,之后经过自注意力)?
经过提示适配器产生的 m个提示向量,与 n个图像嵌入的作用过程,通常会借助注意力机制(包括自注意力、交叉注意力等)来实现交互融合,核心是让**动作语义信息(承载于提示向量)与视觉内容信息(承载于图像嵌入)**充分结合,以引导模型更精准地理解 “动作 - 视觉” 关联。以下是具体的作用逻辑与常见方式:
1:如图所示,经过提示适配器输出的提示向量作为K,V和图像嵌入为Q,是怎么做交叉注意力,
1: 结合图示的具体流程
假设我们有:

步骤 1:计算相似度(Query 与 Key 的交互)

如下所示:
步骤 2:注意力权重归一化

步骤 3:加权求和(Value 的聚合)

2:直观举例(以动作三元组 <man, wear, sunglasses> 为例)

2:如图所示,经过交叉注意力输出的向量(n,d)之后作为输入到自注意力中,在自注意力中,是怎么做的?
在自注意力机制中,经过交叉注意力输出的形状为 (n,d)的向量会作为输入,自注意力会对这些输入向量进行如下操作:
1:自注意力的核心原理
自注意力(Self - Attention)允许序列中的每个向量(这里就是交叉注意力输出的 n个向量)与序列中的所有其他向量进行交互,从而捕捉向量之间的内部依赖关系。对于输入的向量序列 X=[x1,x2,…,xn](其中每个xi∈Rd),自注意力会为每个向量生成查询(Query)、键(Key)和值(Value),然后通过计算查询与键的相似度,得到注意力权重,再用这些权重对值进行加权求和,得到每个位置的输出向量。
2:具体步骤

1:生成查询、键和值

2:计算注意力得分

3:计算注意力权重

4:加权求和得到输出

3:作用
在这个架构中,自注意力的作用是让经过交叉注意力后的向量(这些向量已经融合了动作提示信息和部分视觉信息)之间进一步交互,捕捉它们内部的依赖关系。例如,在处理与 “人戴太阳镜” 相关的向量时,自注意力可以让描述太阳镜的向量与描述人的面部的向量之间建立更紧密的联系,从而更全面、准确地表示整个动作相关的视觉内容,为后续的 Transformer 层等处理提供更优质的特征表示。
15:如图所示,动作状态提示和图像嵌入,经过交叉注意力,自注意力,生成向量(n,d),动作三元组和图像嵌入,经过交叉注意力,自注意力,也生成向量(n,d),这两个向量在注意力融合模块中,是怎么工作的?

1:核心思路:“特征交互 + 自适应加权”
注意力融合的目的是让两个来源的特征(动作状态语义、动作三元组语义)相互增强,并自适应地确定各自在最终表示中的权重。常见做法是引入自注意力或交叉注意力,让两个特征矩阵之间进行交互,学习 “哪些位置的动作状态特征与动作三元组特征更相关”,再通过权重聚合得到融合结果。
2:具体步骤(以 “交叉注意力 + 加权求和” 为例)
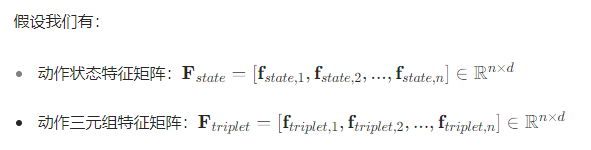
1:步骤 1:生成 Query、Key、Value

2:计算注意力得分

3:注意力权重归一化

4:加权融合 Value

3:双向增强与最终输出

4:直观举例(以 “人戴太阳镜” 场景为例)

这种设计的核心是让动作的 “抽象类型” 与 “具体执行细节” 语义相互增强,通过注意力的自适应加权,让模型更精准地理解 “动作在视觉上的完整表达”。
16:如图所示,动作状态提示和图像嵌入,经过交叉注意力,自注意力,生成向量(n,d),动作三元组和图像嵌入,经过交叉注意力,自注意力,也生成向量(n,d),这两个向量在MLP中是怎么工作的?请举例说明?

1:核心步骤:“拼接 → 非线性变换 → 输出”
MLP 的作用是对两个来源的特征(动作状态语义、动作三元组语义)进行深度融合与抽象,学习更具判别性的联合表示。假设我们有:
动作状态特征Vstate:包含 “太阳镜架在鼻子上,镜腿固定在耳后” 的细节语义。
动作三元组特征 Vtriplet:包含 “<man, wear, sunglasses>” 的抽象动作语义。
2:举例:“人戴太阳镜” 场景的 MLP 处理流程
1:步骤 1:特征拼接(Concatenation)

2:步骤 2:非线性变换(MLP 层)

3: MLP 输出的作用

3:总结
MLP 通过 “拼接 + 非线性变换”,将动作的 “抽象语义” 和 “具体执行细节” 深度融合,为后续模块提供更具表达力的特征,是 “从分开学到联合理解” 的关键步骤。
17:MLP输出的Vout和经过注意力融合产生的向量是怎么做matmul的,为什么要怎么做?

1:MatMul 生成 Action - aware Token

1:这个为什么是注意力融合模块输出的特征和注意力权重矩阵做加权,而不是用MLP 输出的特征和注意力权重矩阵做加权?
要理解 “为何用注意力融合模块的输出Fattn与权重 Wattn加权,而非 MLP 输出Fmlp”,需从两个模块的功能差异和加权的目的入手:
1:模块功能:注意力融合 vs MLP
注意力融合模块:核心是捕捉 “特征间的动态关联”(比如 “动作提示” 与 “图像嵌入” 哪些部分语义更相关)。输出的 Fattn本身就编码了 “不同特征间的关联模式”,是 “关联信息的载体”。
MLP 模块:核心是对特征进行 “非线性语义整合”(比如把 “动作状态” 和 “动作三元组” 的语义拼接后,用全连接层提取抽象语义)。输出的 Fmlp是 “语义内容的载体”,而非 “关联关系” 本身。
2:加权的目的:“强化关联信息”

3:直观举例(“人戴太阳镜” 场景)

4:总结
加权的核心是 “用 MLP 的语义去引导注意力关联的强化”,而 Fattn是 “关联信息的载体”,因此需要用Wattn加权Fattn,才能生成既包含 “关联模式” 又被 “语义引导” 的Action - aware Token。
2:总结
MatMul 的核心是通过计算特征间的相似度,生成动态权重,让 MLP 特征与注意力特征相互增强,最终提升模型对 “动作语义” 和 “视觉内容” 关联的建模能力。
18:MLP 融合的语义特征” 和 “注意力融合的关联特征有什么不同?他们代表了什么?举例说明。
1: 注意力融合的关联特征
1:核心逻辑:“动态捕捉特征间的关联关系”
注意力融合通过查询 - 键 - 值(QKV)机制,让不同来源的特征(如动作提示、图像嵌入)相互 “查询” 与 “响应”,重点捕捉 “哪些部分的特征在语义上更相关”。
2:代表意义:“特征间的动态关联模式”

2:MLP 融合的语义特征
1:核心逻辑:“非线性整合特征的语义内容”
MLP(多层感知机)通过全连接层 + 非线性激活,对多个特征进行 “拼接 - 变换 - 压缩”,重点整合特征的语义内容本身(而非特征间的关联方式)。
2:代表意义:“融合后的抽象语义表示”

3:两者差异总结(表格对比)

4:为什么需要两者结合?
注意力关联特征提供 “关联的方向”(知道该关注哪些部分);
MLP 语义特征提供 “内容的本质”(知道这些部分的语义是什么)。
结合后,模型既能 “知道该关注哪里”,又能 “知道关注的内容是什么”,从而更精准地理解 “动作在视觉中如何呈现”。
19:注意力融合模块输出的特征和MLP输出的特征做matmul,输出为Action-aware Token,这个Action-aware Token和可学习的视觉提示做Concatenate,具体是怎么做的?
1:与可学习视觉提示的 Concatenate
1:拼接的具体操作

2:可学习的视觉提示是什么?

3:可学习的视觉提示是从哪里来的?
可学习的视觉提示(Learnable Visual Prompts)是在模型训练过程中,由模型自身学习得到的一组参数化向量,其来源和学习逻辑可从以下角度理解:
1:来源:“模型初始化 + 训练优化”

2:学习的动力:“任务驱动的优化目标”

3:作用:“补充通用视觉先验”

4:与其他模块的关系

4:总结
可学习的视觉提示是模型在训练过程中,为了更好地完成 “动作 - 视觉” 相关任务,自主学习得到的一组通用视觉先验向量,其数值由任务损失驱动优化。
2:后续作用


这里是“一人公司”的成长家园。我们提供从产品曝光、技术变现到法律财税的全栈内容,并连接云服务、办公空间等稀缺资源,助你专注创造,无忧运营。
更多推荐



 12
12 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)