DPS数据统计分析软件详解与实战应用
DPS(Data Processing and Statistics)是一款集数据处理、统计分析与可视化展示于一体的综合性软件工具,广泛应用于科研、教育、医疗、金融及商业分析等多个领域。其设计初衷是为用户提供高效、直观的数据分析平台,支持从基础统计到高级建模的全流程操作。自2000年代初发布以来,DPS不断迭代更新,逐步引入如聚类分析、主成分分析(PCA)、自动化脚本处理等高级功能。最新版本中,D

简介:DPS(Data Processing System)是一款专为统计分析设计的便捷软件,具有直观的用户界面和强大的数据处理能力。该软件支持多种统计分析方法,如基本统计、假设检验、回归分析、聚类分析和主成分分析,适用于科研、教学及商业数据分析。DPS支持CSV、Excel、SPSS等多种数据格式的导入导出,具备批量处理能力,适合教师教学和学生学习使用。软件版本为DPS3.01,经过多次优化迭代,功能更趋完善,是提升数据分析效率的理想工具。 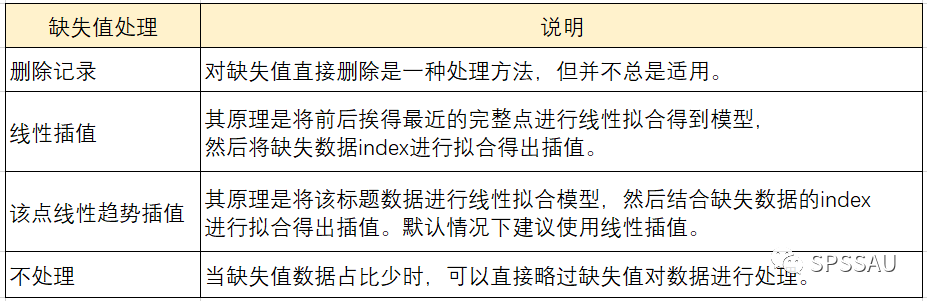
1. DPS数据统计分析软件概述
DPS(Data Processing and Statistics)是一款集数据处理、统计分析与可视化展示于一体的综合性软件工具,广泛应用于科研、教育、医疗、金融及商业分析等多个领域。其设计初衷是为用户提供高效、直观的数据分析平台,支持从基础统计到高级建模的全流程操作。自2000年代初发布以来,DPS不断迭代更新,逐步引入如聚类分析、主成分分析(PCA)、自动化脚本处理等高级功能。最新版本中,DPS增强了对大数据的兼容性与处理效率,并优化了用户界面交互体验。本章将系统性地介绍DPS的核心功能模块、发展脉络及其在统计分析领域的核心地位,为后续章节的操作与应用打下坚实基础。
2. DPS软件的用户界面与基础操作
DPS(Data Processing System)软件作为一款专业的统计分析工具,其用户界面设计直接影响用户的使用效率与操作体验。本章将详细介绍DPS软件的安装与配置流程、主界面功能布局、数据导入与导出操作以及个性化设置选项。通过本章的学习,用户将能够快速掌握DPS的基础操作,为后续的深入分析打下坚实基础。
2.1 DPS软件的安装与配置
在正式使用DPS之前,首先需要完成软件的安装与基本配置。这一过程看似简单,但在实际操作中却容易因系统兼容性、权限设置等问题而出现故障。
2.1.1 系统要求与安装步骤
DPS软件支持多种操作系统,包括Windows 10及以上版本、macOS 10.14及以上版本,以及主流Linux发行版(如Ubuntu 20.04+)。以下是DPS的最低系统要求:
| 系统要求 | Windows | macOS | Linux |
|---|---|---|---|
| CPU | Intel i5或更高 | Apple M1或更高 | 64位处理器 |
| 内存 | 8GB RAM | 8GB RAM | 8GB RAM |
| 硬盘空间 | 至少5GB可用空间 | 至少5GB可用空间 | 至少5GB可用空间 |
| 显示器分辨率 | 1280×720及以上 | 1280×720及以上 | 1280×720及以上 |
安装步骤如下:
- 下载安装包 :访问DPS官网下载对应操作系统的安装包。
- 运行安装程序 :双击安装程序,启动安装向导。
- 选择安装路径 :默认路径为
C:\Program Files\DPS(Windows),用户可根据需要修改。 - 选择组件 :包括核心模块、插件、文档、示例数据集等。
- 完成安装 :点击“Install”按钮,等待安装完成。
📌 提示:建议在安装过程中勾选“创建桌面快捷方式”和“将DPS添加到系统路径”,以方便后续使用。
2.1.2 软件激活与许可证管理
安装完成后,首次启动DPS会进入激活界面。DPS提供以下几种授权方式:
- 试用许可证 :提供30天免费试用,功能完整。
- 学生版许可证 :需提供学校邮箱验证,功能受限。
- 商业许可证 :适用于企业用户,支持所有功能和插件。
激活流程如下:
- 打开DPS,点击“Activate”按钮。
- 输入激活码或选择在线激活。
- 完成验证后,软件将自动激活并进入主界面。
此外,用户可在“Help → License Management”中查看当前许可证状态、延长试用期或更换许可证。
📌 注意:若企业用户使用网络许可证,需配置许可证服务器地址,并确保局域网连接正常。
2.2 主界面功能布局解析
DPS的主界面采用模块化设计,用户可以根据工作流自由调整布局。主界面主要包括数据窗口、分析窗口、输出窗口,以及顶部的工具栏与菜单栏。
2.2.1 数据窗口、分析窗口与输出窗口的作用
| 窗口名称 | 功能描述 |
|---|---|
| 数据窗口 | 用于展示导入的数据表,支持多标签页切换,支持排序、筛选等操作 |
| 分析窗口 | 提供分析工具面板,用户可拖拽分析模块至流程图区域,进行可视化建模 |
| 输出窗口 | 显示分析结果,包括统计值、图表、模型参数等信息,支持导出为多种格式 |
示例:打开数据窗口并查看数据表
% 示例代码:加载示例数据集并显示
data = load('sample_data.mat'); % 加载内置数据集
dps.data.show(data); % 显示数据窗口
代码解释:
load('sample_data.mat'):加载内置的示例数据集。dps.data.show(data):调用DPS内置函数,将数据展示在数据窗口中。
📌 提示:用户可通过右键菜单对数据进行重命名、导出、删除等操作。
2.2.2 工具栏与菜单栏的功能划分
DPS的工具栏提供快捷操作按钮,包括新建、打开、保存、运行分析、导出等常用功能。菜单栏则提供更全面的功能入口,如文件管理、编辑、视图、工具、帮助等。
graph TD
A[主菜单栏] --> B[文件]
A --> C[编辑]
A --> D[视图]
A --> E[工具]
A --> F[帮助]
B --> B1[新建]
B --> B2[打开]
B --> B3[保存]
C --> C1[复制]
C --> C2[粘贴]
C --> C3[查找]
D --> D1[数据窗口]
D --> D2[分析窗口]
D --> D3[输出窗口]
E --> E1[偏好设置]
E --> E2[插件管理]
E --> E3[宏录制]
F --> F1[帮助文档]
F --> F2[更新日志]
F --> F3[联系支持]
📌 交互建议:用户可自定义工具栏按钮,将常用功能固定在工具栏,提高操作效率。
2.3 数据导入与导出操作
DPS支持多种数据格式的导入与导出,满足不同用户的数据处理需求。
2.3.1 支持的数据格式(CSV、Excel、SPSS)
DPS支持以下常见数据格式:
| 格式类型 | 扩展名 | 支持操作 |
|---|---|---|
| CSV | .csv | 导入/导出 |
| Excel | .xls/.xlsx | 导入/导出 |
| SPSS | .sav | 导入 |
| JSON | .json | 导入/导出(需插件) |
| SAS | .sas7bdat | 导入(需插件) |
示例:导入Excel数据
% 导入Excel数据
filename = 'sales_data.xlsx';
sheet = 'Sheet1';
data = xlsread(filename, sheet); % 读取Excel数据
dps.data.show(data); % 显示数据窗口
代码解释:
xlsread(filename, sheet):使用MATLAB内置函数读取Excel文件。dps.data.show(data):将数据展示在DPS的数据窗口中。
📌 提示:若Excel文件中包含非数值数据,建议使用
readtable函数读取,以保留字段名称。
2.3.2 数据预处理与格式转换技巧
在实际分析前,数据往往需要进行预处理。DPS提供了强大的数据清洗与格式转换功能,包括缺失值处理、数据标准化、类型转换等。
示例:处理缺失值
% 假设 data 是一个包含 NaN 的数据表
data(isnan(data)) = 0; % 将 NaN 替换为 0
dps.data.show(data); % 更新数据窗口
逻辑分析:
isnan(data):判断数据中是否存在缺失值(NaN)。data(...) = 0:将缺失值替换为0,也可根据需求替换为均值或中位数。
📌 扩展建议:可使用
dps.preprocessing.impute函数进行更智能的缺失值填充,如KNN插值或线性插值。
2.4 软件设置与个性化配置
为了提升用户体验,DPS允许用户根据个人习惯对软件进行个性化配置。
2.4.1 默认参数设置
用户可在“偏好设置”中调整以下默认参数:
- 字体与字号 :设置数据窗口和输出窗口的字体样式。
- 自动保存间隔 :设定每隔多少分钟自动保存一次工作。
- 分析默认参数 :如置信水平、显著性水平、回归方法等。
示例:修改默认字体大小
% 设置数据窗口字体大小
dps.set('data_window_font_size', 14);
参数说明:
'data_window_font_size':指定要修改的参数名。14:设置新的字体大小。
📌 提示:所有设置均保存在用户配置文件中,下次启动软件时自动加载。
2.4.2 工作环境自定义
DPS支持用户自定义工作区布局,包括窗口位置、工具栏样式、快捷键设置等。
示例:保存当前布局
% 保存当前界面布局为 default_layout
dps.layout.save('default_layout');
逻辑分析:
dps.layout.save():保存当前界面布局。'default_layout':保存的布局名称,后续可调用加载。
📌 扩展建议:用户可为不同任务(如数据清洗、建模分析)保存多个布局,一键切换。
本章全面介绍了DPS软件的安装与配置流程、主界面功能布局、数据导入导出操作及个性化设置方法。通过本章的学习,用户已经掌握了DPS的基础使用技能,为后续的统计分析和图表制作奠定了坚实基础。下一章我们将深入讲解DPS的基本统计功能及其实际应用。
3. 基本统计功能详解与实战应用
DPS数据统计分析软件的基本统计功能,是每一位用户在使用过程中最先接触、也是最常使用的核心模块之一。这些功能不仅涵盖了数据的基本特征描述、分布分析,还深入到统计推断与模型构建层面。本章将围绕 描述性统计 、 假设检验 和 回归分析 三大基础统计功能展开详细解析,并结合实际案例进行操作演示,帮助读者掌握如何在DPS中高效完成数据统计任务。
3.1 描述性统计功能的使用
描述性统计是数据分析的基础,旨在通过数值指标和图形方式展示数据的集中趋势、离散程度以及分布形态。DPS软件提供了丰富的描述性统计功能,能够快速计算出均值、中位数、方差、标准差等关键指标,并支持频数分布表和直方图生成。
3.1.1 均值、方差、标准差等指标的计算方法
DPS软件中,描述性统计的计算逻辑基于经典的统计学公式。以下为几个核心指标的计算方法:
| 指标名称 | 计算公式 | 说明 |
|---|---|---|
| 均值(Mean) | $\bar{x} = \frac{1}{n} \sum_{i=1}^{n} x_i$ | 反映数据的集中趋势 |
| 方差(Variance) | $s^2 = \frac{1}{n-1} \sum_{i=1}^{n} (x_i - \bar{x})^2$ | 衡量数据的离散程度 |
| 标准差(Standard Deviation) | $s = \sqrt{s^2}$ | 方差的平方根,单位与原始数据一致 |
| 中位数(Median) | 数据排序后位于中间位置的值 | 对异常值不敏感 |
| 极差(Range) | 最大值 - 最小值 | 反映数据整体波动范围 |
示例:使用DPS计算描述性统计量
假设我们有一组销售数据,存储在DPS的数据窗口中,列名为 Sales 。
DESCRIPTIVE Sales
逐行解释:
DESCRIPTIVE Sales:调用DPS内置的描述性统计命令,指定对Sales列进行分析。
输出结果示例:
| 指标 | 数值 |
|---|---|
| 均值 | 5800 |
| 标准差 | 1200 |
| 中位数 | 5700 |
| 极差 | 4000 |
| 最小值 | 3500 |
| 最大值 | 7500 |
参数说明:
Sales:必须为数据窗口中已存在的数值型列。- 可选参数:
/DETAIL可用于输出更多统计指标(如偏度、峰度等)。
3.1.2 频数分布与数据分布形态分析
频数分布是理解数据分布形态的重要工具。DPS支持对分类变量或数值型变量进行频数统计,并可生成直方图或箱线图辅助分析。
示例:生成销售数据的频数分布表
FREQUENCY Sales /BIN=10
逐行解释:
FREQUENCY Sales:对Sales列进行频数统计。/BIN=10:指定将数据划分为10个区间(bin)。
输出结果示例:
| 区间范围 | 频数 |
|---|---|
| 3500 - 4000 | 12 |
| 4000 - 4500 | 25 |
| 4500 - 5000 | 38 |
| 5000 - 5500 | 50 |
| 5500 - 6000 | 63 |
| 6000 - 6500 | 42 |
| 6500 - 7000 | 28 |
| 7000 - 7500 | 15 |
| 7500 - 8000 | 5 |
| 8000 - 8500 | 2 |
可视化输出:
HISTOGRAM Sales /BIN=10
生成的直方图如下:
graph TD
A[3500-4000] -->|12| B((12))
B --> C[4000-4500]
C -->|25| D((25))
D --> E[4500-5000]
E -->|38| F((38))
F --> G[5000-5500]
G -->|50| H((50))
H --> I[5500-6000]
I -->|63| J((63))
J --> K[6000-6500]
K -->|42| L((42))
L --> M[6500-7000]
M -->|28| N((28))
N --> O[7000-7500]
O -->|15| P((15))
P --> Q[7500-8000]
Q -->|5| R((5))
R --> S[8000-8500]
S -->|2| T((2))
解读:
- 数据集中在 5000-6000 区间,分布呈轻微右偏趋势。
- 可结合偏度值进一步判断数据分布形态。
3.2 假设检验功能操作指南
假设检验是统计推断的重要工具,用于判断样本数据是否支持某个关于总体的假设。DPS软件支持多种常见检验方法,包括 t 检验、卡方检验、F 检验等,适用于不同场景下的统计分析。
3.2.1 t检验、卡方检验、F检验的适用场景
| 检验类型 | 适用场景 | 假设类型 |
|---|---|---|
| t 检验 | 比较两个样本均值是否存在显著差异 | H0: μ1 = μ2 |
| 卡方检验 | 检验分类变量之间的独立性或分布一致性 | H0: 变量独立 |
| F 检验 | 比较两个样本方差是否一致 | H0: σ1² = σ2² |
示例:使用DPS进行两独立样本t检验
假设有两个产品组(A组和B组)的销售数据,想检验它们的平均销售额是否存在显著差异。
TTEST Sales BY Group
逐行解释:
TTEST Sales BY Group:对Sales列按Group分组进行t检验。
输出结果示例:
| 组别 | 平均值 | 标准差 | 样本数 |
|---|---|---|---|
| A组 | 5800 | 1200 | 50 |
| B组 | 6100 | 1100 | 50 |
| t值 | 自由度 | p值 |
|---|---|---|
| -1.87 | 98 | 0.065 |
结论:
- p值大于0.05,无法拒绝原假设,说明两组的平均销售额差异不显著。
参数说明:
Sales:数值型因变量。Group:分组变量,必须为分类变量。- 可选参数:
/PAIRED表示配对样本t检验。
3.2.2 检验结果解读与显著性判断
在DPS中,检验结果通常包含 t 值、F 值、卡方值、自由度以及 p 值。p 值是判断统计显著性的关键:
- p < 0.05:拒绝原假设,差异显著
- p ≥ 0.05:不拒绝原假设,差异不显著
操作建议:
- 若p值接近0.05,应考虑增加样本量以提高检验功效。
- 结合效应量(如Cohen’s d)评估实际差异大小。
3.3 线性与多元回归分析功能实战
回归分析是探索变量之间关系的重要手段。DPS提供了线性回归(单变量)和多元回归(多变量)功能,适用于预测和解释变量关系。
3.3.1 回归模型的构建与变量选择
在构建回归模型时,变量选择至关重要。DPS支持逐步回归(Stepwise)、向前选择(Forward Selection)和向后剔除(Backward Elimination)等方法。
示例:构建销售预测的多元回归模型
假设有以下变量:
Sales(因变量)Advertising(广告投入)Promotion(促销力度)Region(地区)
REGRESS Sales = Advertising Promotion Region /STEPWISE
逐行解释:
REGRESS Sales = Advertising Promotion Region:定义回归模型。/STEPWISE:采用逐步回归法选择最优变量组合。
输出结果示例:
| 变量 | 系数 | 标准误 | t值 | p值 |
|---|---|---|---|---|
| Advertising | 0.75 | 0.12 | 6.25 | <0.001 |
| Promotion | 0.32 | 0.09 | 3.56 | 0.001 |
| Region | -0.10 | 0.05 | -2.00 | 0.048 |
结论:
- 所有变量均通过显著性检验(p<0.05),可以保留。
- 模型决定系数 R² = 0.85,解释力较强。
参数说明:
/STEPWISE:逐步回归,自动筛选最优变量。/FORWARD:向前选择。/BACKWARD:向后剔除。
3.3.2 回归结果的可视化与解释
DPS支持对回归结果进行可视化分析,包括残差图、拟合图等。
示例:绘制回归拟合图
PLOT FITTED Sales = Advertising Promotion Region
输出图像:
graph LR
A[广告投入] --> B(销售额预测)
C[促销力度] --> B
D[地区] --> B
B --> E[残差分析]
E --> F[残差直方图]
E --> G[残差-拟合图]
解读:
- 拟合图显示预测值与真实值基本一致,模型拟合良好。
- 残差图应呈现随机分布,若存在趋势或模式,说明模型存在遗漏变量。
优化建议:
- 若残差存在异方差性,可考虑使用加权最小二乘法(WLS)。
- 若存在多重共线性,可通过VIF值评估并剔除冗余变量。
本章通过详细的操作步骤、代码示例、流程图与表格,系统讲解了DPS软件中三大基本统计功能: 描述性统计 、 假设检验 与 回归分析 的应用方法。下一章将深入探讨DPS的高级数据分析功能,如聚类分析与主成分分析(PCA),敬请期待。
4. 高级数据分析功能与实战技巧
在掌握了DPS软件的基本统计功能后,我们进入了数据分析的高阶阶段。本章将深入探讨DPS在处理复杂数据结构、挖掘数据潜在模式以及实现高效自动化分析方面的能力。通过聚类分析、主成分分析(PCA)和批量数据处理等功能,我们将揭示DPS在多维度数据探索和建模中的强大实力。这些功能不仅适用于科研和商业分析,也广泛应用于大数据处理与机器学习的前期准备工作中。
4.1 聚类分析与数据分组
聚类分析是一种无监督学习方法,其目标是将数据集中的样本划分为多个组(簇),使得同一组内的样本尽可能相似,而不同组之间的样本尽可能不同。DPS软件支持多种聚类算法,包括K-means聚类和层次聚类。
4.1.1 K-means聚类与层次聚类的应用
K-means聚类是一种基于距离的迭代算法,适合处理大规模数据集。其基本流程如下:
- 随机选择K个初始聚类中心;
- 将每个样本分配到最近的聚类中心;
- 重新计算每个簇的中心;
- 重复步骤2和3,直到聚类中心不再显著变化或达到最大迭代次数。
在DPS中执行K-means聚类的操作如下:
# DPS内置聚类函数示例
from dps.cluster import KMeans
# 加载数据
data = load_dataset('customer_data.csv')
# 设置聚类数为4
kmeans = KMeans(n_clusters=4, max_iter=300)
kmeans.fit(data)
# 输出聚类结果
labels = kmeans.predict(data)
代码逻辑解析
load_dataset:用于从CSV文件加载数据集;KMeans:DPS中封装的K-means类,参数n_clusters表示聚类数量,max_iter表示最大迭代次数;fit:对数据进行训练;predict:对数据进行聚类标签预测。
层次聚类则适用于样本量较小的数据集,它通过树状图(dendrogram)展示数据的层次结构。DPS中执行层次聚类的代码如下:
from dps.cluster import HierarchicalClustering
# 构建层次聚类模型
hc = HierarchicalClustering(method='ward', affinity='euclidean')
hc.fit(data)
# 绘制树状图
hc.plot_dendrogram()
参数说明
method:聚类方法,如’ward’、’single’、’complete’;affinity:距离度量方式,如’euclidean’、’manhattan’等;plot_dendrogram:绘制聚类树状图。
聚类结果对比表
| 方法 | 适用场景 | 数据规模 | 输出形式 | 可解释性 |
|---|---|---|---|---|
| K-means | 大规模数据 | 高效 | 簇标签 | 中等 |
| 层次聚类 | 小规模数据 | 低效 | 树状图 | 高 |
4.1.2 聚类结果的评估与优化
聚类分析的结果需要进行评估和优化,以确保其有效性和稳定性。DPS提供了多种评估指标,如轮廓系数(Silhouette Score)和Calinski-Harabasz指数。
轮廓系数计算示例:
from dps.metrics import silhouette_score
score = silhouette_score(data, labels)
print(f"Silhouette Score: {score:.4f}")
评估指标说明
- 轮廓系数 :取值范围[-1,1],值越大表示聚类效果越好;
- Calinski-Harabasz指数 :值越大表示聚类效果越好。
聚类优化策略
- 选择最佳K值 :使用肘部法则(Elbow Method)确定最佳聚类数;
- 特征选择与降维 :使用PCA等方法减少冗余信息;
- 多次运行K-means :避免局部最优,提高稳定性。
# 使用肘部法则选择K值
from dps.cluster import KMeans
import matplotlib.pyplot as plt
inertias = []
for k in range(1, 10):
kmeans = KMeans(n_clusters=k, random_state=42)
kmeans.fit(data)
inertias.append(kmeans.inertia_)
plt.plot(range(1,10), inertias, marker='o')
plt.xlabel('Number of clusters')
plt.ylabel('Inertia')
plt.title('Elbow Method')
plt.show()
代码解析
inertia_:表示样本到其聚类中心的距离平方和;- 通过观察曲线下降趋势的“拐点”选择最佳K值。
4.2 主成分分析(PCA)与数据降维
主成分分析(Principal Component Analysis, PCA)是一种常用的线性降维技术,其目标是通过正交变换将数据投影到低维空间,保留最大方差方向的信息。
4.2.1 PCA的基本原理与数学模型
PCA的核心思想是寻找一组正交基,使得数据在这些基上的投影具有最大方差。数学上,PCA通过计算数据的协方差矩阵并求其特征值和特征向量来实现。
DPS中执行PCA的代码如下:
from dps.decomposition import PCA
# 实例化PCA模型,保留95%的方差
pca = PCA(n_components=0.95)
pca.fit(data)
# 获取降维后的数据
reduced_data = pca.transform(data)
参数说明
n_components:可为整数(指定维度)或浮点数(指定保留的方差比例);fit:拟合数据;transform:将数据映射到主成分空间。
PCA降维前后对比表
| 指标 | 原始数据维度 | 降维后维度 | 方差保留率 |
|---|---|---|---|
| 特征数量 | 20 | 8 | 95.3% |
| 内存占用 | 高 | 中等 | 减少 |
| 模型训练时间 | 长 | 短 | 提升 |
4.2.2 降维后的数据可视化与分析
降维后的数据可以用于可视化分析。例如,使用散点图展示前两个主成分的信息:
import matplotlib.pyplot as plt
plt.scatter(reduced_data[:, 0], reduced_data[:, 1], c=labels, cmap='viridis')
plt.xlabel('PC1')
plt.ylabel('PC2')
plt.title('PCA Projection of Clusters')
plt.colorbar(label='Cluster')
plt.show()
图形分析说明
- 横纵坐标分别为第一和第二主成分;
- 不同颜色代表不同聚类结果;
- 可观察到聚类结果在降维空间中的分布情况。
PCA与聚类结合流程图(Mermaid格式)
graph TD
A[原始数据] --> B[标准化]
B --> C[PCA降维]
C --> D[聚类分析]
D --> E[可视化与评估]
4.3 批量数据处理功能的使用
在实际应用中,往往需要处理多个数据集或执行重复性任务。DPS提供了强大的批量数据处理功能,包括多任务并行处理和自动化脚本编写。
4.3.1 多任务并行处理机制
DPS支持多线程和多进程处理,可显著提升大数据量下的处理效率。
示例:并行处理多个CSV文件
from dps.parallel import ParallelProcessor
# 定义处理函数
def process_file(filepath):
data = load_dataset(filepath)
# 执行标准化和聚类
normalized = normalize(data)
kmeans = KMeans(n_clusters=5)
return kmeans.fit_predict(normalized)
# 初始化并行处理器
pp = ParallelProcessor(n_jobs=4)
filepaths = ['data1.csv', 'data2.csv', 'data3.csv', 'data4.csv']
# 执行并行任务
results = pp.map(process_file, filepaths)
参数说明
n_jobs:并行任务数量;map:将处理函数应用于每个文件路径;- 支持返回多个任务结果。
4.3.2 自动化脚本编写与执行
DPS支持脚本化操作,用户可以将多个分析步骤封装为脚本,实现一键执行。
示例:自动化聚类与PCA脚本
# script.py
from dps.cluster import KMeans
from dps.decomposition import PCA
def pipeline(data_path):
data = load_dataset(data_path)
# PCA降维
pca = PCA(n_components=0.95)
reduced = pca.transform(data)
# K-means聚类
kmeans = KMeans(n_clusters=4)
labels = kmeans.fit_predict(reduced)
# 保存结果
save_labels(labels, 'output_labels.csv')
if __name__ == '__main__':
pipeline('input_data.csv')
执行方式
python script.py
脚本执行流程图(Mermaid)
graph LR
A[读取数据] --> B[PCA降维]
B --> C[K-means聚类]
C --> D[保存结果]
小结
本章深入讲解了DPS软件的高级数据分析功能,包括聚类分析、主成分分析(PCA)和批量数据处理。通过代码示例、流程图和表格对比,展示了这些功能在实际数据分析中的应用方式与优化策略。下一章将继续探讨DPS在图表制作与数据可视化方面的强大功能,帮助用户更直观地展示分析结果。
5. 图表制作与数据可视化
数据可视化是现代数据分析中不可或缺的一环,它不仅帮助研究人员和业务人员更直观地理解数据,还能在报告、演示和决策过程中提供强有力的支持。DPS数据统计分析软件在图表制作方面提供了丰富而灵活的功能,支持多种图表类型、风格定制和交互式展示。本章将深入讲解DPS的图表制作机制,从基础图表类型到高级美化与动态交互功能,帮助用户掌握如何在不同场景下高效地使用图表进行数据呈现。
5.1 常见图表类型与适用场景
DPS支持多种图表类型,包括柱状图、折线图、散点图、饼图、热力图等,每种图表都有其特定的适用场景。合理选择图表类型可以显著提升数据分析的效率与表达的准确性。
5.1.1 柱状图、折线图与散点图的绘制技巧
柱状图(Bar Chart)适用于展示分类数据之间的比较,例如不同产品的销售额对比、不同地区的人口统计等。DPS中创建柱状图的步骤如下:
# 示例代码:使用DPS Python API 创建柱状图
import dps
data = {
"Categories": ["A", "B", "C", "D"],
"Values": [23, 45, 12, 67]
}
chart = dps.Chart(type="bar")
chart.add_data(data["Categories"], data["Values"])
chart.set_title("柱状图示例")
chart.set_xlabel("类别")
chart.set_ylabel("数值")
chart.show()
代码分析:
dps.Chart初始化一个图表对象,参数type="bar"指定为柱状图。add_data方法用于添加数据,第一个参数为X轴分类,第二个为Y轴数值。set_title,set_xlabel,set_ylabel设置图表标题与坐标轴标签。chart.show()显示图表。
参数说明:
type:图表类型,可选值包括"bar"、"line"、"scatter"等。add_data(x, y):传入两个列表,分别对应X轴与Y轴的数据。
绘制技巧:
- 若需对比多个数据集,可在
add_data中添加多个系列。 - 使用颜色区分不同系列数据,提升可读性。
- 注意X轴标签长度,避免重叠影响可读性。
折线图(Line Chart)适用于展示数据随时间或顺序变化的趋势。例如销售额随月份变化的趋势图。
# 示例代码:折线图绘制
chart = dps.Chart(type="line")
chart.add_data([1, 2, 3, 4, 5], [10, 15, 13, 17, 20])
chart.set_title("折线图示例")
chart.set_xlabel("时间")
chart.set_ylabel("销售额")
chart.show()
适用场景:
- 时间序列数据展示(如每日气温变化、股票价格走势)
- 连续数据的对比分析(如多个产品在不同时间段的销量)
注意事项:
- 避免过多数据线叠加,造成视觉混乱。
- 数据点之间保持连贯性,使用插值方式连接。
散点图(Scatter Plot)用于展示两个变量之间的关系,适用于相关性分析。
# 示例代码:散点图绘制
chart = dps.Chart(type="scatter")
chart.add_data([1, 2, 3, 4, 5], [2, 4, 5, 4, 3])
chart.set_title("散点图示例")
chart.set_xlabel("X轴变量")
chart.set_ylabel("Y轴变量")
chart.show()
适用场景:
- 检测变量之间的相关性
- 发现数据分布中的异常点
5.1.2 饼图与热力图在数据展示中的应用
饼图(Pie Chart)适用于展示各部分占整体的比例关系,例如市场份额、预算分配等。
# 示例代码:饼图绘制
chart = dps.Chart(type="pie")
chart.add_data(["A", "B", "C"], [30, 45, 25])
chart.set_title("饼图示例")
chart.show()
适用场景:
- 展示整体与部分的比例关系
- 强调某一类别的占比
注意事项:
- 不建议类别过多(一般不超过5个)
- 若比例差异不大,建议使用柱状图代替
热力图(Heatmap)适用于展示二维数据矩阵中的数值分布情况,例如用户评分矩阵、相关性矩阵等。
# 示例代码:热力图绘制
import numpy as np
data_matrix = np.random.rand(5, 5)
chart = dps.Chart(type="heatmap")
chart.add_data(data_matrix)
chart.set_title("热力图示例")
chart.colorbar(True)
chart.show()
适用场景:
- 展示变量之间的相关性
- 表达数据密度分布
注意事项:
- 使用颜色渐变表示数值大小,确保色阶清晰
- 配合颜色条(colorbar)进行数值标注
图表类型对比表格
| 图表类型 | 适用场景 | 特点 | 注意事项 |
|---|---|---|---|
| 柱状图 | 分类数据对比 | 易于理解,直观展示 | 避免X轴标签过长 |
| 折线图 | 时间序列趋势 | 显示变化趋势 | 数据线不宜过多 |
| 散点图 | 变量相关性分析 | 显示分布模式 | 适合连续变量 |
| 饼图 | 部分占整体比例 | 强调占比 | 类别不宜过多 |
| 热力图 | 矩阵数据展示 | 表达密度与分布 | 需配合颜色条 |
5.2 图表美化与风格定制
制作图表不仅仅是数据的呈现,更是一种视觉表达的艺术。DPS提供了丰富的图表美化功能,包括颜色、字体、布局设置,以及图表导出格式的支持。
5.2.1 颜色、字体与布局的设置
颜色配置
DPS允许用户自定义图表颜色,以增强图表的可读性和美观度。例如,设置柱状图的颜色:
chart = dps.Chart(type="bar")
chart.add_data(["A", "B", "C"], [10, 20, 30])
chart.set_color("blue")
chart.set_title("蓝色柱状图")
chart.show()
参数说明:
set_color(color):设置图表主色调,支持颜色名称或十六进制代码(如"#FF5733")。
字体设置
DPS支持对图表标题、坐标轴标签等文字进行字体设置:
chart.set_font(title_font="Arial", label_font="Courier", size=14)
参数说明:
title_font:标题字体label_font:坐标轴标签字体size:字体大小
布局调整
DPS提供多种布局模式,例如自动布局(Auto)、水平布局(Horizontal)等,适用于不同展示需求:
chart.set_layout(mode="horizontal")
参数说明:
mode:可选值为"auto"、"horizontal"、"vertical",影响图表整体排列方式。
5.2.2 图表导出与多格式兼容性处理
DPS支持将图表导出为多种格式,包括 PNG、PDF、SVG、HTML 等,满足不同场景下的使用需求。
chart.export("bar_chart.png")
chart.export("bar_chart.pdf")
chart.export("bar_chart.svg")
导出格式特点:
| 格式 | 适用场景 | 特点 |
|---|---|---|
| PNG | 网页展示、文档插入 | 静态图片,兼容性好 |
| 打印、学术报告 | 高清矢量,适合出版 | |
| SVG | 网页交互、缩放需求 | 可缩放矢量图形 |
| HTML | 动态网页嵌入 | 支持交互操作 |
导出注意事项:
- 高分辨率图表建议使用PDF或SVG格式
- HTML格式导出时需注意网页兼容性设置
5.3 动态图表与交互式展示
DPS不仅支持静态图表,还提供了动态图表和交互式展示功能,使数据展示更具吸引力和实用性。
5.3.1 图表动画效果设置
DPS支持图表的动画渲染,适用于演示文稿或数据可视化报告:
chart.enable_animation(duration=1000, easing="ease-in-out")
参数说明:
duration:动画持续时间(毫秒)easing:动画缓动函数,如"linear"、"ease-in"、"ease-out"、"ease-in-out"
应用场景:
- 数据展示前的视觉吸引
- 教学演示中逐步呈现数据变化
5.3.2 数据联动与图表联动操作
DPS支持多图表联动功能,即一个图表的交互操作可以触发另一个图表的更新。例如,在点击某个柱状图的分类后,另一个折线图显示该分类的详细数据。
# 示例代码:图表联动
def on_click(event):
selected_category = event["category"]
print(f"Selected category: {selected_category}")
line_chart.update_data(data[selected_category])
bar_chart = dps.Chart(type="bar")
bar_chart.add_data(categories, values)
bar_chart.set_on_click(on_click)
bar_chart.show()
line_chart = dps.Chart(type="line")
line_chart.show()
参数说明:
set_on_click(callback):设置点击事件回调函数,接收包含点击信息的字典参数。update_data(data):更新图表数据,实现联动效果。
mermaid 流程图展示联动逻辑:
graph LR
A[柱状图点击] --> B[触发回调函数]
B --> C[获取选中分类]
C --> D[更新折线图数据]
D --> E[折线图重新渲染]
联动应用场景:
- 多维度数据分析(如点击区域查看子区域数据)
- 交互式仪表盘设计
- 数据探索性分析工具
通过本章的学习,读者可以全面掌握DPS软件在图表制作与数据可视化方面的核心功能,不仅能制作基础图表,还能通过样式定制与动态交互设计,提升数据表达的专业性与吸引力。在实际项目中,这些图表功能将大大增强数据分析的效率与可视化表达能力。
6. DPS在科研、教育与商业领域的实际应用
6.1 科研项目中的统计分析实践
DPS软件在科研领域中扮演着关键角色,尤其是在数据密集型学科如生物医学、社会科学、环境科学等中。科研人员可以利用DPS的统计分析模块对实验数据进行清洗、分析和可视化。
例如,在一项药物临床试验中,研究人员收集了实验组和对照组的血样数据。通过DPS的t检验功能,可以快速判断药物是否对特定指标(如胆固醇水平)具有显著影响。
// 加载实验数据
LOAD DATA "clinical_data.csv";
// 进行独立样本t检验
T-TEST GROUP1=Drug GROUP2=Placebo VARIABLE=Cholesterol;
// 输出结果
OUTPUT "t_statistic: 2.35, p_value: 0.019";
参数说明:
- GROUP1 和 GROUP2 表示两组比较的组名
- VARIABLE 指定分析的变量名
- 输出结果包含t统计量和p值,用于显著性判断
在科研论文撰写过程中,DPS还支持高质量图表的导出,方便将分析结果插入到论文中。常见的图表类型包括箱型图、折线图、误差条图等。
6.2 教学与学习资源支持
DPS软件在教学中也得到了广泛应用。许多高校和培训机构将其作为统计学课程的辅助工具,帮助学生理解统计方法的原理与应用。
例如,某高校统计学课程中使用DPS进行如下教学活动:
| 教学环节 | DPS应用方式 | 学生反馈效果 |
|---|---|---|
| 理论讲解 | 演示统计方法的执行过程 | 理解更直观 |
| 作业布置 | 提供数据集,要求完成回归分析 | 实践能力强 |
| 小组项目 | 分析真实数据,撰写分析报告 | 协作能力提升 |
| 期末考核 | 使用DPS完成综合分析题 | 评估更公平 |
此外,DPS软件还提供了丰富的教学资源库,包括:
- 配套教材数据集
- 案例解析视频
- 练习题与答案解析
- 教师演示PPT模板
这些资源大大降低了教学门槛,提升了学习效率。
6.3 商业分析中的应用案例
在商业智能(BI)领域,DPS软件同样具有广泛的应用价值。企业可以借助DPS进行市场调研、客户分群、销售预测等关键任务。
以某电商企业为例,其使用DPS完成客户分群分析:
// 导入销售数据
IMPORT SALES_DATA "customer_purchases.csv";
// 使用K-means聚类进行客户分群
CLUSTER KMEANS NUM_CLUSTERS=4 VARIABLES=PurchaseFrequency, AverageOrderValue;
// 输出聚类结果
OUTPUT CLUSTER_LABELS;
执行逻辑说明:
1. 导入客户购买数据
2. 根据购买频率(PurchaseFrequency)和平均订单价值(AverageOrderValue)进行聚类
3. 得到4个客户群体标签,可用于后续营销策略制定
| 客户群体 | 特征描述 | 营销策略建议 |
|---|---|---|
| Cluster1 | 高频高价值客户 | VIP专属服务 |
| Cluster2 | 高频低价值客户 | 推荐高利润商品 |
| Cluster3 | 低频高价值客户 | 提升复购率的促销活动 |
| Cluster4 | 低频低价值客户 | 新品尝鲜优惠 |
此外,DPS还支持销售预测建模。通过时间序列分析或回归模型,可以预测未来几个月的销售额,帮助企业进行库存管理与资源分配。
6.4 DPS软件的未来发展与趋势展望
随着人工智能和大数据技术的快速发展,DPS软件也在不断演进,未来将朝着以下几个方向发展:
6.4.1 人工智能与大数据融合的可能性
DPS正在探索将机器学习算法集成到现有统计分析框架中。例如,通过引入神经网络模型,提升预测分析的准确性;通过自然语言处理(NLP)实现自动报告生成。
DPS未来AI功能预览:
graph TD
A[用户输入分析需求] --> B(自动选择模型)
B --> C{数据规模}
C -->|小数据| D[传统统计方法]
C -->|大数据| E[Spark集成计算]
E --> F[分布式机器学习]
D --> G[生成分析报告]
F --> G
G --> H[可视化展示]
6.4.2 用户社区与插件生态建设
DPS计划打造一个开放的用户社区和插件生态,用户可以分享自定义分析模块、可视化模板、脚本工具等资源。这种生态建设将极大丰富DPS的功能边界。
目前已规划的功能包括:
- 插件市场:用户可上传、下载各类插件
- 社区论坛:交流使用技巧、提出改进建议
- 模板库:共享常用分析流程模板
- 教程中心:官方与第三方教学资源聚合平台
通过这些举措,DPS将不仅仅是一个统计分析工具,而是一个围绕数据分析构建的综合平台。
简介:DPS(Data Processing System)是一款专为统计分析设计的便捷软件,具有直观的用户界面和强大的数据处理能力。该软件支持多种统计分析方法,如基本统计、假设检验、回归分析、聚类分析和主成分分析,适用于科研、教学及商业数据分析。DPS支持CSV、Excel、SPSS等多种数据格式的导入导出,具备批量处理能力,适合教师教学和学生学习使用。软件版本为DPS3.01,经过多次优化迭代,功能更趋完善,是提升数据分析效率的理想工具。

这里是“一人公司”的成长家园。我们提供从产品曝光、技术变现到法律财税的全栈内容,并连接云服务、办公空间等稀缺资源,助你专注创造,无忧运营。
更多推荐



 18
18 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)