自动化测试-图像识别在项目UI巡检中的探索
背景:最近公司对系统进行频繁的迭代优化,有时会引发一些衰退性问题,有时会导致用户界面发生一些微妙的变化。而测试同学人手有限,不能每个界面都详细检查一遍,所以需要一个不知疲惫的“大冤种”,能够每天对界面进行一个巡检,最好能发现一些明显的问题现在图形识别与处理已经非常成熟,“找不同”的巡检方式自然可以交给自动化脚本去做,自动去比对发版前后的界面,找出差异点进行标注,然后发送结果报告
背景:最近公司对系统进行频繁的迭代优化,有时会引发一些衰退性问题,有时会导致用户界面发生一些微妙的变化。而测试同学人手有限,不能每个界面都详细检查一遍,所以需要一个不知疲惫的“大冤种”,能够每天对界面进行一个巡检,最好能发现一些明显的问题
现在图形识别与处理已经非常成熟,“找不同”的巡检方式自然可以交给自动化脚本去做,自动去比对发版前后的界面,找出差异点进行标注,然后发送结果报告
废话不多说,直接开干:
一、编写自动化收集界面截图的脚本(冤种机器人1号:每天按流程进入系统操作界面并截图保存)
采用python+selenium,进行数据驱动+关键字驱动
①界面元素我采用XPath进行定位,GUI小工具采用pyqt5编写,完成后就可以直接选择想要执行的脚本,然后就会操作浏览器自动登录系统进行检查了
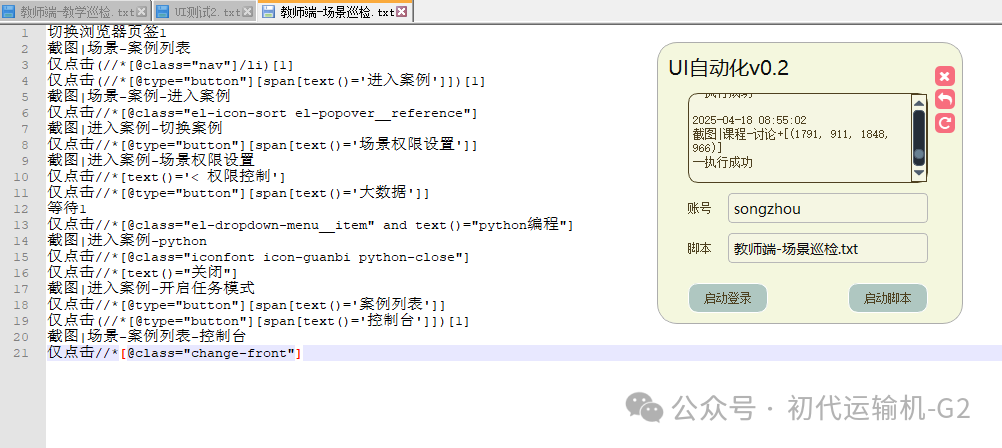
②执行脚本后,每个步骤的界面截图会保存在文件夹中,作为比对数据的来源
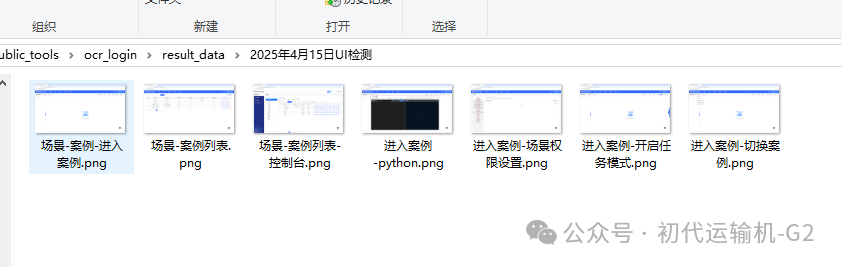
二、图像比对脚本(冤种机器人2号:对比两天的截图记录,找出不同)
比对的代码贴这里了,感兴趣的可以自取
import cv2
import numpy as np
import os # 新增导入os模块
from skimage.metrics import structural_similarity
from PIL import Image, ImageDraw, ImageFont
def compare_images_and_generate_report(img1_path, img2_path, output_path):
"""
比较两张图片并生成差异报告
:param img1_path: 第一张图片路径
:param img2_path: 第二张图片路径
:param output_path: 输出报告路径
:return: 相似度分数
"""
# 检查文件是否存在
for path in [img1_path, img2_path]:
if not os.path.exists(path):
raise FileNotFoundError(f"图片文件不存在: {path}")
# 读取图片
img1 = cv2.imdecode(np.fromfile(img1_path, dtype=np.uint8), cv2.IMREAD_COLOR)
img2 = cv2.imdecode(np.fromfile(img2_path, dtype=np.uint8), cv2.IMREAD_COLOR)
if img1 is None or img2 is None:
raise ValueError("图片读取失败,请检查文件格式")
# 预处理图片
if img1.shape != img2.shape:
img2 = cv2.resize(img2, (img1.shape[1], img1.shape[0]))
gray1 = cv2.cvtColor(img1, cv2.COLOR_BGR2GRAY)
gray2 = cv2.cvtColor(img2, cv2.COLOR_BGR2GRAY)
# 查找差异
score, diff = structural_similarity(gray1, gray2, full=True)
diff = (diff * 255).astype("uint8")
_, thresh = cv2.threshold(diff, 0, 255, cv2.THRESH_BINARY_INV | cv2.THRESH_OTSU)
contours, _ = cv2.findContours(thresh, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
diff_locations = []
for contour in contours:
if cv2.contourArea(contour) > 100:
x, y, w, h = cv2.boundingRect(contour)
diff_locations.append((x, y, x+w, y+h))
diff_img = cv2.drawContours(img1.copy(), contours, -1, (0, 0, 255), 2)
# 高亮显示差异区域
output = img2.copy()
print(f"检测到 {len(diff_locations)} 个差异区域")
output_pil = Image.fromarray(cv2.cvtColor(output, cv2.COLOR_BGR2RGB))
draw = ImageDraw.Draw(output_pil)
try:
font = ImageFont.truetype("simhei.ttf", 16)
except:
font = ImageFont.load_default()
print("警告:未找到中文字体,将使用默认字体")
for i, (x1, y1, x2, y2) in enumerate(diff_locations):
print(f"差异区域 {i+1}: ({x1},{y1})-({x2},{y2})")
draw.rectangle([x1, y1, x2, y2], outline=(255, 0, 0), width=2)
text = f'不同点 {i+1}'
text_width = font.getlength(text)
text_x = x1 + (x2-x1-text_width)//2
text_y = y1 - 20
draw.text((text_x, text_y), text, font=font, fill=(255, 0, 0))
diff_img = cv2.cvtColor(np.array(output_pil), cv2.COLOR_RGB2BGR)
# 生成报告
if diff_img is not None:
img1_copy = img1.copy()
img2_copy = img2.copy()
max_width = max(img1_copy.shape[1], img2_copy.shape[1], diff_img.shape[1])
def resize_to_width(img, target_width):
h, w = img.shape[:2]
return cv2.resize(img, (target_width, h), interpolation=cv2.INTER_LANCZOS4)
img1_copy = resize_to_width(img1_copy, max_width)
img2_copy = resize_to_width(img2_copy, max_width)
diff_img = resize_to_width(diff_img, max_width)
for img, name in [(img1_copy, "第一张图片"), (img2_copy, "第二张图片"), (diff_img, "比对结果")]:
img_pil = Image.fromarray(cv2.cvtColor(img, cv2.COLOR_BGR2RGB))
draw = ImageDraw.Draw(img_pil)
try:
font = ImageFont.truetype("simhei.ttf", 16)
except:
font = ImageFont.load_default()
draw.text((10, 10), name, font=font, fill=(255, 0, 0))
img[:] = cv2.cvtColor(np.array(img_pil), cv2.COLOR_RGB2BGR)
combined = np.vstack((img1_copy, img2_copy, diff_img))
ret, buf = cv2.imencode('.png', combined, [cv2.IMWRITE_PNG_COMPRESSION, 9])
if ret:
buf.tofile(output_path)
print(f"差异结果已保存至: {output_path}")
print(f"图片相似度: {score:.2%}")
if score < 1:
print("发现显著差异!")
else:
print("检测结果:基本一致")
return score
if __name__ == '__main__':
# 使用示例
similarity = compare_images_and_generate_report(
'D:/test_pic/测试1.png',
'D:/test_pic/测试2.png',
'D:/test_pic/测试结果.png'
)
print(similarity)
执行结果通过飞书以图文的形式进行汇报
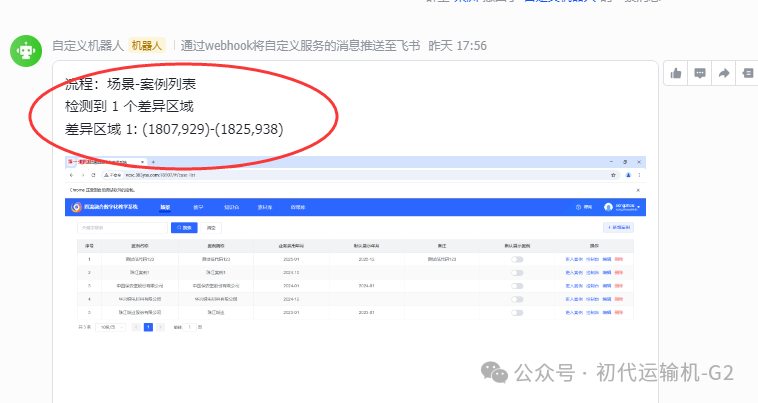
脚本将这两天比对结果中不同的地方用红色边框自动标注,并用“不同点XX”进行编号,这里发现一个差异,让我看看是怎么个回事,
为啥它会提示这里有差异?我猛地一看人都是蒙圈的,直到我把两张原图定位到这个区域并放大一看

好家伙!原来是这个图标在眨眼睛,第一天截图时眼睛睁开的很大,第二天截图时眼睛变小,前后发生了变化然后被检测出来了,看样子还得屏蔽掉界面里的动态效果和动图。不然逮到差异点就去diss开发同学,那误会就大了
继续改造,将动态区域自动用绿色框标注出来并排除,不参与对比
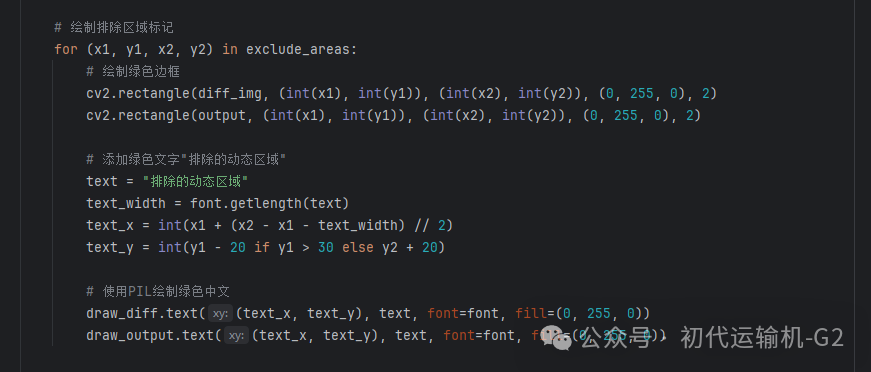

最后落地的效果,我们可以看到结果图里又发现了2个差异点
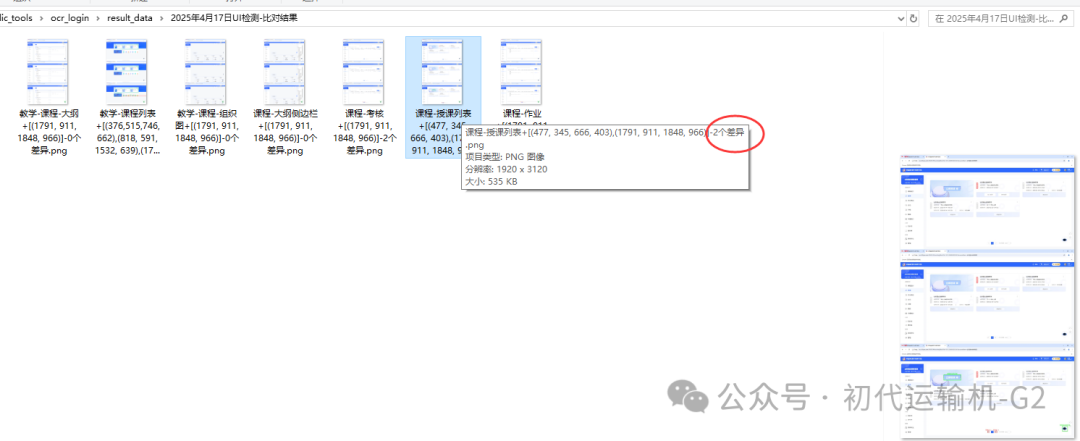
打开放大到底部可以对比看看:
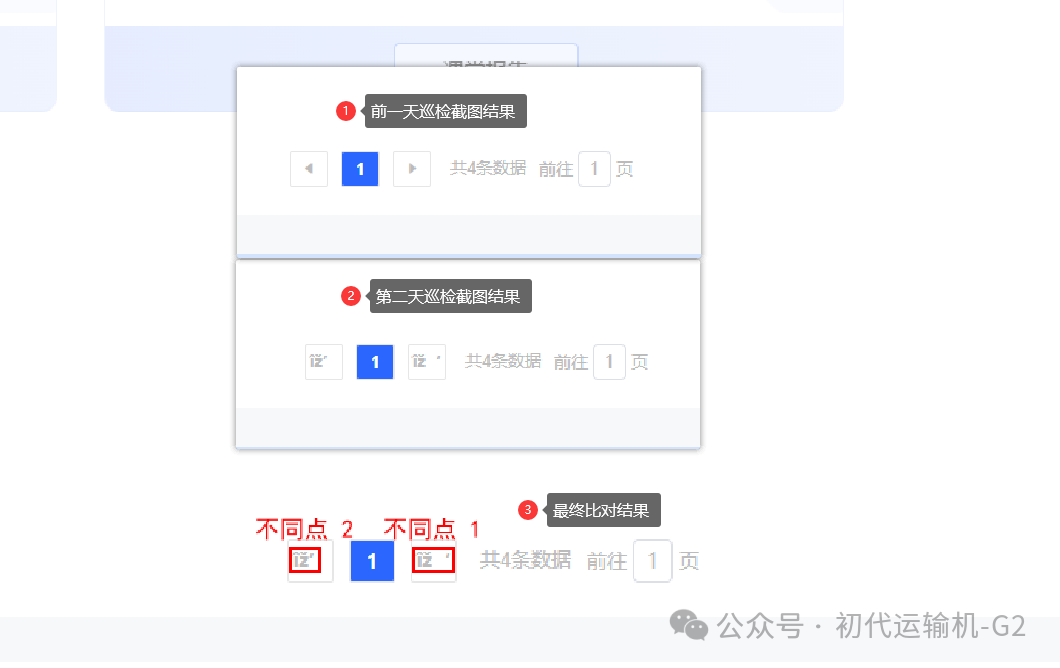
原来是列表底部的翻页组件图标展示异常被检测出来了,这个小细节平常测试同学是很难察觉到的
通过这个比对的检测,可以查出来这些问题:
①接口报错:比如toast弹窗提示了错误的message
②资源缺失:比如字体异常、icon显示异常等
③布局和样式的变化:比如按钮的位置等
三、其他构想(知识库+大模型)
假如后面数据采集的足够多了,可以进行问题分类然后交给模型,模型可以整体对项目的巡检结果进行分析,甚至后面出现问题截图给AI就可以定位是什么类型的问题,并告诉你之前在哪里也出现了同样的问题
完!

这里是“一人公司”的成长家园。我们提供从产品曝光、技术变现到法律财税的全栈内容,并连接云服务、办公空间等稀缺资源,助你专注创造,无忧运营。
更多推荐



 13
13 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)