HASH-RAG: 桥接深度哈希与检索器以实现高效、精细的检索和增强生成
检索增强生成(RAG)在扩展到大规模知识库时遇到效率挑战,同时需要保持上下文相关性。我们提出了Hash-RAG,一个将深度哈希技术与系统优化相结合的框架,以解决这些限制。我们的查询直接从知识库代码学习二进制哈希码,消除了中间特征提取步骤,并显著减少了存储和计算开销。基于这种哈希驱动的高效检索框架,我们建立了细粒度分块的基础。因此,我们设计了一个PromptGuided Chunk-to-Conte
郭金宇 1{ }^{1}1, 陈迅雷 1{ }^{1}1 夏琦洋 1{ }^{1}1, 王兆坤 1{ }^{1}1, 欧杰 1{ }^{1}1, 秦立波 2{ }^{2}2, 姚顺雨 2{ }^{2}2 田文洪 1{ }^{1}1
1{ }^{1}1 电子科技大学 2{ }^{2}2 中南大学
3{ }^{3}3 中国电信研究院大数据与人工智能研究所
guojinyu@uestc.edu.cn
摘要
检索增强生成(RAG)在扩展到大规模知识库时遇到效率挑战,同时需要保持上下文相关性。我们提出了Hash-RAG,一个将深度哈希技术与系统优化相结合的框架,以解决这些限制。我们的查询直接从知识库代码学习二进制哈希码,消除了中间特征提取步骤,并显著减少了存储和计算开销。基于这种哈希驱动的高效检索框架,我们建立了细粒度分块的基础。因此,我们设计了一个PromptGuided Chunk-to-Context(PGCC)模块,通过提示工程利用检索到的哈希索引命题及其原始文档段来增强LLM的上下文感知能力。实验评估显示,在NQ、TriviaQA和HotpotQA数据集上,我们的方法相比传统方法检索时间减少了90%,同时保持了合理的召回性能。此外,所提出的系统在EM分数上比检索/非检索基线高出1.4-4.3%。
1 引言
在数据迅速扩展的时代,越来越多的下游任务依赖于大语言模型(LLMs)。在这些任务中,检索增强生成(RAG)是一种流行的技术框架,它结合外部知识源来解决知识密集型问题(Lewis等人,2020)。通过将非参数化检索模块与主模型结合,RAG有效地缓解了大型模型中的幻觉问题(Yao等人,2022;Bang等人,2023)。此外,这种检索与生成机制扩展了LLMs在少量或零样本设置中的能力(Brown等人,2020;Chowdhery等人,2023),现在被广泛认为是解决传统LLMs事实不足的标准解决方案(Ma等人,2023)。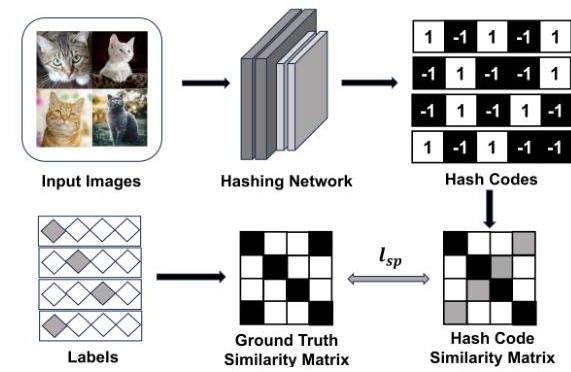
图1:深度监督哈希配对相似性的框架。该框架通过对齐哈希码与其相应真实值之间的成对关系来计算保留相似性的损失。
在RAG的有效性背后,巨大的知识库规模确保了输出的质量和专业性(Izacard等人,2023)。随着模型规模和知识数据量的快速增长,不断扩大的RAG知识库已成为一种趋势(Chen等人,2021)。鉴于此,知识库检索的效率和性能比以往任何时候都更加重要。
当前的研究已投入大量精力优化RAG系统中的检索过程。其中,几种方法专注于多轮检索迭代以获得更全面和高质量的内容(Yao等人,2023)。其他方法则通过任务特定或领域适应的模型微调来提高目标场景中的性能。替代策略涉及实施多样化的检索技术或聚合来自异构来源的信息(Huang等人,2023)。分块优化策略通过调整分块大小来改善检索结果的有效性,同时降低模型性能退化的风险(Sarthi等人,2024;Zhao等人,2024)。尽管在性能提升方面取得了进展,但RAG系统在知识库扩展时仍持续面临显著的效率挑战。
在大规模数据检索领域,近似最近邻(ANN)搜索因其在大多数情况下能够大幅减少搜索复杂度而备受关注(Do等人,2016;Wang等人,2017)。在ANN技术中(Luo等人,2021),哈希方法因其卓越的存储效率和快速检索能力而成为最广泛采用的方法之一(Cantini等人,2021)。特别是,深度哈希方法(Xia等人,2014)使用深度神经网络学习判别性特征表示,并将其转换为紧凑的哈希码,从而显著提高检索效率,同时减少存储需求和计算成本(Lai等人,2015)。这种方法在大规模图像检索方面取得了前所未有的突破,并显著优于传统方法(Chen等人,2021)。
在RAG时代,知识库的规模和增长速度远远超过传统的图像检索数据集。鉴于此,以哈希为代表的ANN技术因其能够快速定位结果并减少大规模数据处理中的计算复杂度而在RAG应用中展现出显著潜力。
在本文中,我们将基于ANN的技术引入RAG框架,并通过系统集成深度哈希方法提出Hash-RAG。具体而言,我们的架构通过符号函数操作将查询嵌入转换为二进制哈希码。对于知识库,我们采用不对称处理策略,通过直接学习二进制哈希码而不进行特征学习来优化训练效率。基于此,我们通过语料分块实现细粒度检索,从而过滤冗余内容同时保持精度。然而,我们注意到现有的分块方法导致检索到的片段缺乏必要的上下文信息,这极大地降低了生成输出的质量。为了解决这个问题,我们还提出了一个Prompt-Guided Chunk-to-Context(PGCC)模块,该模块将文档拆分为事实碎片(即命题)作为检索单元。这些命题以简洁、自包含的自然语言格式结构化,并索引到其原始文档。在生成过程中,LLM通过专门设计的提示处理基于哈希检索的命题及其上下文,从而在准确性和效率之间实现最佳协调。
我们在开放域问答数据集上进行了实验,包括Natural Questions(NQ)(Kwiatkowski等人,2019)、TRIVIAQA(Joshi等人,2017)和更复杂的多跳HOTPOTQA(Yang等人,2018)。实验结果表明,我们的模型显著减少了检索时间,仅需传统检索方法所需时间的10%,同时保持先进的召回性能。结合PGCC模块,我们在生成任务中实现了性能提升,同时保持效率。
本文的主要贡献如下:
- 我们提出了HASH-RAG,一个系统地将深度哈希整合到RAG中的框架,并通过阶段优化显著提高了大规模知识检索的计算效率,从而加速了整个RAG的端到端推理。
-
- 基于我们的哈希驱动高效检索框架,我们提出了PGCC模块,该模块通过基于提示的优化在实现细粒度检索的同时增强了上下文信息。
-
- 多个数据集上的实验结果表明,HASH-RAG显著提高了检索效率。结合PGCC模块,我们的方法在整体性能上超越了RAG基线模型,实现了效率和性能之间的最佳协调。
2 相关工作
2.1 检索增强生成
RAG通过非参数记忆集成减轻LLM的幻觉问题,并通过外部知识检索弥补事实缺陷(Gao等人,2023)。早期实现依赖于统计相似性度量(TF-IDF(Robertson和Walker,1997),BM25(Robertson等人,2009)),然后转向向量化表示(Karpukhin等人,2020),使系统具备可端到端调整的能力,具有情境感知的检索功能。近期的努力集中在两个阶段:
预检索查询-数据匹配以提高精确度(Ma等人,2023)和后检索内容重新排序或转换以优化生成器输入(Glass等人,2022)。一个持续的挑战在于分块策略的设计,平衡粒度权衡:粗粒度分块尽管上下文丰富但存在冗余风险(Shi等人,2023),而细粒度单位为精确度牺牲语义完整性(Raina和Gales,2024)。由于检索优化带来的可扩展性效率瓶颈,现在严重制约了RAG的发展。
2.2 深度哈希方法
近似最近邻(ANN)算法通过以效率换取精确度解决了大规模搜索低效的问题。不同于树状(Annoy(Bernhardsson,2015))、量化(PQ(Jegou等人,2010))或图状(HNSW(Malkov和Yashunin,2018))方法,哈希方法通过保持向量局部性减少了内存需求和搜索延迟,使其成为主流ANN解决方案。早期技术如局部敏感哈希(LSH)(Charikar,2002;Indyk和Motwani,1998)依赖于预定义映射进行哈希分桶,需要多个表才能达到满意的召回率。后来的学习哈希方法(例如,谱哈希(Weiss等人,2008),语义哈希(Salakhutdinov和Hinton,2009))优化了哈希函数以提高检索效率和准确性。当前研究聚焦于深度监督哈希方法(例如,卷积神经网络哈希(CNNH(Xia等人,2014):两阶段生成二进制码和训练卷积神经网络(CNNs),深度监督哈希(DSH(Liu等人,2016):带正则化的成对相似性损失以实现端到端训练,最大边缘汉明哈希(MMHH(Kang等人,2019):通过t分布和半批量优化增强辨别力)。这些方法展示了对大规模检索的适应性,为优化RAG的分块策略和检索效率奠定了技术基础。
在RAG时代,知识库的规模和增长速度远远超过传统图像检索数据集。鉴于此,以哈希为代表的ANN技术因其能够快速定位结果并减少大规模数据处理中的计算复杂度而在RAG应用中展现出显著潜力。
在本研究中,我们将基于ANN的技术引入RAG框架,并通过系统集成深度哈希方法提出Hash-RAG。具体而言,我们的架构通过符号函数操作将查询嵌入转换为二进制哈希码。对于知识库,我们采用不对称处理策略,通过直接学习二进制哈希码而不进行特征学习来优化训练效率。基于此,我们通过语料分块实现细粒度检索,从而过滤冗余内容同时保持精度。然而,我们注意到现有的分块方法导致检索到的片段缺乏必要的上下文信息,这极大地降低了生成输出的质量。为了解决这个问题,我们还提出了一个Prompt-Guided Chunk-to-Context(PGCC)模块,该模块将文档拆分为事实碎片(即命题)作为检索单元。这些命题以简洁、自包含的自然语言格式结构化,并索引到其原始文档。在生成过程中,LLM通过专门设计的提示处理基于哈希检索的命题及其上下文,从而在准确性和效率之间实现最佳协调。
我们在开放域问答数据集上进行了实验,包括Natural Questions(NQ)(Kwiatkowski等人,2019)、TRIVIAQA(Joshi等人,2017)和更复杂的多跳HOTPOTQA(Yang等人,2018)。实验结果表明,我们的模型显著减少了检索时间,仅需传统检索方法所需时间的10%,同时保持先进的召回性能。结合PGCC模块,我们在生成任务中实现了性能提升,同时保持效率。
本文的主要贡献如下:
- 我们提出了HASH-RAG,一个系统地将深度哈希整合到RAG中的框架,并通过阶段优化显著提高了大规模知识检索的计算效率,从而加速了整个RAG的端到端推理。
-
- 基于我们的哈希驱动高效检索框架,我们提出了PGCC模块,该模块通过基于提示的优化在实现细粒度检索的同时增强了上下文信息。
-
- 多个数据集上的实验结果表明,HASH-RAG显著提高了检索效率。结合PGCC模块,我们的方法在整体性能上超越了RAG基线模型,实现了效率和性能之间的最佳协调。
3 方法
在本研究中,我们提出了一种哈希检索增强生成(Hash-RAG)框架,这是一个从深度哈希和上下文增强的角度提升RAG的流水线。图2说明了Hash-RAG的综合架构。第3.1节和第3.2节分别介绍了基于哈希的检索器(HbR)和Prompt-Guided Chunk-to-Context(PGCC)模块。
3.1 基于哈希的检索器
基于哈希的编码器(HbE) HbE模块包含两个组件:查询编码器 EqE_{q}Eq 和命题编码器 EpE_{p}Ep,它们分别为查询 qqq 和命题 ppp(源自知识库文档分段)生成二进制哈希码。受ADSH启发,我们为查询和命题设计了不对称编码策略。查询编码器 EqE_{q}Eq 使用BERT-base-uncased作为其嵌入模型,将查询映射到ddd维向量空间(d=768)(d=768)(d=768)。查询嵌入向量 vq∈Rdv_{q} \in \mathbb{R}^{d}vq∈Rd:
vq=BERT(q,θ) v_{q}=B E R T(q, \theta) vq=BERT(q,θ)
其中θ\thetaθ表示BERT的参数。随后,通过哈希层的符号函数计算查询qqq的二进制哈希码:hq=sign(vq)h_{q}=\operatorname{sign}\left(v_{q}\right)hq=sign(vq)。为了应对符号函数的梯度消失问题,我们使用缩放的tanh函数进行逼近 Cao等人 (2017)。
hq~=tanh(βvq)∈{−1,1}l \widetilde{h_{q}}=\tanh \left(\beta v_{q}\right) \in\{-1,1\}^{l} hq =tanh(βvq)∈{−1,1}l
其中lll是固定的哈希码长度,β\betaβ是控制逼近平滑性的缩放超参数(β→∞\beta \rightarrow \inftyβ→∞收敛到符号函数)。我们设σ=0.1\sigma=0.1σ=0.1和β=σ⋅ step +1\beta=\sqrt{\sigma \cdot \text { step }+1}β=σ⋅ step +1,其中step计数已完成的训练步数。
命题编码器 EpE_{p}Ep 通过专用损失函数和交替优化策略直接学习二进制哈希码,无需嵌入模型训练,以减少训练开销。对于训练数据 Δ=\Delta=Δ= {⟨qi,pi+,{pi,j−}j=1n⟩}i=1m\left\{\left\langle q_{i}, p_{i}^{+},\left\{p_{i, j}^{-}\right\}_{j=1}^{n}\right\rangle\right\}_{i=1}^{m}{⟨qi,pi+,{pi,j−}j=1n⟩}i=1m 包含mmm个实例,监督矩阵 S∈{−1,1}m×(n+1)S \in\{-1,1\}^{m \times(n+1)}S∈{−1,1}m×(n+1) 标记正样本 (Si,j=1)\left(S_{i, j}=1\right)(Si,j=1) 和负样本 (Si,j=−1)\left(S_{i, j}=-1\right)(Si,j=−1)。我们最小化二进制码内积与监督信息之间的L2L_{2}L2损失:
LHbE=∑i=1m∑j=1n[hqi~−Thpj−lSij]2 \mathcal{L}_{H b E}=\sum_{i=1}^{m} \sum_{j=1}^{n}\left[\widetilde{h_{q_{i}}}^{-T} h_{p_{j}}-l S_{i j}\right]^{2} LHbE=i=1∑mj=1∑n[hqi −Thpj−lSij]2
其中hph_{p}hp表示命题哈希码。对于仅含命题的训练数据Δp={qj}j=1n\Delta_{p}=\left\{q_{j}\right\}_{j=1}^{n}Δp={qj}j=1n,我们通过从所有命题索引集合Γ={1,2,…,n}\Gamma=\{1,2, \ldots, n\}Γ={1,2,…,n}中随机抽样mmm个命题构造模拟查询,形成索引子集Ω=\Omega=Ω=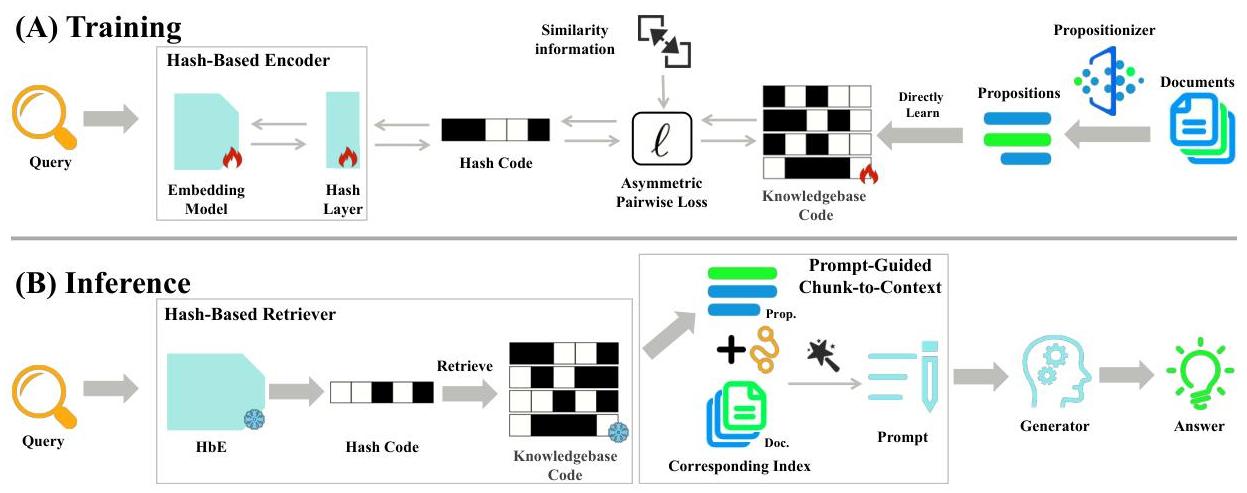 图2:框架概览。(a) 训练。基于哈希的编码器生成紧凑的查询哈希码,而知识库从事实分块的语料中创建二进制命题码。两个组件通过带有相似性约束的不对称成对损失联合优化。(b) 推理。基于哈希的检索器高效获取相关命题,并通过索引文档参考进行上下文接地。生成器通过优化提示从这些元素中合成证据以产生响应。
图2:框架概览。(a) 训练。基于哈希的编码器生成紧凑的查询哈希码,而知识库从事实分块的语料中创建二进制命题码。两个组件通过带有相似性约束的不对称成对损失联合优化。(b) 推理。基于哈希的检索器高效获取相关命题,并通过索引文档参考进行上下文接地。生成器通过优化提示从这些元素中合成证据以产生响应。
{i1,i2,…,im}⊆Γ\left\{i_{1},i_{2}, \ldots, i_{m}\right\} \subseteq \Gamma{i1,i2,…,im}⊆Γ. 扩展后的损失函数如下所示:
LHbE=∑i∈Ω∑j∈Γ[tanh(βvpi)Thpj−lSij]2+γ∑i∈Ω[hpj−tanh(βvpi)]2 \begin{aligned} \mathcal{L}_{H b E} & =\sum_{i \in \Omega} \sum_{j \in \Gamma}\left[\tanh \left(\beta v_{p_{i}}\right)^{T} h_{p_{j}}-l S_{i j}\right]^{2} \\ & +\gamma \sum_{i \in \Omega}\left[h_{p_{j}}-\tanh \left(\beta v_{p_{i}}\right)\right]^{2} \end{aligned} LHbE=i∈Ω∑j∈Γ∑[tanh(βvpi)Thpj−lSij]2+γi∈Ω∑[hpj−tanh(βvpi)]2
其中γ\gammaγ约束hpih_{p_{i}}hpi和hpi~=tanh(βvpi)\widetilde{h_{p_{i}}}=\tanh \left(\beta v_{p_{i}}\right)hpi =tanh(βvpi)尽可能接近,这使得通过迭代参数更新有效优化命题哈希码。
我们实施了一种交替优化策略,交替固定和更新神经网络参数θ\thetaθ和命题句哈希码矩阵H\boldsymbol{H}H。
固定H\boldsymbol{H}H更新θ\thetaθ 当H\boldsymbol{H}H固定时,我们计算LHbE\mathcal{L}_{H b E}LHbE相对于vpiv_{p_{i}}vpi的梯度:
∂LHbE∂vpi={2∑j∈Γ[(hpi~Thpj−lSij)hpj]+2γ(hpi~−hpi)}⊙(1−hpi~2) \begin{aligned} \frac{\partial \mathcal{L}_{H b E}}{\partial v_{p_{i}}} & =\left\{2 \sum_{j \in \Gamma}\left[\left(\widetilde{h_{p_{i}}}^{T} h_{p_{j}}-l S_{i j}\right) h_{p_{j}}\right]\right. \\ & \left.+2 \gamma\left(\widetilde{h_{p_{i}}}-h_{p_{i}}\right)\right\} \odot\left(1-\widetilde{h_{p_{i}}}^{2}\right) \end{aligned} ∂vpi∂LHbE=⎩ ⎨ ⎧2j∈Γ∑[(hpi Thpj−lSij)hpj]+2γ(hpi −hpi)}⊙(1−hpi 2)
链式法则将此梯度传播至BERT的参数θ\thetaθ,然后通过反向传播更新这些参数。
固定θ\thetaθ更新H\boldsymbol{H}H 当θ\thetaθ固定时,我们将公式4重写为矩阵形式:
LHbE=∥V~HT−lS∥F2+γ∥HΩ−V~∥F2=∥V~HT∥F2−2ltr(HTSTV~)−2γtr(HΩV~T)+ const \begin{aligned} \mathcal{L}_{H b E} & =\left\|\widetilde{\boldsymbol{V}} \boldsymbol{H}^{T}-l \boldsymbol{S}\right\|_{F}^{2}+\gamma\left\|\boldsymbol{H}^{\Omega}-\widetilde{\boldsymbol{V}}\right\|_{F}^{2} \\ & =\left\|\widetilde{\boldsymbol{V}} \boldsymbol{H}^{T}\right\|_{F}^{2}-2 l \operatorname{tr}\left(\boldsymbol{H}^{T} \boldsymbol{S}^{T} \widetilde{\boldsymbol{V}}\right) \\ & -2 \gamma \operatorname{tr}\left(\boldsymbol{H}^{\Omega} \widetilde{\boldsymbol{V}}^{T}\right)+\text { const } \end{aligned} LHbE= V HT−lS F2+γ HΩ−V F2= V HT F2−2ltr(HTSTV )−2γtr(HΩV T)+ const
其中V~=[vp1~,vp2~,…,vpm~]T∈[−1,+1]m×l\widetilde{\boldsymbol{V}}=\left[\widetilde{v_{p_{1}}}, \widetilde{v_{p_{2}}}, \ldots, \widetilde{v_{p_{m}}}\right]^{T} \in[-1,+1]^{m \times l}V =[vp1 ,vp2 ,…,vpm ]T∈[−1,+1]m×l,且HΩ=[hp1,hp2,…,hpm]T\boldsymbol{H}^{\Omega}=\left[h_{p_{1}}, h_{p_{2}}, \ldots, h_{p_{m}}\right]^{T}HΩ=[hp1,hp2,…,hpm]T表示采样的命题哈希码。
为了更新H\boldsymbol{H}H,我们采用逐列更新策略。对于第kkk列H∗k\boldsymbol{H}_{* k}H∗k,剩余矩阵H~k\widetilde{\boldsymbol{H}}_{k}H k(排除列kkk),以及第kkk列V~∗k\widetilde{\boldsymbol{V}}_{* k}V ∗k,剩余矩阵V~k\widetilde{\boldsymbol{V}}_{k}V k(排除列kkk),优化目标函数为:
L(H∗k)=tr(H∗k[2V∗k~TV~kHk~T+Q∗kT])+ const \begin{aligned} \mathcal{L}\left(\boldsymbol{H}_{* k}\right)= & \operatorname{tr}\left(\boldsymbol{H}_{* k}\left[2 \widetilde{\boldsymbol{V}_{* k}}^{T} \widetilde{\boldsymbol{V}}_{k} \widetilde{\boldsymbol{H}_{k}}^{T}+\boldsymbol{Q}_{* k}^{T}\right]\right) \\ & +\text { const } \end{aligned} L(H∗k)=tr(H∗k[2V∗k TV kHk T+Q∗kT])+ const
其中Q=−2lSTV~−2γV~\boldsymbol{Q}=-2 l \boldsymbol{S}^{T} \widetilde{\boldsymbol{V}}-2 \gamma \widetilde{\boldsymbol{V}}Q=−2lSTV −2γV ,其第kkk列为Q∗k\boldsymbol{Q}_{* k}Q∗k。最优解为:
H∗k=−sign(2H^kVk^TV∗k^+Q∗k) \boldsymbol{H}_{* k}=-\operatorname{sign}\left(2 \widehat{\boldsymbol{H}}_{k} \widehat{\boldsymbol{V}_{k}}^{T} \widehat{\boldsymbol{V}_{* k}}+\boldsymbol{Q}_{* k}\right) H∗k=−sign(2H kVk TV∗k +Q∗k)
θ\thetaθ和H\boldsymbol{H}H之间的交替优化通过多次迭代逐渐收敛,最终生成有效的查询哈希函数和稳健的命题哈希码。
3.2 Prompt-Guided Chunk-to-Context
检索单元粒度 我们采用信息瓶颈理论(Tishby等人,2000)来
优化检索单元选择,其中基于命题的分块在最大限度保留生成器相关信息的同时最小化噪声。给定文档XXX和生成器输出YYY之间的联合概率分布p(X,Y)p(X, Y)p(X,Y),我们通过互信息量化压缩命题X~\widetilde{X}X
中关于YYY的信息内容:
I(X~;Y)=∫X~∫Yp(x~,y)logp(x~,y)p(x~)p(y)dx~dy I(\widetilde{X} ; Y)=\int_{\widetilde{X}} \int_{\mathcal{Y}} p(\widetilde{x}, y) \log \frac{p(\widetilde{x}, y)}{p(\widetilde{x}) p(y)} d \widetilde{x} d y I(X ;Y)=∫X ∫Yp(x ,y)logp(x )p(y)p(x ,y)dx dy
压缩目标是最小化LIB=\mathcal{L}_{\mathrm{IB}}=LIB= I(X~;X)−βI(X~;Y)I(\widetilde{X} ; X)-\beta I(\widetilde{X} ; Y)I(X ;X)−βI(X ;Y),其中拉格朗日乘数β\betaβ平衡信息保留和压缩。与传统的句子/段落单元(Karpukhin等人,2020)不同,我们采用命题单元(Min等人,2023),捕捉原子语义表达。对于文档DocD o cDoc,我们提取kkk个相互关联的命题X=[x1,…,xk]X=\left[x_{1}, \ldots, x_{k}\right]X=[x1,…,xk],通过混合评分计算相关性得分:
Xf=αXdoc+(1−α)∑k=1nwkxk X_{f}=\alpha X_{d o c}+(1-\alpha) \sum_{k=1}^{n} w_{k} x_{k} Xf=αXdoc+(1−α)k=1∑nwkxk
其中XdocX_{d o c}Xdoc和xkx_{k}xk分别表示文档级和基于BERT的命题得分,α\alphaα和wkw_{k}wk通过交叉验证优化。
基于哈希的检索通过汉明距离关系优化命题选择:
distH(hqi,hpj)=12(d−⟨hqi,hpj⟩) \operatorname{dist}_{H}\left(h_{q_{i}}, h_{p_{j}}\right)=\frac{1}{2}\left(d-\left\langle h_{q_{i}}, h_{p_{j}}\right\rangle\right) distH(hqi,hpj)=21(d−⟨hqi,hpj⟩)
其中ddd是二进制码维度。我们通过迭代扩展汉明半径直到选择前α\alphaα个命题:
Top Pj=argmaxi∈{1,…,α}⟨vqi,hpj⟩ \text { Top } P_{j}=\arg \max _{i \in\{1, \ldots, \alpha\}}\left\langle v_{q_{i}}, h_{p_{j}}\right\rangle Top Pj=argi∈{1,…,α}max⟨vqi,hpj⟩
通过对命题-文档映射去重得到最终的前kkk个检索文档{Doc1,…,Dock}=\left\{D o c_{1}, \ldots, D o c_{k}\right\}={Doc1,…,Dock}=重复项(P1∪…∪Pj)\left(P_{1} \cup \ldots \cup P_{j}\right)(P1∪…∪Pj)。这种语义压缩和基于哈希的检索双重优化确保了最大限度提取信息并最小化噪声。
提示优化 我们采用LLAMA2作为生成器并使用优化后的提示。基于哈希的检索器识别出前- jjj个命题Pj=P_{j}=Pj= {P1,…,Pj}\left\{P_{1}, \ldots, P_{j}\right\}{P1,…,Pj}及其对应的文档索引DockD o c_{k}Dock,通过三个关键组件形成生成器的上下文:(1) 额外
提示指令将命题和索引文档的语义集成用于精确响应,(2) 检索段落包含按相似性排名的命题PjP_{j}Pj及其文档引用DocjD o c_{j}Docj,以及(3) 索引文档Doc1,…,DockD o c_{1}, \ldots, D o c_{k}Doc1,…,Dock提供上下文支持。
提示模板通过块到上下文激活生成器的能力:命题提供直接证据,而文档提供更广泛的上下文,使准确意图理解与平衡检索-上下文集成。详细信息见附录A。
4 实验
4.1 实验设置
数据集和检索语料库 我们在三个QA基准数据集的开发集上评估了我们的模型。这些数据集包含维基百科和网络来源的问题,代表了多样化的知识密集型任务:NQ (Kwiatkowski等人,2019) 和 TRIVIAQA (Joshi等人,2017) 评估直接知识回忆,而 HOTPOTQA (Yang等人,2018) 要求跨文档进行多跳推理。不同的检索粒度从句子到完整文档详见附录B。
指标 随着检索单元数量的增加,我们检索额外的命题,将它们映射到源文档,去重,并返回前kkk个唯一文档。我们使用文档召回@k和检索效率(索引大小/查询时间)进行评估。对于生成,Exact Match (EM) 评估地面实况是否完全出现在输出中。
实现细节 在我们的论文中,编码器(嵌入)使用BERT base、large、ALBERT和ALBERT,每个模型均使用官方预训练权重初始化。顶级jjj命题的数量固定为100。生成器(生成器)LLMs包括LLaMA2-7B和13B(Touvron等人,2023)。对于我们在主要实验中使用的HbR模型,训练批次大小设置为128 ,每个问题附加一个BM25负段落。每个编码器训练40个epoch,采用线性调度和预热,并设置丢弃率为0.1 。
基线 我们将HbR与BM25(Robertson等人,2009)、DPR(Karpukhin等人,2020)、SimCSE(Gao等人,2021)、Contriever(Izacard等人,2021)、模型增强矢量索引(MEVI)(Zhang等人,2024)、LSH(Charikar,2002)和DSH(Liu等人,2016)进行比较。
BM25(Robertson等人,2009)采用TF-
| 模型 | 前5名 | 前20名 | 前100名 | 索引 | 查询 | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| NQ | TQA | HQA | NQ | TQA | HQA | NQ | TQA | HQA | 大小 | 时间 | |
| BM25 | 45.2 | 55.7 | - | 59.1 | 66.9 | - | 73.7 | 76.7 | - | 7.4 | 913.8 |
| SimCSE | 28.8 | 44.9 | 26.7 | 44.3 | 59.4 | 44.1 | 47.0 | 62.4 | 46.1 | 64.6 | 548.2 |
| Contriever | 47.8 | 59.4 | 42.5 | 67.8 | 74.2 | 67.4 | 82.1 | 83.2 | 76.9 | 64.6 | 608.0 |
| MEVI †{}^{\dagger}† | 75.5 | - | - | 82.8 | - | - | 87.3 | - | - | 151.0 | 222.5 |
| DPR | 66.0 | 71.6 | 54.4 | 78.4 | 79.4 | 73.0 | 85.4 | 85.0 | 80.3 | 64.6 | 456.9 |
| LSH ‡{}^{\ddagger}‡ | 43.2 | 48.0 | 38.4 | 63.9 | 65.2 | 60.5 | 77.2 | 76.9 | 71.1 | 2.0 | 28.8 |
| DSH ‡{}^{\ddagger}‡ | 57.2 | 64.7 | 44.2 | 77.9 | 77.9 | 66.2 | 85.7 | 84.5 | 80.4 | 2.2 | 38.1 |
| HbR(我们的) | 72.4 | 78.3 | 57.7 | 80.3 | 87.0 | 80.2 | 87.5 | 88.4 | 81.4 | 4.6 | 42.3 |
| ±0.2\pm 0.2±0.2 | ±0.2\pm 0.2±0.2 | ±0.1\pm 0.1±0.1 | ±0.2\pm 0.2±0.2 | ±0.1\pm 0.1±0.1 | ±0.1\pm 0.1±0.1 | ±0.3\pm 0.3±0.3 | ±0.1\pm 0.1±0.1 | ±0.1\pm 0.1±0.1 |
表1:HbR和基线在测试集上的Top kkk召回率,附带索引大小(GB)和查询时间(ms)。†\dagger† 所选模型是MEVI Top-100 & HNSW来自主要实验。‡\ddagger‡ 集成哈希与编码器,选择DPR,DSH模型为哈希表查找,候选数=1000。
| 模型 | LLAMA2-7B | LLAMA2-13B | ||||
|---|---|---|---|---|---|---|
| NQ | TQA | HQA | NQ | TQA | HQA | |
| ToolFormer ⊖{ }^{\ominus}⊖ | 17.7 | 48.8 | 14.5 | 22.1 | 51.7 | 19.2 |
| RRR | 25.2 | 54.9 | 19.8 | 27.1 | 59.7 | 24.4 |
| FILCO | 25.8 | 55.0 | 19.4 | 27.3 | 60.4 | 23.9 |
| REPLUG ® { }^{\text {® }}R◯ | 27.1 | 57.1 | 20.5 | 29.4 | 62.7 | 26.8 |
| Hash-RAG | 28.5±0.1\mathbf{2 8 . 5}_{ \pm 0.1}28.5±0.1 | 57.1±0.1\mathbf{5 7 . 1}_{ \pm 0.1}57.1±0.1 | 22.1±0.2\mathbf{2 2 . 1}_{ \pm 0.2}22.1±0.2 | 34.9±0.2\mathbf{3 4 . 9}_{ \pm 0.2}34.9±0.2 | 64.5±0.1\mathbf{6 4 . 5}_{ \pm 0.1}64.5±0.1 | 31.1±0.3\mathbf{3 1 . 1}_{ \pm 0.3}31.1±0.3 |
表2:开放域问答的EM。⋄\diamond⋄ 本次实验中的生成模型涉及GPT系列,全部修改为LLAMA2系列,并且在本次实验中不训练阅读器。选择了Contriever和零样本设置。
IDF原则用于文档相关性排名,而DPR Karpukhin等人(2020) 利用双编码器架构;SimCSE Gao等人(2021),一种无监督学习架构,通过正/负对区分优化语义表示;Contriever Izacard等人(2021) 运用基于Transformer的编码器并优化对比损失函数;MEVI Zhang等人(2024) 运用残差量化(RQ)的聚类搜索语义文档;LSH的 Charikar(2002) 哈希-桶映射缩小最近邻搜索范围;DSH Liu等人(2016) 在哈希空间中集成深度特征提取与语义标签优化。
4.2 主要结果
表1展示了HbR在NQ、TQA和HotpotQA基准上的召回@k (k∈5,20,100)(k \in 5,20,100)(k∈5,20,100)和延迟。我们的框架将查询延迟减少到传统检索器的十分之一,同时实现了0.2-8.6%更高的召回@20/100。值得注意的是,HbR在k=20k=20k=20时达到最佳性能。虽然H-RAG在k=5k=5k=5时逊色于MEVI,但这种小-kkk场景是次要的,因为用户通常需要至少20个段落来生成答案。哈希机制即使在数据量因分块而增加的情况下也能保持索引大小优势。
接下来,表2比较了Hash-RAG与使用LLAMA2-7B/13B的基线RAG系统。我们的框架优于检索优化方法(FILCO Wang等人(2023),RRR Ma等人(2023))和LLAMA-Retrieval混合体(REPLUG Shi等人(2024)),所有检索增强模型都超过了Toolformer的非检索基线 Schick等人(2023)。通过向生成器提供前20个结果,我们优化地平衡了上下文体积和生成质量。这种设计选择利用了基于哈希检索和现代LLMs的互补优势,在所有基准上展示了显著的EM改进。
4.3 消融实验
编码器版本 我们研究了各种编码器版本(ALBERT,
| 模型 | 前5名 | 前20名 | 前100名 |
|---|---|---|---|
| ALBERT | 63.2 | 78.1 | 82.4 |
| Bert-base | 72.4 | 80.3 | 87.5 |
| RoBERTa | 72.6 | 84.7 | 87.6 |
| Bert-large | 73.1 | 85.8 | 87.9 |
表3:NQ数据集上使用不同版本嵌入模型的HbR的Top kkk召回率。
| 分块策略 | Recall@20 |
|---|---|
| 句子 | 62.9 |
| 段落 | 68.8 |
| 命题 | 80.2 |
| 提示优化 | EM |
| HbR w/ow/ow/o prop. | 25.3 |
| HbR w/ow/ow/o doc. | 24.8 |
| HbR | 29.4 |
| HbR w/w/w/ prompt (我们的) | 31.1 |
表4:HotpotQA数据集上不同分块策略和提示优化的指标(Recall@20和EM),其中prop.表示命题,doc.表示与检索到的命题相关的原始源文档。
Bert-base, Bert-large, RoBERTa) 与我们的模型的兼容性。如表3所示,命题级别的分块在Recall@20指标方面显著优于句子级别和段落级别的策略。尽管BERT-large实现了最高的Top-k召回率,为了与现有采用BERT-base作为编码器架构的模型进行公平比较,我们在实现中采用了相同的配置。
分块策略 表4中的性能层次结构表明,在Recall@20指标上,命题级别的分块分别超过了句子和段落级别的策略。实验分析显示,句子级别的分割破坏了谓词-论元的一致性,而段落级别的处理则引入了多余的內容。这种性能层次结构反映了命题级别分块的双重优势:保留自包含的语义单元并系统地消除上下文噪音。
提示优化 表4展示了我们对提示优化策略的比较分析,其中PGCC模块在经验上表现出优于所有基线的EM性能。值得注意的是,w/ow / ow/o doc. 配置优于w/ow / ow/o prop.,这表明即使在由优化提示引导的情况下,多跳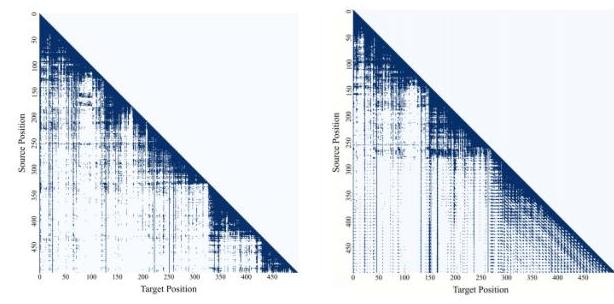
图3:提示引导注意力热图
数据集下,自包含的命题仍需通过源文档进行交叉验证。非提示配置由于支持LLM推理的足够上下文数据而达到次优性能,而提示集成则通过结构化注意力引导增强了模型对检索结果的关注。
5 分析
5.1 分块单元 & 提示引导
命题的信息瓶颈 为了展示HASH-RAG的分块策略如何利用信息瓶颈增强文本生成能力,我们分析了通过文档分段保留的内容。基于表5的实验分析揭示了压缩率与条件互信息 I(X^;X∣Y;Q)I(\hat{X} ; X \mid Y ; Q)I(X^;X∣Y;Q) 的简洁性之间的潜在相关性,比较了生成器、互信息度量和EM分数在不同上下文长度下的精确和贪婪搜索方法。我们提出将信息瓶颈原则应用于事实分块可以生成带有支持证据的简洁中间答案表示,从而在多跳查询中优于其他策略。这表明传统分块方法无法实现相当的信息密度优化。
提示对注意力的影响 为了研究提示如何影响LLM文本生成过程中的注意力机制,我们使用Recall@1来识别提供最佳事实支持的文档,从而验证提示优化的有效性。我们生成了对比注意力热图(图3),说明有无提示时模型的行为。无提示条件下的注意力集中在对角轴上的自我引用。相比之下,提示生成展示了关注命题标记 PjP_{j}Pj 的垂直注意力模式,并伴有显著的离对角线高亮,表明答案生成位置与关键命题之间加强了长距离依赖关系。
5.2 深度哈希算法的训练
时间复杂度 我们将我们的哈希方法与其他深度哈希基线在NQ数据集上进行比较,训练时间结果如图4所示。在我们的评估框架中,DSH(Liu等人,2016)和DHN(Zhu等人,2016)代表在10,000个采样数据点上训练的传统深度哈希基线,而DSH-D和DHN-D则表示其全数据库版本。结果显示,基线的全数据库训练需要超过80分钟才能收敛,这启发了大规模数据集的采样训练。此外,我们的方法比采样和全数据库基线更快收敛,同时保持最高精度。
参数敏感性 图5展示了NQ数据集上24位码的哈希超参数 γ\gammaγ 敏感性。我们的方法在广泛范围内 (1<γ<500)(1<\gamma<500)(1<γ<500) 显示稳定性,平均平均精度(MAP)波动在0.01以内。这可能归因于NQ的分层语义结构,表现出对哈希引起的局部扰动的容忍性。这种参数不变性降低了部署优化复杂性,同时确保多场景可靠性。
结论
我们将深度哈希与检索增强生成相结合,以实现高效、细粒度的知识检索和情境增强生成,平衡查询处理时间和召回之间的权衡。不仅作为一个哈希检索器的评估框架,我们提出的PGCC模块通过优化分块策略和解决上下文信息限制进一步提高了检索的准确性和相关性。实验结果表明,我们的哈希检索器显著优于基线方法,并在生成器中取得了令人印象深刻的指标。在未来的工作中,我们计划探索哈希技术在其他任务和结构中的应用,例如知识图谱。
局限性
本文的重点是深入整合深度哈希技术与RAG模型。实验框架假设外部知识库是静态的。如果需要增量更新,例如添加新文档或修订内容,则需要重新训练哈希编码器以纳入新数据,这在计算上是昂贵的。未来,开发动态哈希编码的有效适应策略仍然是一个开放的挑战。
参考文献
Yejin Bang, Samuel Cahyawijaya, Nayeon Lee, Wenliang Dai, Dan Su, Bryan Wilie, Holy Lovenia, Ziwei Ji, Tiezheng Yu, Willy Chung, et al. 2023. A multitask, multilingual, multimodal evaluation of chatgpt on reasoning, hallucination, and interactivity. arXiv preprint arXiv:2302.04023.
Erik Bernhardsson. 2015. Annoy (approximate nearest neighbors oh yeah). URL https://github.com/spotify/annoy.
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. 2020. Language models are few-shot learners. Advances in neural information processing systems, 33:1877-1901.
Riccardo Cantini, Fabrizio Marozzo, Giovanni Bruno, and Paolo Trunfio. 2021. Learning sentence-to-hashtags semantic mapping for hashtag recommendation on microblogs. ACM Transactions on Knowledge Discovery from Data (TKDD), 16(2):1-26.
Zhangjie Cao, Mingsheng Long, Jianmin Wang, and Philip S Yu. 2017. Hashnet: Deep learning to hash by continuation. In Proceedings of the IEEE international conference on computer vision, pages 56085617 .
Moses S Charikar. 2002. Similarity estimation techniques from rounding algorithms. In Proceedings of the thirty-fourth annual ACM symposium on Theory of computing, pages 380-388.
Qi Chen, Bing Zhao, Haidong Wang, Mingqin Li, Chuanjie Liu, Zengzhong Li, Mao Yang, and Jingdong Wang. 2021. Spann: Highly-efficient billionscale approximate nearest neighborhood search. Advances in Neural Information Processing Systems, 34:5199-5212.
Aakanksha Chowdhery, Sharan Narang, Jacob Devlin, Maarten Bosma, Gaurav Mishra, Adam Roberts, Paul Barham, Hyung Won Chung, Charles Sutton, Sebastian Gehrmann, et al. 2023. Palm: Scaling language modeling with pathways. Journal of Machine Learning Research, 24(240):1-113.
Thanh-Toan Do, Anh-Dzung Doan, and Ngai-Man Cheung. 2016. Learning to hash with binary deep neural network. In Computer Vision-ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, October 11-14, 2016, Proceedings, Part V 14, pages 219-234. Springer.
T Gao, X Yao, and Danqi Chen. 2021. Simcse: Simple contrastive learning of sentence embeddings. In EMNLP 2021-2021 Conference on Empirical Methods in Natural Language Processing, Proceedings.
Yunfan Gao, Yun Xiong, Xinyu Gao, Kangxiang Jia, Jinliu Pan, Yuxi Bi, Yi Dai, Jiawei Sun, and Haofen Wang. 2023. Retrieval-augmented generation for large language models: A survey. arXiv preprint arXiv:2312.10997.
Michael Glass, Gaetano Rossiello, Md Faisal Mahbub Chowdhury, Ankita Rajaram Naik, Pengshan Cai, and Alfio Gliozzo. 2022. Re2g: Retrieve, rerank, generate. In Annual Conference of the North American Chapter of the Association for Computational Linguistics.
Wenyu Huang, Mirella Lapata, Pavlos Vougiouklis, Nikos Papasarantopoulos, and Jeff Pan. 2023. Retrieval augmented generation with rich answer encoding. In Proceedings of the 13th International Joint Conference on Natural Language Processing and the 3rd Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1012-1025.
Piotr Indyk and Rajeev Motwani. 1998. Approximate nearest neighbors: towards removing the curse of dimensionality. In Proceedings of the thirtieth annual ACM symposium on Theory of computing, pages 604-613.
Gautier Izacard, Mathilde Caron, Lucas Hosseini, Sebastian Riedel, Piotr Bojanowski, Armand Joulin, and Edouard Grave. 2021. Unsupervised dense information retrieval with contrastive learning.
Gautier Izacard, Patrick Lewis, Maria Lomeli, Lucas Hosseini, Fabio Petroni, Timo Schick, Jane DwivediYu, Armand Joulin, Sebastian Riedel, and Edouard Grave. 2023. Atlas: Few-shot learning with retrieval augmented language models. Journal of Machine Learning Research, 24(251):1-43.
Herve Jegou, Matthijs Douze, and Cordelia Schmid. 2010. Product quantization for nearest neighbor search. IEEE transactions on pattern analysis and machine intelligence, 33(1):117-128.
Qing-Yuan Jiang and Wu-Jun Li. 2018. Asymmetric deep supervised hashing. In Proceedings of the AAAI conference on artificial intelligence, volume 32.
Mandar Joshi, Eunsol Choi, Daniel S Weld, and Luke Zettlemoyer. 2017. Triviaqa: A large scale distantly supervised challenge dataset for reading comprehension. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1601-1611.
Rong Kang, Yue Cao, Mingsheng Long, Jianmin Wang, and Philip S Yu. 2019. Maximum-margin hamming hashing. In Proceedings of the IEEE/CVF international conference on computer vision, pages 82528261 .
Vladimir Karpukhin, Barlas Oğuz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih. 2020. Dense passage retrieval for open-domain question answering. arXiv preprint arXiv:2004.04906.
Jacob Devlin Ming-Wei Chang Kenton and Lee Kristina Toutanova. 2019. Bert: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of naacL-HLT, volume 1. Minneapolis, Minnesota.
Tom Kwiatkowski, Jennimaria Palomaki, Olivia Redfield, Michael Collins, Ankur Parikh, Chris Alberti, Danielle Epstein, Illia Polosukhin, Jacob Devlin, Kenton Lee, et al. 2019. Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics, 7:453466.
Hanjiang Lai, Yan Pan, Ye Liu, and Shuicheng Yan. 2015. Simultaneous feature learning and hash coding with deep neural networks. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 3270-3278.
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, et al. 2020. Retrieval-augmented generation for knowledge-intensive nlp tasks. Advances in Neural Information Processing Systems, 33:94599474 .
Haomiao Liu, Ruiping Wang, Shiguang Shan, and Xilin Chen. 2016. Deep supervised hashing for fast image retrieval. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 2064-2072.
Xiao Luo, Daqing Wu, Chong Chen, Jinwen Ma, and Minghua Deng. 2021. Deep unsupervised hashing by global and local consistency. In 2021 IEEE International Conference on Multimedia and Expo (ICME), pages 1-6. IEEE.
Xinbei Ma, Yeyun Gong, Pengcheng He, Hai Zhao, and Nan Duan. 2023. Query rewriting in retrievalaugmented large language models. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 5303-5315.
Yu A Malkov and Dmitry A Yashunin. 2018. Efficient and robust approximate nearest neighbor search using hierarchical navigable small world graphs. IEEE transactions on pattern analysis and machine intelligence, 42(4):824-836.
Sewon Min, Kalpesh Krishna, Xinxi Lyu, Mike Lewis, Wen-tau Yih, Pang Koh, Mohit Iyyer, Luke Zettlemoyer, and Hannaneh Hajishirzi. 2023. Factscore: Fine-grained atomic evaluation of factual precision in long form text generation. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 12076-12100.
Vatsal Raina and Mark Gales. 2024. Question-based retrieval using atomic units for enterprise rag. arXiv preprint arXiv:2405.12363.
Stephen Robertson, Hugo Zaragoza, et al. 2009. The probabilistic relevance framework: Bm25 and beyond. Foundations and Trends ®{ }^{\circledR}® in Information Retrieval, 3(4):333-389.
Stephen E Robertson and Steve Walker. 1997. On relevance weights with little relevance information. In Proceedings of the 20th annual international ACM SIGIR conference on Research and development in information retrieval, pages 16-24.
Ruslan Salakhutdinov and Geoffrey Hinton. 2009. Semantic hashing. International Journal of Approximate Reasoning, 50(7):969-978.
Parth Sarthi, Salman Abdullah, Aditi Tuli, Shubh Khanna, Anna Goldie, and Christopher D Manning. 2024. Raptor: Recursive abstractive processing for tree-organized retrieval. arXiv preprint arXiv:2401.18059.
Timo Schick, Jane Dwivedi-Yu, Roberto Dessì, Roberta Raileanu, Maria Lomeli, Eric Hambro, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom. 2023. Toolformer: Language models can teach themselves to use tools. Advances in Neural Information Processing Systems, 36:68539-68551.
Freda Shi, Xinyun Chen, Kanishka Misra, Nathan Scales, David Dohan, Ed H Chi, Nathanael Schärli, and Denny Zhou. 2023. Large language models can be easily distracted by irrelevant context. In International Conference on Machine Learning, pages 31210-31227. PMLR.
Weijia Shi, Sewon Min, Michihiro Yasunaga, Minjoon Seo, Richard James, Mike Lewis, Luke Zettlemoyer, and Wen-tau Yih. 2024. Replug: Retrievalaugmented black-box language models. In Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pages 8364-8377.
Naftali Tishby, Fernando C Pereira, and William Bialek. 2000. The information bottleneck method. arXiv preprint physics/0004057.
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. 2023. Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288.
Jingdong Wang, Ting Zhang, Nicu Sebe, Heng Tao Shen, et al. 2017. A survey on learning to hash. IEEE transactions on pattern analysis and machine intelligence, 40(4):769-790.
Zhiruo Wang, Jun Araki, Zhengbao Jiang, Md Rizwan Parvez, and Graham Neubig. 2023. Learning to filter context for retrieval-augmented generation. arXiv preprint arXiv:2311.08377.
Yair Weiss, Antonio Torralba, and Rob Fergus. 2008. Spectral hashing. Advances in neural information processing systems, 21.
Rongkai Xia, Yan Pan, Hanjiang Lai, Cong Liu, and Shuicheng Yan. 2014. Supervised hashing for image retrieval via image representation learning. In Proceedings of the AAAI conference on artificial intelligence, volume 28.
Zhilin Yang, Peng Qi, Saizheng Zhang, Yoshua Bengio, William Cohen, Ruslan Salakhutdinov, and Christopher D Manning. 2018. Hotpotqa: A dataset for diverse, explainable multi-hop question answering. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 2369−23802369-23802369−2380.
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. 2022. React: Synergizing reasoning and acting in language models. arXiv preprint arXiv:2210.03629.
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. 2023. React: Synergizing reasoning and acting in language models. In International Conference on Learning Representations (ICLR).
Hailin Zhang, Yujing Wang, Qi Chen, Ruiheng Chang, Ting Zhang, Ziming Miao, Yingyan Hou, Yang Ding, Xupeng Miao, Haonan Wang, et al. 2024. Modelenhanced vector index. Advances in Neural Information Processing Systems, 36.
Penghao Zhao, Hailin Zhang, Qinhan Yu, Zhengren Wang, Yunteng Geng, Fangcheng Fu, Ling Yang, Wentao Zhang, and Bin Cui. 2024. Retrievalaugmented generation for ai-generated content: A survey. arXiv preprint arXiv:2402.19473.
Han Zhu, Mingsheng Long, Jianmin Wang, and Yue Cao. 2016. Deep hashing network for efficient similarity retrieval. In Proceedings of the AAAI conference on Artificial Intelligence, volume 30.
A 提示模板
针对LLaMA-2-7B的开放域问答
请考虑检索段落中的所有相关细节,并提供简洁、信息丰富且上下文适当的响应。如有必要,仔细查阅对应的索引文档,仅用几个词支持您的回答:
IdxID:23 标题:珠穆朗玛峰
命题:珠穆朗玛峰是地球上高于海平面的最高峰。
IdxID:23 标题:珠穆朗玛峰
命题:珠穆朗玛峰在藏语中被称为圣母峰。
IdxID:59 标题:拉萨藏语
命题:藏语中的动词总是位于从句的末尾。
ID=23 标题:珠穆朗玛峰
文档:珠穆朗玛峰,当地称为萨加玛塔或珠穆朗玛峰,[注4] 是地球上高于海平面的最高峰,位于喜马拉雅山脉的马哈兰格子山群。中国-尼泊尔边界
ID=59 标题:拉萨藏语
文档:在传统的“三分支”分类法中,藏语拉萨方言属于中央藏语分支(另外两个为康巴藏语和安多藏语)。[4] 在
问题:世界上最高的山是什么?
答案是:珠穆朗玛峰
B 数据集
B. 1 数据集统计
我们使用三个从维基百科文章构建的数据集作为回答、回应和判断生成的支持文档,如表6所示。
| 数据集 | 示例数量 | ||
|---|---|---|---|
| 训练 | 开发 | 测试 | |
| NQ | 79.2 | 8.7 | 3.6 |
| TQA | 78.8 | 8.8 | 11.3 |
| HOTPOTQA | 88.9 | 5.6 | 5.6 |
表6:数据集统计
B. 2 维基百科单位
我们指代处理过的语料库为Prop-WIKI。Prop-WIKI的统计数据如表7所示。值得注意的是,这里呈现的值对应于处理后的维基百科语料库的平均段落长度,而表5特别报告了推理期间输入到文本生成器的平均序列长度。
表7:英文维基百科中的文本单元统计。
| 单位数 | 平均字数 | |
|---|---|---|
| 段落 | 41,393,52841,393,52841,393,528 | 58.5 |
| 句子 | 114,219,127114,219,127114,219,127 | 21.0 |
| 命题 | 261,125,423261,125,423261,125,423 | 23.2 |
参考论文:https://arxiv.org/pdf/2505.16133

这里是“一人公司”的成长家园。我们提供从产品曝光、技术变现到法律财税的全栈内容,并连接云服务、办公空间等稀缺资源,助你专注创造,无忧运营。
更多推荐



 22
22 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)