【独立开发者】如何在代码层面提升后端接口性能?4个关键开发技巧
本文总结了业务开发中提升接口性能的四个关键编码技巧:1)精简日志输出,避免不必要的I/O开销;2)利用异步/多线程处理非核心任务;3)采用批量操作替代循环单条处理数据库;4)合理使用缓存减少重复查询。这些方法不依赖硬件升级,通过优化编码实践可显著提升系统性能。作者强调在实现功能时需保持性能敏感度,建议结合监控和压测持续优化,使系统更高效健壮。这些技巧特别适合处理高并发、大数据量场景下的性能瓶颈问题
在业务开发中,我们往往会遇到复杂的业务场景。面对这些场景,一个朴素、能快速实现功能的代码往往是第一步。然而,这份“初稿”在性能上可能并不理想,尤其是在高并发、大数据量场景下,很容易成为系统瓶颈。
诚然,后端接口的性能受到多方面影响:
- 服务器的硬件配置: 加钱升级CPU、内存、磁盘或网络带宽,往往是最直接(但也最昂贵)的提升方式。
- 中间件的配置: 不同的参数设置对性能有一定影响。
- 语言的选择: 编译型语言(例如C++,GO,Rust)性能优于解释型语言(如Python,Javascript)。
- 框架的选择: 不同框架在性能、易用性、生态上各有侧重,选择需权衡。仁者见仁,智者见智。
但是,以上因素更多地属于运维范畴或架构选型阶段的前期决策,并不能充分体现开发者在具体编码过程中的优化能力。
当技术栈确定、硬件和中间件配置到位后,“在代码层面提升性能”考验的才是开发者的真实编程水平。
聚焦于编码本身,我总结了以下4个最直接、也最能体现开发者功力的性能优化技巧:
1. 避免不必要的日志打印
日志是排查问题的利器,但过度或不当的日志打印会成为性能杀手,尤其是在高并发场景下。日志操作(尤其是同步日志)涉及磁盘I/O或网络传输,其开销远大于内存计算。DEBUG/TRACE级别的日志在生产环境大量输出、在循环体内打印大对象、重复打印相同信息等都是常见问题。
优化方法:
-
严格区分日志级别: 生产环境默认使用INFO或WARN级别。谨慎使用DEBUG/TRACE,并确保它们不会在正常业务流中被触发。
-
日志内容精简化: 只记录关键、必要的信息。避免在日志中打印庞大的对象(如整个请求体、大列表),可以打印其摘要(如ID、关键字段、大小)或使用toString()时重写方法避免输出无关字段。
-
避免高频循环内的详细日志: 在循环次数很多的代码块中,避免打印每条记录的详情。可以改为在循环外总结性打印,或仅在出错/满足特定条件时记录。
-
评估异步日志: 对于性能极其敏感的场景,可以考虑使用异步日志框架(如Log4j2的AsyncLogger),将日志写入操作放入独立线程池,减少对主业务线程的阻塞。但需注意异步日志可能丢失的风险。
通过这些办法,可以显著减少I/O等待时间,降低CPU消耗,提高接口吞吐量和响应速度。
性能对比: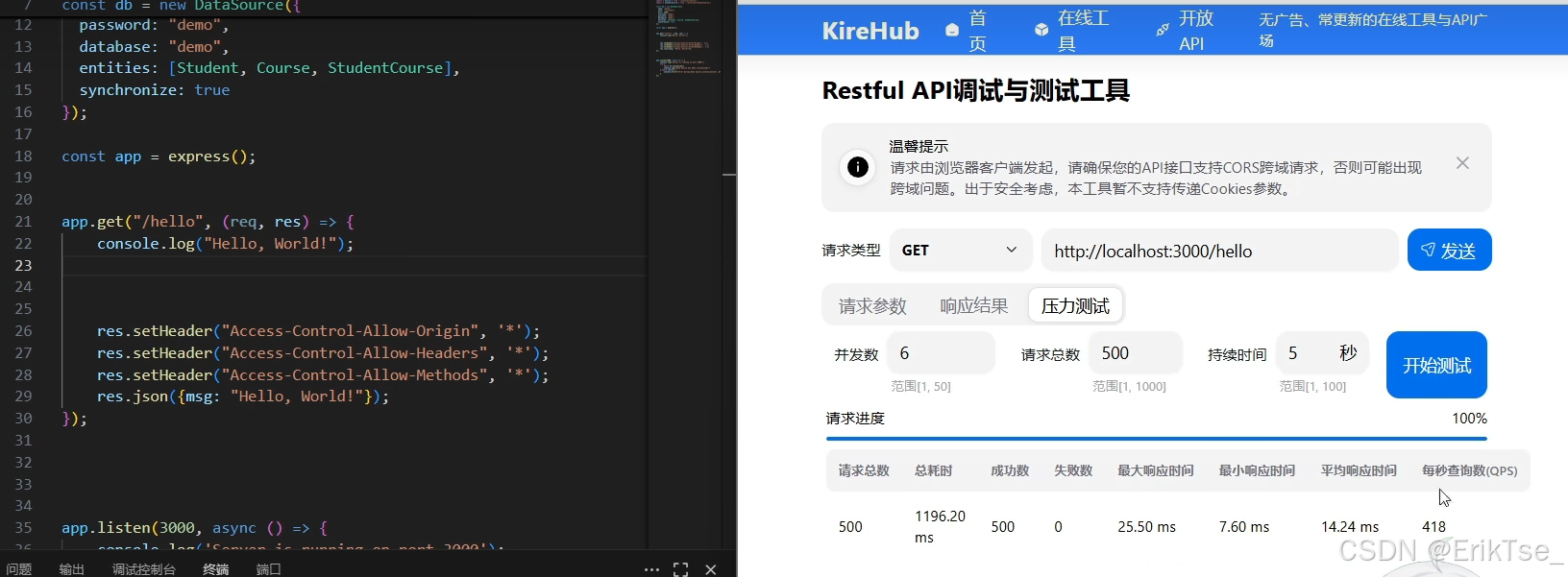
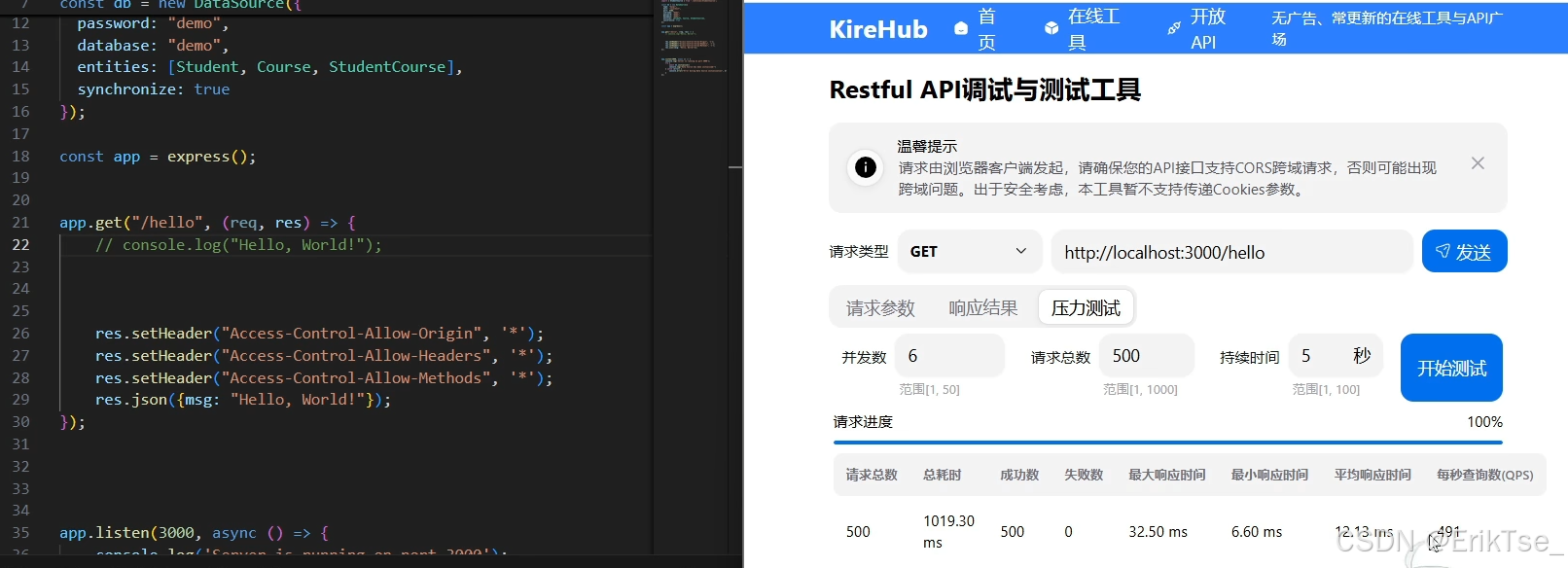
注释掉一句打印,就可以让性能提升20%

2. 合理运用异步 / 多线程模型
问题: 很多业务逻辑并非完全顺序执行。存在一些耗时且不依赖主流程结果的操作(如发送通知、记录辅助日志、清理临时数据、调用非关键的外部服务)。如果这些操作在主线程中同步执行,会阻塞主线程,导致接口响应时间变长。
优化:
识别可异步任务: 仔细分析业务流程,找出那些非核心路径、高延迟、对实时性要求不高的操作。
选择合适的异步机制:
线程池(ExecutorService): 最基础也是最灵活的方式。将任务提交到线程池异步执行。需合理配置线程池参数(核心线程数、最大线程数、队列类型与大小、拒绝策略)。
异步注解(如Spring @Async): 使用框架提供的便捷注解简化异步调用。需理解其背后的线程池配置。
消息队列(MQ): 对于需要解耦、保证可靠性的场景,将任务放入消息队列,由消费者异步处理。适用于更复杂的后台任务。
响应式编程(如Reactor, RxJava): 在非阻塞IO和高并发场景下,提供更优雅的异步和背压处理模型。
收益: 将阻塞操作移出主线程,显著缩短主接口的响应时间(RT),提高系统的吞吐量和资源利用率。用户体验更流畅。
关键注意点:
线程安全: 异步代码必须注意共享资源的线程安全(使用锁、并发集合等)。
错误处理: 确保异步任务中的异常能被捕获和处理,避免静默失败。
资源管理: 避免创建过多线程导致资源耗尽。合理使用和配置线程池。
事务边界: 异步操作通常不在主事务内,需要单独处理数据一致性问题(如最终一致性)。
3. 分批插入与查询
问题: 当需要处理大量数据时(如导入数万条记录、查询满足条件的大批数据),使用for循环单条插入或单次查询获取全部数据,会产生巨大的性能开销:
数据库插入: 每条INSERT都涉及网络传输、SQL解析、事务管理(如果自动提交)、磁盘I/O。循环N次意味着N倍的开销。
数据库查询: 一次性查询海量数据(如SELECT * FROM huge_table)可能导致:
数据库服务器CPU、内存、I/O压力剧增。
网络传输时间长,甚至超时。
应用服务器消耗大量内存(OOM风险)来装载结果集。
前端渲染卡顿。
优化:
批量插入(Batch Insert):
使用JDBC的 addBatch() 和 executeBatch() 方法。
使用MyBatis的 `` 标签或 @InsertProvider 动态SQL拼接批量插入语句 (INSERT INTO table (col1, col2) VALUES (?, ?), (?, ?), …)。
使用JPA的 saveAll(Iterable entities) 方法(注意其可能仍是循环插入,需结合Hibernate的batch_size配置)。
关键: 控制单批次的大小(如500-1000条),过大可能导致数据库事务日志满或网络包过大。在循环累积数据,达到批次大小时提交一次。
分批/分页查询:
使用SQL的 LIMIT offset, size (MySQL) 或 OFFSET x FETCH NEXT y ROWS ONLY (SQL标准) 进行分页查询。注意:深度分页(offset很大)性能极差,需要优化(如使用游标、连续ID过滤)。
使用基于游标(Cursor)的查询(如JDBC ResultSet.TYPE_FORWARD_ONLY, ResultSet.CONCUR_READ_ONLY 并设置 fetchSize),数据库流式传输结果,避免一次性加载到应用内存。
使用MyBatis的游标支持(如ResultHandler)。
使用Spring Data JPA的分页接口(Page, Slice)。
收益:
插入: 大幅减少数据库事务开销、网络往返次数(RTT)、SQL解析开销,提升写入速度数倍甚至数十倍。
查询: 减轻数据库负载,避免应用OOM,降低网络传输延迟,提高接口响应速度,提升用户体验。流式查询特别适合处理海量数据导出。
4. 一次查询,多次使用
问题: 在复杂的业务逻辑中,相同的数据或计算结果经常会被多个地方或多次请求重复访问。如果每次都去查询数据库或进行复杂的计算,会造成极大的资源浪费(数据库压力、CPU消耗)和响应延迟。尤其是在热点数据访问、复杂计算逻辑的场景下。
优化: 核心思想是缓存(Cache)。
识别可缓存项: 频繁读取、变化频率不高、计算成本高的数据是首要缓存目标(如配置信息、用户基础信息、热点商品数据、复杂的聚合结果)。
选择合适的缓存策略和存储:
本地缓存(如Guava Cache, Caffeine, Ehcache): 速度快(内存访问),适用于单实例应用或缓存不要求强一致性的数据。注意内存管理和过期策略。
分布式缓存(如Redis, Memcached): 适用于集群环境,缓存数据在多个应用实例间共享。提供丰富的数据结构和持久化选项。性能通常也很好(内存+网络)。
HTTP缓存(如浏览器缓存、CDN缓存、Cache-Control/ETag): 适用于静态资源或变化不频繁的API响应,直接从客户端或边缘节点返回,极大减轻应用服务器和网络压力。
合理设置缓存过期/失效策略:
TTL(Time-To-Live): 设置固定的过期时间。简单,但可能有不一致窗口。
主动失效: 在数据更新时,同步或异步地删除/更新相关缓存项。一致性更好,但需要维护失效逻辑。
结合使用: 通常设置一个相对较短的TTL作为兜底,同时尽可能实现主动失效。
注意缓存穿透、雪崩、击穿:
穿透: 大量请求查询不存在的数据(缓存未命中,打到DB)。解决: 缓存空值(短TTL)、布隆过滤器(Bloom Filter)预判。
雪崩: 大量缓存项同时过期,请求瞬间涌向DB。解决: 设置随机的过期时间(TTL + 随机值)。
击穿: 热点Key过期瞬间,大量并发请求直接打到DB。解决: 使用互斥锁(如Redis SETNX)只让一个请求去重建缓存,其他等待。
收益: 极大减少对数据库或复杂计算的访问次数,显著降低数据库负载,减少网络IO和CPU消耗,成倍提升接口响应速度(尤其对于读多写少的热点数据)。是提升系统性能和扩展性的核心手段。
总结
性能优化是一个持续的过程,需要结合监控、压测(如JMeter)来定位瓶颈。这四个技巧——精简日志、善用异步、批量操作、巧用缓存——是开发者日常编码中最直接、最常用、也最能立竿见影提升接口性能的方法。它们不依赖于昂贵的硬件扩容或更换技术栈,而是通过更聪明、更高效的编码实践来挖掘现有资源的潜力。
记住:在追求功能实现的同时,时刻保持对性能的敏感度,尤其是在处理循环、I/O操作、数据库交互和重复计算时。将性能视为代码质量的一部分,你的系统将会更加健壮、高效和可扩展。

这里是“一人公司”的成长家园。我们提供从产品曝光、技术变现到法律财税的全栈内容,并连接云服务、办公空间等稀缺资源,助你专注创造,无忧运营。
更多推荐



 27
27 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)