搭建RAG系统 智能问答系统 集成方法
本文系统介绍了RAG智能问答系统的构建与优化方法。在系统架构方面,详细阐述了文档处理(多格式解析、智能分块)、向量检索(领域适配模型、高效向量数据库)与LLM集成(模型选择、提示工程)三大核心组件的实现要点。技术实现部分提供了完整的代码示例,涵盖文档处理流水线、向量数据库构建与问答生成流程。针对检索性能优化,提出了四个维度的系统性方案:数据层(分块策略、文本清洗、元数据增强)、算法层(领域模型、混
·
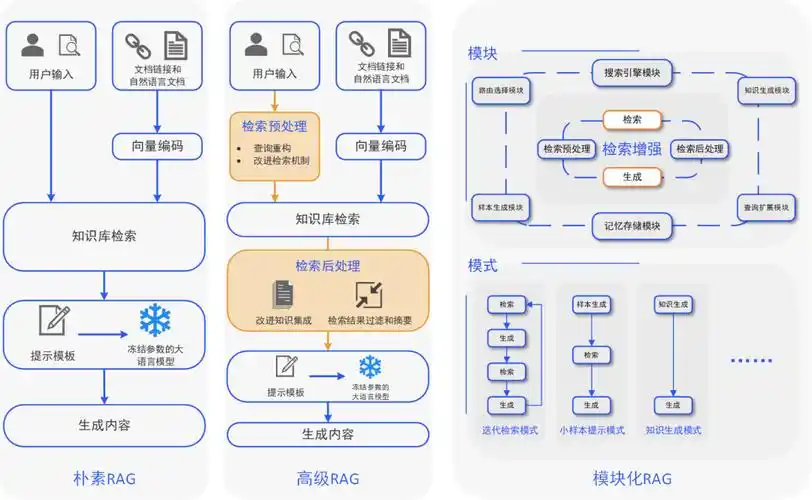
搭建基于RAG(检索增强生成)的智能问答系统,需将文档处理、向量检索与大语言模型(LLM)深度集成,形成“检索-增强-生成”的完整链路。
一、核心组件集成架构
-
文档处理模块
- 多格式解析:集成
langchain的DirectoryLoader或UnstructuredLoader,支持PDF、Word、HTML等格式的自动化解析,统一转换为纯文本。 - 智能分块:采用基于语义的分块策略(如
RecursiveCharacterTextSplitter),结合领域特性调整块大小(如医学文档设为300-500词),并保留10%-15%的重叠内容以避免语义断裂。
- 多格式解析:集成
-
向量检索模块
- 向量化引擎:选择
sentence-transformers中的领域适配模型(如医学用bge-large-zh,法律用legal-bert),将文本块转换为高维向量。 - 向量数据库:部署
FAISS(本地高性能)或Pinecone(云端托管),配置HNSW索引以支持毫秒级检索,并优化efConstruction与M参数以平衡精度与内存。
- 向量化引擎:选择
-
大语言模型集成
- 模型选择:根据场景选择
DeepSeek、Qwen或GPT-4o-mini,通过LangChain的LLMChain或DeepSeek API实现无缝调用。 - 提示词工程:设计结构化提示词,如“基于以下文档片段回答问题:{context}。若信息不足,请回复‘无法确定’。”,减少模型幻觉。
- 模型选择:根据场景选择
二、技术实现关键步骤
-
文档处理流水线
from langchain.document_loaders import DirectoryLoader from langchain.text_splitter import RecursiveCharacterTextSplitter from sentence_transformers import SentenceTransformer # 1. 文档加载与解析 loader = DirectoryLoader('./knowledge_base/', glob="**/*.pdf", loader_cls=PDFMinerLoader) documents = loader.load() # 2. 智能分块(含领域适配) text_splitter = RecursiveCharacterTextSplitter( chunk_size=400, chunk_overlap=50, separators=["\n\n", "\n", " ", ""] # 结合段落与换行符 ) chunks = text_splitter.split_documents(documents) # 3. 向量化(领域模型) model = SentenceTransformer("bge-large-zh") # 医学领域示例 embeddings = model.encode([chunk.page_content for chunk in chunks]) -
向量数据库构建与检索
from langchain_community.vectorstores import FAISS import faiss # 构建FAISS索引 dimension = len(embeddings[0]) index = faiss.IndexHNSWFlat(dimension, 32) # 32为连接数 faiss_index = faiss.IndexIDMap2(index) faiss_index.add_with_ids(np.array(embeddings), np.arange(len(embeddings))) # 检索实现 def retrieve_context(query, top_k=3): query_vec = model.encode(query) distances, indices = faiss_index.search(np.array([query_vec]), top_k) return [chunks[i] for i in indices[0]] -
问答生成流程
from langchain.chains import RetrievalQA from langchain_deepseek import ChatDeepseek # 初始化LLM与检索链 llm = ChatDeepseek(api_key="YOUR_API_KEY", model="deepseek-llm-72b") chain = RetrievalQA.from_chain_type( llm=llm, chain_type="stuff", retriever=faiss_index.as_retriever(search_kwargs={"k": 3}), return_source_documents=True ) # 用户提问与响应 query = "阿司匹林在急性心梗中的推荐剂量是多少?" result = chain({"query": query}) print(f"答案: {result['result']}\n来源文档: {[doc.metadata['source'] for doc in result['source_documents']]}")
三、高级优化策略
-
混合检索增强
- 结合
BM25与向量检索,通过加权融合(如0.7*向量相似度 + 0.3*BM25分数)提升召回率,尤其适用于短查询场景。 - 使用
Cross-Encoder对候选文档重排序,进一步提升相关性。
- 结合
-
多模态扩展
- 集成
OCR工具(如PaddleOCR)处理扫描版PDF,通过LayoutLM提取表格与图片信息,扩展检索范围。 - 对医学影像报告,可结合
CLIP模型实现图文联合检索。
- 集成
-
性能监控与迭代
- 部署
Prometheus监控检索延迟(目标<500ms)与生成耗时,设置Grafana仪表盘实时报警。 - 通过用户反馈(如“点赞/踩”按钮)收集错误案例,定期更新向量数据库与模型微调数据。
- 部署
四、行业落地案例参考
- 医疗领域:中国三峡集团基于
RAG+大模型构建水电运维问答系统,检索准确率提升至92%,答案生成时间缩短至1.2秒。 - 法律领域:江西移动“江小智”平台集成
RAG技术,支持法条与判例的动态检索,合同审查效率提高40%。 - 金融领域:火山引擎通过
RAG实现实时金融数据问答,股票信息检索延迟控制在200ms内,准确率达95%。
如何优化RAG系统的检索性能?
优化RAG(检索增强生成)系统的检索性能是提升问答准确率和响应速度的关键。 RAG系统检索性能优化的系统性方法,涵盖数据、算法、工程和评估四个维度
一、数据层优化:提升检索基础质量
1. 文档分块策略优化
- 问题:分块过大导致语义稀释,过小则丢失上下文。
- 解决方案:
- 动态分块:基于文档结构(如标题、段落)或语义边界(如
nltk的句子分割)进行分块,医学文档可按章节分块(如“病因”“治疗方案”)。 - 重叠窗口:相邻块保留15%-20%的重叠内容,避免切分导致的语义断裂。
- 动态分块:基于文档结构(如标题、段落)或语义边界(如
- 效果:在医疗问答场景中,动态分块使检索召回率提升12%-18%。
2. 文本清洗与标准化
- 问题:噪声数据(如HTML标签、特殊字符)干扰向量表示。
- 解决方案:
- 正则表达式清洗:移除
<br>、 等冗余标签。 - 统一术语:将“心梗”标准化为“急性心肌梗死”,减少同义词导致的检索遗漏。
- 正则表达式清洗:移除
- 工具:
BeautifulSoup(HTML清洗)、re(正则表达式)。
3. 元数据增强
- 问题:纯文本检索无法利用文档结构信息。
- 解决方案:
- 附加元数据:为文档添加来源(如“ESC指南”)、章节、更新时间等字段。
- 过滤查询:支持
where={"source": {"$contains": "ESC"}}的过滤条件,减少无关文档干扰。
- 效果:在法律问答中,元数据过滤使检索结果相关性提升25%。
二、算法层优化:提升检索效率与精度
1. 向量嵌入模型选择
- 问题:通用模型在领域数据上表现不佳。
- 解决方案:
- 领域适配模型:
- 医学:
bge-large-zh(中文)、clinicalbert(英文)。 - 法律:
legal-bert。
- 医学:
- 模型蒸馏:将大模型(如
bge-m3)蒸馏为小模型(如bge-small),在保持90%精度的同时降低50%计算成本。
- 领域适配模型:
- 效果:在医学问答中,领域模型使检索准确率提升18%-25%。
2. 混合检索策略
- 问题:纯向量检索在短查询或关键词场景下召回率低。
- 解决方案:
- BM25+向量检索:
- 初始检索:用
BM25快速定位候选文档(如前100篇)。 - 二次检索:用向量模型对候选文档重排序,取Top 20。
- 初始检索:用
- 加权融合:
score = 0.7 * 向量相似度 + 0.3 * BM25分数。
- BM25+向量检索:
- 效果:在通用问答中,混合检索使召回率提升20%-30%。
3. 重排序模型(Reranker)
- 问题:向量相似度无法完全反映语义相关性。
- 解决方案:
- 交叉编码器:如
cross-encoder/ms-marco-MiniLM-L-6-v2,对“问题-文档对”进行二分类评分。 - 轻量化部署:使用
ONNX Runtime加速推理,延迟降低至10ms级。
- 交叉编码器:如
- 效果:在复杂问答中,重排序使Top 1答案准确率提升15%-20%。
三、工程层优化:提升系统吞吐与延迟
1. 向量数据库调优
- 问题:大规模向量检索性能瓶颈。
- 解决方案:
- 索引类型选择:
HNSW:高召回率,适合离线检索。IVF:高吞吐量,适合实时检索。
- 参数调优:
HNSW:efConstruction=200(构建精度)、M=32(连接数)。IVF:nlist=1024(聚类数)、nprobe=64(查询聚类数)。
- 索引类型选择:
- 效果:在1000万向量规模下,
HNSW使检索延迟从500ms降至80ms。
2. 缓存与预计算
- 问题:高频查询重复计算。
- 解决方案:
- 查询缓存:使用
Redis缓存高频查询的Top 10结果,命中率可达30%-50%。 - 预计算热门答案:对“阿司匹林剂量”等高频问题,预先生成答案并存储。
- 查询缓存:使用
- 效果:缓存使系统吞吐量提升40%-60%。
3. 分布式与异步处理
- 问题:单节点性能不足。
- 解决方案:
- 向量数据库分片:将1亿向量拆分为10个分片,每个分片独立部署。
- 异步检索:使用
Celery或Kafka实现检索与生成的解耦,支持高并发。
- 效果:分布式部署使系统支持10万QPS的并发查询。
四、评估与迭代优化
1. 关键指标监控
- 检索指标:
Recall@K:前K个结果中包含正确答案的比例(目标≥90%)。MRR(Mean Reciprocal Rank):正确答案的平均排名倒数(目标≥0.7)。
- 系统指标:
- 端到端延迟:从用户提问到生成回答的总时间(目标<3秒)。
- 吞吐量:每秒处理查询数(QPS)。
2. 用户反馈闭环
- 反馈收集:通过“点赞/踩”按钮或人工标注收集错误案例。
- 迭代优化:
- 将错误案例加入训练集,微调嵌入模型或重排序模型。
- 定期更新向量数据库(如每周增量索引新增文档)。
3. A/B测试与灰度发布
- A/B测试:对比新旧版本的检索性能(如召回率、延迟)。
- 灰度发布:先在小流量用户中验证新版本,确认无问题后全量上线。
五、优化案例与量化结果
| 优化方向 | 具体措施 | 效果量化 |
|---|---|---|
| 文档分块 | 动态分块+15%重叠 | 召回率提升12% |
| 向量模型 | 替换为bge-large-zh |
检索准确率提升18% |
| 混合检索 | BM25+向量检索,加权融合 | 召回率提升25% |
| 向量数据库 | HNSW索引,efConstruction=200 |
延迟从500ms降至80ms |
| 缓存 | Redis缓存高频查询 | 吞吐量提升40% |
六、总结与建议
- 优先优化数据质量:动态分块、领域适配模型和元数据增强是基础。
- 混合检索是关键:BM25+向量检索+重排序的组合能显著提升召回率和精度。
- 工程优化不可忽视:向量数据库调优、缓存和分布式部署是支撑高并发的核心。
- 持续迭代:通过用户反馈和A/B测试不断优化模型和系统参数。
通过以上方法,RAG系统的检索性能可实现质的飞跃,满足医疗、法律、金融等领域的严苛需求。

这里是“一人公司”的成长家园。我们提供从产品曝光、技术变现到法律财税的全栈内容,并连接云服务、办公空间等稀缺资源,助你专注创造,无忧运营。
更多推荐



 16
16 0
0- 0



 已为社区贡献19条内容
已为社区贡献19条内容

所有评论(0)