Prompt Engineering vs Vibe Coding vs Context Engineering
**摘要:**提示工程、氛围编程和上下文工程是三种AI辅助开发的关键技术。提示工程通过优化单次指令(如角色设定、输出格式)提升模型输出质量,适用于代码生成等简单任务。氛围编程强调开发者与AI的迭代协作(如通过AI-IDE生成并测试代码),降低开发门槛但可能增加技术债务。上下文工程通过动态整合多源信息(如RAG、工具调用)处理复杂任务,解决知识截止和幻觉问题。三者呈现从静态指令到动态协作的演进趋势,
1. 提示工程(Prompt Engineering)
定义:通过设计优化输入提示(Prompt)引导大语言模型(LLM)生成高质量输出的技术,核心是“如何问对问题”。
核心特点:
- 任务导向:聚焦单次交互的指令设计,如明确角色、输出格式、示例提供(Few-Shot Learning)。
- 静态性:提示词多为预定义模板,依赖人工调整优化,复用性有限。
- 应用场景:代码生成、文本创作、翻译等简单任务,例如要求模型“用Python实现二分查找并输出代码块”。
局限性: - 模型表现易受措辞影响,稳定性差;
- 无法解决知识截止、私有数据访问等复杂问题。
2. 氛围编程(Vibe Coding)
定义:由Andrej Karpathy提出的开发范式,开发者通过自然语言描述需求,与AI协作迭代生成代码,强调“描述优先于编码”。
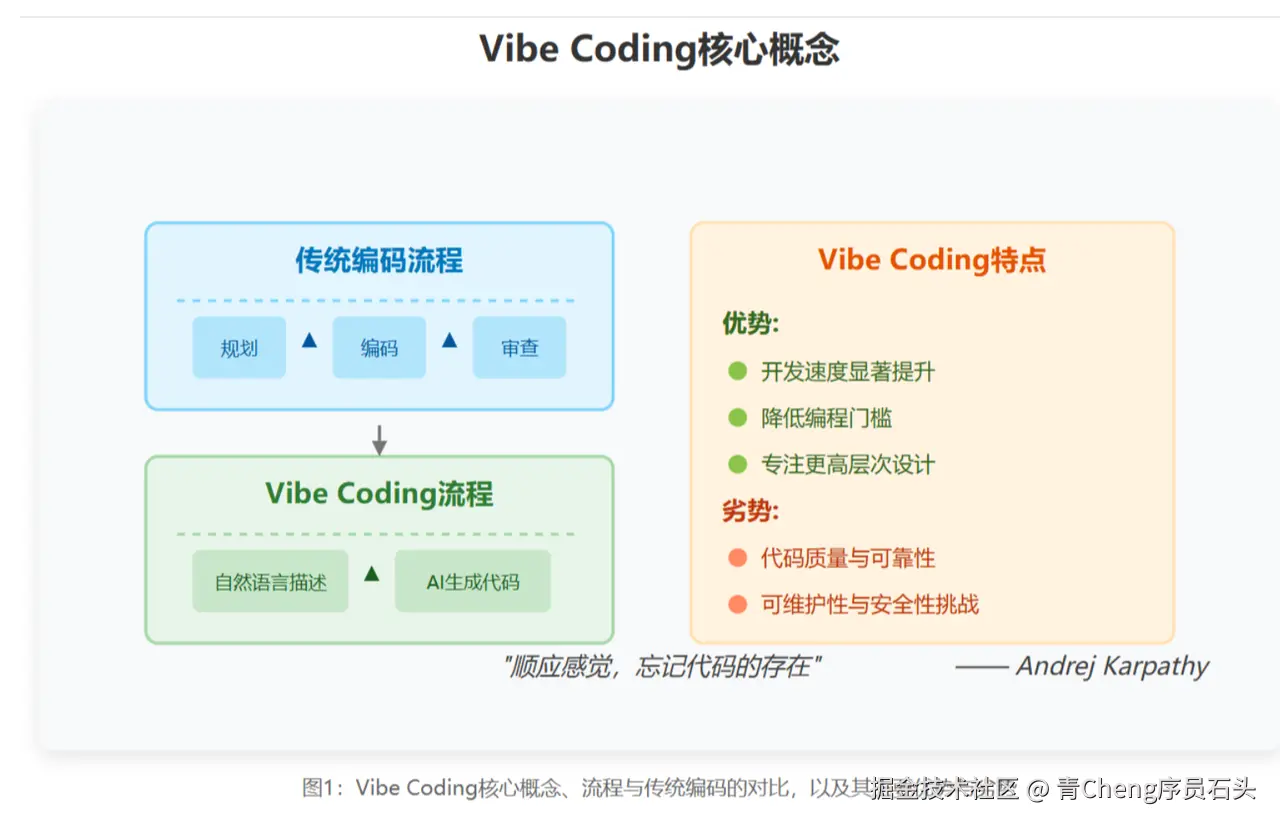
核心特点:
- 动态协作:开发者充当“需求架构师”,AI负责实现细节,形成“描述→生成→测试→迭代”的闭环流程。
- 工具生态:依赖Cursor、Windsurf等AI-IDE,整合语音输入、实时预览、调试工具等支持。
- 提示策略:需提供明确上下文(如技术栈、现有代码片段)、分解任务、迭代优化提示。
典型流程:
- 定义目标 → 2. AI生成代码 → 3. 人工审查 → 4. 测试反馈 → 5. 迭代优化。
优势与挑战:
- 降低入门门槛:开发者更关注业务逻辑而非语法细节;
- 维护风险:AI生成代码需严格测试,否则可能增加技术债务。
Vibe coding 最大的问题是:它让开发变成了“碰运气”,而不是“可控的工程” 。Vibe Coding 的优势在于能够加速开发的初始阶段,并赋能那些编程技能有限的个人
3. 上下文工程(Context Engineering)
定义:系统性管理输入信息的动态工程方法,通过结构化上下文(如历史对话、外部知识、工具调用)提升模型任务能力。
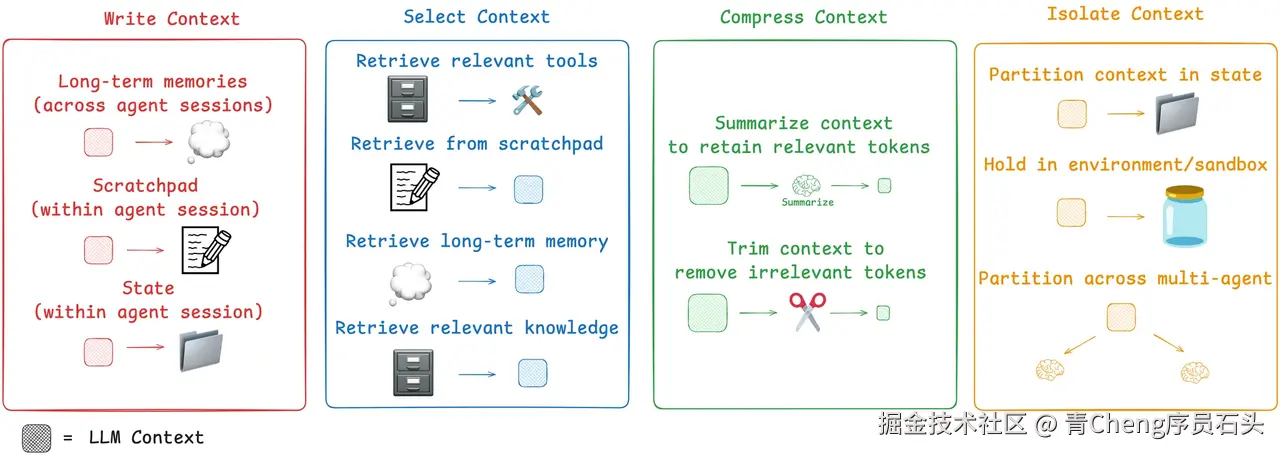
核心特点:
- 动态信息整合:超越提示词,注入实时数据(RAG)、长期记忆、工具API描述等,构建“认知环境”。
- 策略化设计:采用写入(Write)、选择(Select)、压缩(Compress)、隔离(Isolate)四策略管理上下文窗口。
- 系统级优化:类比“操作系统”,LLM是CPU,上下文窗口是RAM,工程师需动态调度关键信息。
应用场景: - 金融分析:实时注入财报数据+市场新闻,生成多源融合报告;
- 多Agent系统:自动驾驶中为感知/规划模块分配独立上下文,避免信息干扰。
优势: - 解决幻觉、知识截止问题,提升复杂任务(如医疗诊断、法律咨询)的可靠性。
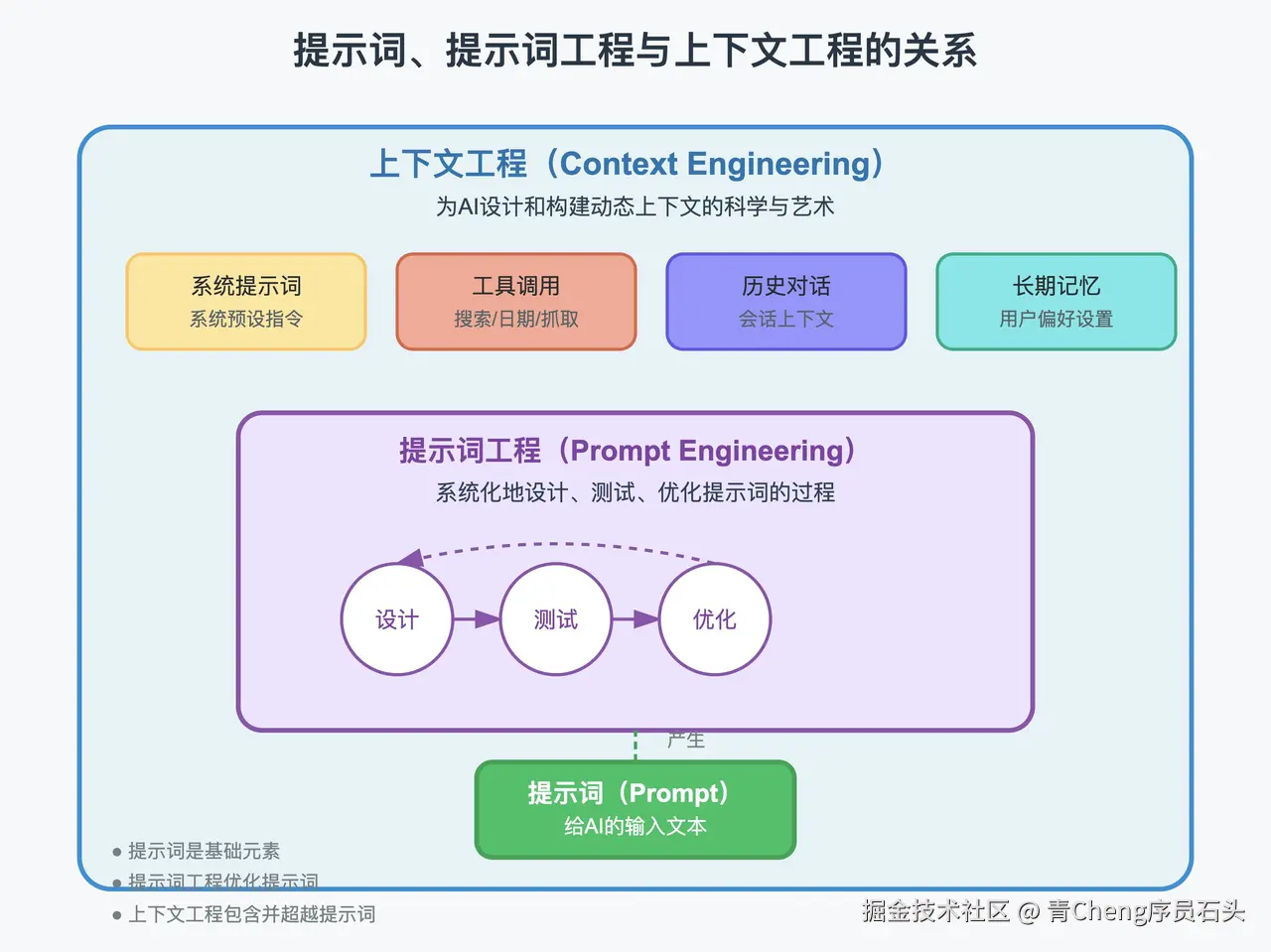
三者的演进关系与对比
| 维度 | 提示工程 | Vibe Coding | 上下文工程 |
|---|---|---|---|
| 核心目标 | 优化单次指令 | 自然语言驱动的迭代开发 | 动态构建认知环境 |
| 信息管理 | 静态提示词 | 会话历史+项目上下文 | 多源动态注入(RAG/工具/记忆) |
| 适用场景 | 简单任务(代码片段) | 原型开发、中小型项目 | 复杂系统(医疗/金融) |
| 技术成熟度 | 成熟(2023年起) | 新兴(2025年主流) | 前沿(2025年爆发) |
| 代表工具 | ChatGPT提示模板 | Cursor、Windsurf | LangGraph+LangSmith |
演进逻辑:
- 提示工程 → Vibe Coding:从单次指令到多轮协作,开发者角色从“编码者”转向“需求架构师”;
- Vibe Coding → 上下文工程:从对话式开发到系统化信息管理,解决长任务中的幻觉和上下文过载问题。
总结:开发者如何选择?
- 初级任务/快速原型:用提示工程设计清晰指令(如指定代码格式);
- 中型项目/敏捷迭代:采用Vibe Coding工具链(如Cursor),注重提示分解与测试;
- 企业级复杂系统:引入上下文工程,结合RAG、工具调用构建动态知识流。
💡 未来趋势
- 上下文工程正成为AI辅助开发的核心技能,其“动态信息编排”能力将重塑人机协作边界。
- 开发者需掌握工具链(如LangGraph管理状态)、理解信息压缩策略,以应对更复杂的系统需求
如何系统的去学习大模型LLM ?
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
事实上,抢你饭碗的不是AI,而是会利用AI的人。
继科大讯飞、阿里、华为等巨头公司发布AI产品后,很多中小企业也陆续进场!超高年薪,挖掘AI大模型人才! 如今大厂老板们,也更倾向于会AI的人,普通程序员,还有应对的机会吗?
与其焦虑……
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高。
针对所有自学遇到困难的同学们,我帮大家系统梳理大模型学习脉络,将这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等
一、LLM大模型经典书籍
AI大模型已经成为了当今科技领域的一大热点,那以下这些大模型书籍就是非常不错的学习资源。

二、640套LLM大模型报告合集
这套包含640份报告的合集,涵盖了大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(几乎涵盖所有行业)

三、LLM大模型系列视频教程

四、LLM大模型开源教程(LLaLA/Meta/chatglm/chatgpt)

LLM大模型学习路线 ↓
阶段1:AI大模型时代的基础理解
-
目标:了解AI大模型的基本概念、发展历程和核心原理。
-
内容:
- L1.1 人工智能简述与大模型起源
- L1.2 大模型与通用人工智能
- L1.3 GPT模型的发展历程
- L1.4 模型工程
- L1.4.1 知识大模型
- L1.4.2 生产大模型
- L1.4.3 模型工程方法论
- L1.4.4 模型工程实践
- L1.5 GPT应用案例
阶段2:AI大模型API应用开发工程
-
目标:掌握AI大模型API的使用和开发,以及相关的编程技能。
-
内容:
- L2.1 API接口
- L2.1.1 OpenAI API接口
- L2.1.2 Python接口接入
- L2.1.3 BOT工具类框架
- L2.1.4 代码示例
- L2.2 Prompt框架
- L2.3 流水线工程
- L2.4 总结与展望
阶段3:AI大模型应用架构实践
-
目标:深入理解AI大模型的应用架构,并能够进行私有化部署。
-
内容:
- L3.1 Agent模型框架
- L3.2 MetaGPT
- L3.3 ChatGLM
- L3.4 LLAMA
- L3.5 其他大模型介绍
阶段4:AI大模型私有化部署
-
目标:掌握多种AI大模型的私有化部署,包括多模态和特定领域模型。
-
内容:
- L4.1 模型私有化部署概述
- L4.2 模型私有化部署的关键技术
- L4.3 模型私有化部署的实施步骤
- L4.4 模型私有化部署的应用场景
这份 LLM大模型资料 包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 下方小卡片领取🆓↓↓↓

这里是“一人公司”的成长家园。我们提供从产品曝光、技术变现到法律财税的全栈内容,并连接云服务、办公空间等稀缺资源,助你专注创造,无忧运营。
更多推荐



 25
25 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)