点亮数据星辰,智启江城未来:武汉市数据知识产权交易中心平台技术白皮书
摘要 本白皮书提出以"领码SPARK融合平台"为技术底座,构建武汉市数据知识产权交易中心的"八可"一体化解决方案。方案创新性集成DCMM国家标准与AI技术,实现数据从可集成、可梳理到可交易、可监管的全生命周期管理。平台通过低代码集成多源数据、智能化评估定价、区块链存证验证等功能,破解数据确权难、定价难等核心痛点,打造安全可信的数据交易枢纽,助力武汉成为全国数
摘要
本白皮书旨在为“武汉市数据知识产权交易中心”擘画一幅前瞻性的技术蓝图。报告以先进的“领码 SPARK 融合平台”为技术底座,创新性地深度集成国家数据管理能力成熟度模型(DCMM),并全面融入人工智能(AI)前沿技术。我们提出以用户为中心的“八可”一体化解决方案——即可集成、可梳理、可评估、可治理、可验证、可定价、可交易、可监管。通过构建一个安全、可信、高效、智能的数据价值枢纽,本方案旨在破解当前数据知识产权流通困境,释放武汉市数字经济的磅礴潜力,为将武汉打造成为全国数据要素市场化配置改革的先行区提供坚实的技术支撑。
关键词
数据知识产权, 领码SPARK平台, DCMM, 人工智能, 数据交易, 数据治理
📖 第一章:引言:江城数智,新篇待启
1.1 🚀 时代背景:数据浪潮与江城机遇
我们正处在一个由数据驱动的伟大时代。数据,作为继土地、劳动力、资本、技术之后的第五大生产要素,已成为全球经济增长的核心引擎和国家战略竞争的新高地。武汉,作为国家中心城市和长江经济带的核心节点,拥有雄厚的科教资源、坚实的产业基础和庞大的数据存量,正迎来数字经济发展的历史性机遇。然而,如何将海量、异构、分散的数据资源转化为可信、可流通、可增值的“数据知识产权”,是武汉乃至全国亟待破解的关键命题。
1.2 🎯 挑战与破局:数据知识产权流通之困
当前,数据知识产权的交易与流通面临着一系列严峻挑战:
- 确权难:数据来源复杂,权属界定模糊,导致“谁的数据”难以说清。
- 评估难:数据价值随场景、时效、质量动态变化,缺乏公允、统一的评估标准。
- 定价难:传统成本法定价法无法反映数据真实价值,市场化定价机制缺失 [[1]]。
- 入场难:数据提供方的数据治理能力参差不齐,数据质量、合规性难以保障。
- 交易难:交易过程不透明,缺乏信任,数据泄露和滥用风险高。
- 监管难:数据使用路径难以追踪,事后追责和权益保护困难重重 [[2]]。
为破此局,武汉市数据知识产权交易中心平台必须超越传统交易撮合平台的定位,构建一个集数据治理、价值评估、智能交易与风险监管于一体的新型基础设施。
1.3 🏛️ 平台愿景:构建可信、高效、智能的数据价值枢纽
本平台旨在成为链接数据资源方、需求方、服务方和监管方的“城市级数据价值枢纽”。我们的愿景是:
- 对数据持有者:提供一站式的数据资产化服务,让“沉睡”的数据“活”起来,安全、合规地实现价值变现。
- 对数据使用者:提供丰富、优质、可信的数据产品,降低数据获取门槛,加速业务创新与智能化转型。
- 对城市发展:促进数据要素在全社会范围内的优化配置,赋能千行百业,为武汉市数字经济高质量发展注入核心动力。
1.4 🗺️ 白皮书结构概览
本白皮书将系统阐述平台的技术架构、核心理念与实现路径。
- 第二章 提出平台总体设计思想——“八可”一体化解决方案。
- 第三章 深度解析平台的技术基石——领码 SPARK 融合平台。
- 第四章 阐述如何集成 DCMM 模型,构建平台的数据治理与评估体系。
- 第五章 详述 AI 技术如何赋能数据验证、定价与监管全流程。
- 第六章 展示平台的核心功能模块与关键业务工作流设计。
- 第七章 展望平台的未来演进方向与生态价值。
🧩 第二章:总体设计:八可融通,一体智联
2.1 💡 设计理念:以用户为中心,以价值为导向
平台设计的核心出发点是解决数据交易中各方用户的核心痛点。我们摒弃以“技术”为中心的孤立功能堆砌,转向以“用户”和“价值”为中心的场景化解决方案设计。平台的一切功能,从数据接入到最终的价值实现,都围绕着提升交易效率、保障交易安全、发现数据价值三大目标展开。
2.2 🔗 核心目标:构建“八可”一体化解决方案
为实现上述愿景,我们提出独创的“八可”一体化解决方案,它构成了平台能力的全景图,确保数据知识产权从形成到价值实现的全生命周期管理。
- ① 可集成 (Integrable):平台具备强大的连接能力,通过低代码/无代码方式,快速接入政府、企业、科研机构等多源异构数据系统,打破数据孤岛。
- ② 可梳理 (Sortable):对接入的数据进行自动化元数据抽取、分类和编目,形成清晰、可视化的全景数据资产地图,让数据“家底”一目了然。
- ③ 可评估 (Assessable):深度融合 DCMM 国家标准,对入场数据的质量、安全、合规性进行多维度、标准化的自动化评估与评级。
- ④ 可治理 (Governable):提供一套完整的工具链,支持数据标准、数据质量、数据安全和生命周期策略的定义与执行,确保数据在平台内的有序流转。
- ⑤ 可验证 (Verifiable):利用 AI 和区块链技术,对数据来源的真实性、内容的合规性、授权的有效性进行交叉验证,构建不可篡改的信任链条。
- ⑥ 可定价 (Priceable):首创“评估+市场”双驱动的 AI 动态定价模型,结合 DCMM 评估结果与市场供需实时动态,科学发现并量化数据价值 [[3]]。
- ⑦ 可交易 (Tradable):支持数据使用权、数据产品、数据服务等多种交易模式,通过智能合约实现交易流程的自动化、透明化和高效化 [[4]][[5]]。
- ⑧ 可监管 (Supervisable):为监管部门提供“上帝视角”的穿透式监管仪表盘,通过 AI 实时监控交易行为,智能预警异常风险,保障市场健康有序发展。
2.3 🏗️ 总体架构:领码 SPARK 融合平台为基,AI与DCMM为翼
为支撑“八可”解决方案的落地,我们设计了如下分层解耦的总体技术架构:
架构解读:
- 基础设施层:采用云原生技术栈,以 Kubernetes (K8s) 为核心实现资源的弹性伸缩和多租户隔离 [[6]]。利用分布式存储和计算框架保障海量数据处理能力。集成区块链作为可信存证和智能合约的底层基础。
- 核心平台层:这是整个平台的技术心脏,完全基于领码 SPARK 融合平台构建。其元数据驱动内核是实现“可梳理”、“可治理”的基础;iPaaS 引擎是实现“可集成”的利器;aPaaS 引擎则能快速构建上层的各类交易与管理应用;AI 策略引擎则为“可验证”、“可定价”、“可监管”提供智能动力。
- 应用与服务层:基于领码 SPARK 平台的 aPaaS 能力,以低代码方式快速开发出的面向用户的核心功能模块,如数据产品上架、DCMM 评估、AI 定价等,每个模块都可注册为平台的一个可复用、可计量的“能力项” [[7]]。
- 呈现与交互层:为不同角色的用户(数据商、买家、开发者、监管者)提供定制化的、友好的交互界面。
⚙️ 第三章:技术基石:领码SPARK融合平台深度解析
平台的先进性与可行性,根植于其强大的技术底座——领码 SPARK 融合平台。
3.1 🏷️ 平台正名:超越 Apache Spark 的新范式
首先必须明确,领码 SPARK 融合平台中的“SPARK”是“Smart Platform for Adaptive Resource Knowledge”的缩写,意为“自适应资源知识的智能平台”,它与开源社区的 Apache Spark 大数据计算框架并无直接技术关联 [[8]]。领码 SPARK 是一种全新的、面向企业数字化转型的低代码/无代码 iPaaS + aPaaS 双引擎融合平台,其核心是“元数据驱动的‘活’架构” [[9]]。
3.2 🔗 双擎架构:iPaaS + aPaaS 的融合之力
领码 SPARK 的双引擎架构是实现平台“可集成”和“可交易”能力的关键。
-
iPaaS (集成平台即服务) 引擎 - 万物互联的“超级连接器”
iPaaS 引擎扮演着数据接入和系统集成的核心角色。它拥有一个丰富的、可市场化扩展的“多协议插件市场” [[10]]。- 功能:支持对主流数据库(MySQL, Oracle, PostgreSQL)、大数据平台(Hadoop, Hive)、API(REST/SOAP)、消息队列(Kafka, RabbitMQ)甚至工业协议(Modbus, OPC-UA)的图形化配置连接。
- 在交易中心的应用:数据提供方无需编写任何代码,只需在 Web 界面上拖拽相应的连接器组件,配置好地址和凭证,即可快速完成数据源的挂接,极大降低了数据入场的技术门槛,完美诠释了“可集成”能力。
-
aPaaS (应用平台即服务) 引擎 - 敏捷开发的“应用工厂”
aPaaS 引擎提供了一整套低代码/无代码的开发工具,让业务人员也能参与到应用的构建中。- 功能:包括可视化页面设计器、表单生成器、工作流引擎、报表工具等,可以将平台能力(如数据服务、AI模型)封装成可拖拽的组件 [[11]]。
- 在交易中心的应用:平台前端的“数据产品超市”、“用户个人中心”、“交易订单管理”等模块,均可通过 aPaaS 引擎快速搭建和迭代。这种模式不仅开发效率高,而且灵活性强,可以快速响应市场变化,调整交易界面和流程,是实现“可交易”前端场景的加速器。
3.3 🧬 元数据驱动:“活”架构的核心奥秘
“元数据驱动”是领码 SPARK 区别于传统平台的革命性特征,也是平台实现“可梳理”和“可治理”的基石 [[12]]。
- 理念:平台中的一切元素——数据源、API、页面、流程、规则、模型——都被定义为元数据。平台的行为不是由硬编码的程序逻辑决定的,而是由这些元数据动态驱动的。这被称为“元数据即代码”(Metadata as Code)。
- 实现“可梳理”:当一个新的数据源通过 iPaaS 接入时,平台会自动扫描并抽取其元数据(表结构、字段名、数据类型、注释等),并结合 AI 进行语义理解(如识别“XM”为“姓名”),自动生成数据字典,构建可视化的数据资产目录和数据血缘图谱。用户可以像逛图书馆一样,轻松查找和理解平台上的所有数据。
- 实现“可治理”:数据治理规则(如某字段必须脱敏、某类数据生命周期为30天)同样以元数据形式存储。当数据流经平台时,元数据驱动的治理引擎会自动加载并执行这些规则。修改治理策略,只需更新元数据,无需修改和重新部署代码,使治理体系具备了前所未有的灵活性和响应速度。
3.4 📦 容器化微服务:弹性、可靠与可扩展
平台整体采用基于 Kubernetes (K8s) 的容器化微服务架构,为交易中心提供电信级的稳定性和可扩展性 [[13]]。
- 弹性伸缩:交易高峰期(如城市级数据创新大赛),K8s 可根据实时负载自动增加定价、交易等服务的实例数量;交易平淡期则自动缩减,实现资源的最优利用。
- 高可用性:单个服务实例的故障不会影响整个平台,K8s 会自动重启或替换故障实例,保障交易业务 7x24 小时在线。
- 多租户隔离:为不同的数据提供方和大型使用方提供逻辑上甚至物理上的资源隔离,确保各自数据和应用的安全。
🧭 第四章:治理罗盘:DCMM模型的深度集成与实践
引入国家标准 DCMM(数据管理能力成熟度评估模型, GB/T 36073-2018)是本平台专业性的核心体现。我们并非简单地“对标”,而是将 DCMM 的精髓“内化”于平台的每一个技术环节,构建起自动化的评估与治理闭环。
4.1 ⚖️ DCMM模型概述:数据能力的“标尺”与“导航”
DCMM 将数据管理能力划分为数据战略、数据治理、数据架构、数据应用、数据安全、数据质量、数据标准、数据生命周期等8个核心能力域,并定义了从初始级到优化级的5个成熟度等级 [[14]][[15]][[16]]。它是衡量一个组织数据“管得好不好、用得怎么样”的权威标尺 [[17]][[18]]。
4.2 📋 “可梳理”:构建全景式数据资产目录
平台的“可梳理”能力,直接映射了 DCMM 的数据架构、数据标准和数据生命周期能力域的要求。
- 数据资产识别与编目:利用领码 SPARK 平台的元数据自动发现能力,对接入数据进行扫描,形成包含技术元数据、业务元数据、管理元数据的三位一体资产清单。
- 数据标准对齐:平台内置国家、行业及武汉市地方数据标准库。在梳理过程中,AI 算法会自动比对入库数据与标准库的差异,并给出标准化建议,引导数据提供方提升数据规范性,此举措响应了 DCMM 对数据标准管理的要求 [[19]]。
- 生命周期标识:为每一项数据资产打上生命周期标签(如新增、活跃、归档、销毁),并记录其完整的血缘关系,为后续的治理和交易奠定基础。
4.3 📊 “可评估”:DCMM驱动的数据质量与价值自动化评估
这是平台的核心创新之一,将 DCMM 的评估指标转化为可执行、可量化的自动化评估规则,实现了“可评估”能力。
实现路径:我们将 DCMM 中关于数据质量和数据安全的关键评估项,转化为平台的内置评估策略。
| DCMM评估项 (部分示例) | 平台自动化评估规则/指标 | 实现技术 |
|---|---|---|
| 数据质量 - 完整性 | 关键字段非空率、记录完整度 | SQL/Python 脚本,通过 iPaaS 在数据接入时触发 |
| 数据质量 - 准确性 | 值域范围校验、身份证/手机号格式校验 | 正则表达式规则引擎,结合外部权威库(如地址库)交叉验证 |
| 数据质量 - 一致性 | 跨表/跨系统关联字段一致性比率 | 基于数据血缘图谱的自动化比对算法 |
| 数据质量 - 时效性 | 数据更新频率、数据延迟时间 | 监控数据源的时间戳字段,计算与当前时间的差值 |
| 数据安全 - 分类分级 | 敏感数据(姓名、身份证、手机)自动识别率 | AI 自然语言处理(NLP)模型,识别敏感信息并打标 |
| 数据安全 - 脱敏合规 | 脱敏规则覆盖率、脱敏效果校验 | 平台内置脱敏算法(掩码、泛化、加密),检查数据处理流程是否调用 |
数据提供方的数据集在入场时,会自动触发这一系列评估流程,并生成一份多维度的“数据质量健康分”。这个分数不仅直观展示了数据质量,更成为后续 AI 定价的重要因子 [[20]]。
4.4 🛡️ “可治理”:将治理标准融入平台血脉
平台的“可治理”能力,是 DCMM 数据治理、数据安全和数据生命周期思想的工程化落地。
- 规则配置化:管理员可在平台的“治理中心”通过图形化界面配置治理规则。例如,“对于‘一级敏感’数据,访问必须经过双人审批,且使用记录需在区块链上存证”。这些规则以元数据形式存储 [[21]]。
- 治理自动化:领码 SPARK 的元数据驱动引擎在数据流转的每个环节(访问、查询、分析、交易)都会自动加载并执行相应的治理规则,实现“凡有流动,必有治理”。
- 全流程追溯:结合数据血缘和区块链技术,平台记录了数据从源头到消费的每一次操作、每一次转换、每一次授权。一旦发生数据安全事件,可秒级溯源,厘清责任。这完美契合了 DCMM 对数据追溯性的要求 [[22]]。
🧠 第五章:智能引擎:AI技术赋能数据价值全链条
如果说 DCMM 为平台构建了“骨架”,那么 AI 就是驱动平台高效运转的“大脑”和“神经网络”。
5.1 ✅ “可验证”:AI赋能的合规性与真实性智能核验
在数据交易中,信任是基石。“可验证”能力通过 AI 和其他技术的组合拳,为信任提供技术背书。
- 合规性智能扫描:在数据产品上架前,平台会启动 AI 内容审查引擎。该引擎基于大规模语言模型(LLM)和知识图谱,能够:
- 隐私合规检查:自动识别并警告数据集中未脱敏的个人信息,防止隐私泄露。
- 内容合规检查:扫描数据中是否包含法律法规禁止的敏感、非法内容。
- 数据真实性验证:
- AI生成内容检测:随着生成式 AI 的发展,利用 AI 伪造的数据集成为新的风险 [[23]]。平台集成了先进的 AIGC 检测模型,能够有效识别文本、图像等数据中的机器生成痕迹,确保数据来源的“原真性”。
- 异常模式识别:通过无监督学习算法(如孤立森林、自编码器)对数据分布进行建模,自动发现可能存在的数据造假、数据污染等异常模式。
- 权属与授权链验证:结合区块链技术,将数据的初始登记证书、每一次的授权协议、交易合同都记录在链上,形成一条清晰、不可篡改的“权利证据链”。用户在交易前可一键核验,确保交易的合法性。
5.2 💰 “可定价”:基于多维AI模型的动态价值发现
传统的数据定价方式已无法适应数据要素的复杂性。平台创新的“可定价”能力,引入了 AI 驱动的动态定价引擎 [[24]][[25]]。
工作机制:
- 基础价值评估:首先,利用回归模型 [[26]][[27]]综合 DCMM 质量分、数据规模、覆盖范围、更新频率等静态属性,给出一个基础价值参考。高质量的数据(高 DCMM 分)自然获得更高的基础价值。
- 市场动态调价:然后,强化学习模型 [[28]][[29]]扮演“智能交易员”的角色。它实时观测市场数据(如某类数据的查询次数、交易请求量、竞争产品的价格变动),通过不断的“尝试-反馈”学习(exploration-exploitation),动态调整价格,以实现卖家收益和市场成交率的平衡。例如,当流感季来临时,与“呼吸道疾病”相关的脱敏医疗数据需求上升,模型会自动提高其价格。
- 场景化智能报价:最后,平台还利用协同过滤等推荐算法,分析数据使用方的行业、历史行为和查询意图,为其推荐最合适的数据产品,并可能提供符合其支付能力的个性化、场景化报价 [[30]],促进交易达成。
5.3 🔭 “可监管”:AI驱动的风险洞察与智能预警
为保障市场的公平、公正和安全,“可监管”能力为监管部门提供了强有力的技术武器。
- 智能交易监控:AI 引擎 7x24 小时分析平台上的所有交易行为日志,利用图计算和异常检测算法,主动发现潜在的违规行为模式,例如:
- 合谋交易检测:识别多个账户在短时间内以异常价格进行关联交易,涉嫌刷单或利益输送。
- 数据滥用预警:检测某个用户在获得数据授权后,其使用行为(如查询频率、下载量)是否超出了智能合约约定的范围。
- 非法数据聚合风险:监控是否有用户试图通过购买多个看似无害的数据集,来拼接出完整的、能够再识别个人身份的敏感信息。
- 可解释AI (XAI) 与审计支持:当 AI 系统发出预警时,平台提供的可解释性工具(如 LIME、SHAP)能够向监管人员清晰地解释“为什么模型会认为这次交易是可疑的”,列出关键的决策因子 [[31]]。这大大提高了监管干预的精准度和效率。
- 穿透式监管驾驶舱:为监管部门提供一个宏观态势感知平台,实时展示数据交易热力图、价格指数波动、风险事件分布等关键指标,实现从宏观到微观的穿透式监管。
🛠️ 第六章:交易枢纽:核心功能模块与工作流设计
领码 SPARK 平台的 aPaaS 能力,使得我们可以高效地构建出支撑“八可”解决方案的丰富功能模块和流畅工作流。
6.1 🔢 平台功能矩阵
| 一级模块 | 二级功能/组件 | 核心价值体现 |
|---|---|---|
| 🏢 用户中心 | 身份认证、角色权限管理、企业/个人空间、账单管理 | 安全、个性化的用户服务 |
| 🛒 数据产品超市 | 数据产品搜索/浏览、产品详情页(含DCMM评级/AI定价)、数据预览、购物车 | 便捷、透明的数据发现与选择 |
| 🏛️ 数据治理中心 | 数据源管理、元数据目录、数据标准管理、数据质量任务、数据安全策略配置 | 可梳理、可治理、可评估 |
| 🤝 交易中心 | 订单创建与管理、智能合约模板库、多模式交易(API、沙箱、离线包)、支付结算接口 | 可交易、安全高效 |
| 🧠 AI服务中心 | AI定价引擎、合规验证服务、AIGC检测服务、数据价值模拟器 | 可验证、可定价、智能增值 |
| 🔐 安全与隐私计算 | 数据脱敏工具、联邦学习平台、多方安全计算(MPC)环境、数据水印服务 | 保障“数据可用不可见” |
| 📈 监管与运营中心 | 交易态势大屏、风险预警中心、审计日志查询、运营报表分析 | 可监管、市场洞察 |
6.2 ➡️ 数据知识产权“入场”流程:“可梳理”与“可治理”的落地
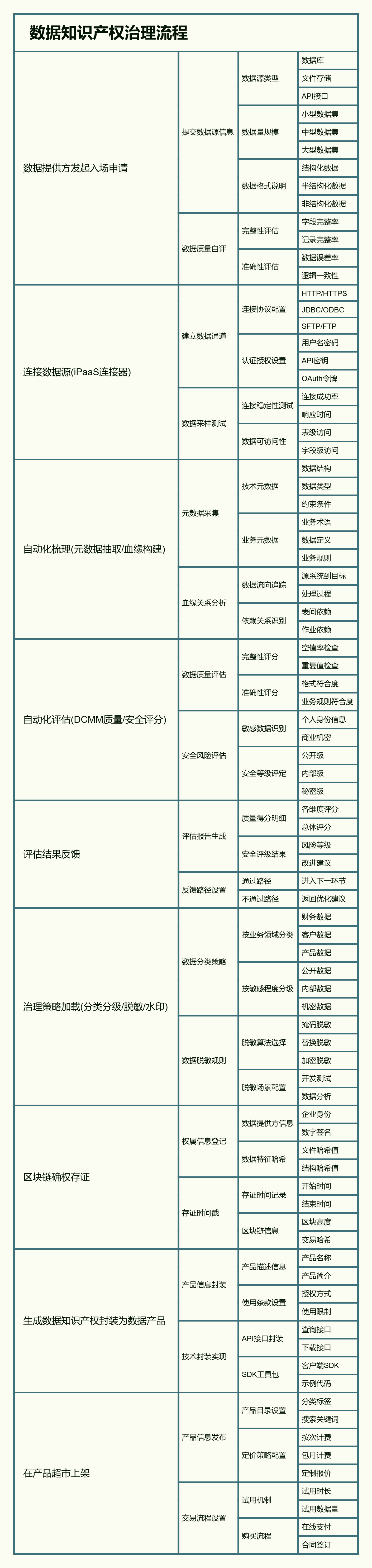
此流程将 DCMM 的评估标准前置,确保了只有合格、合规的数据才能进入交易市场,从源头上保障了数据质量。
6.3 🔄 数据知识产权“交易”流程:“可定价”与“可交易”的实现
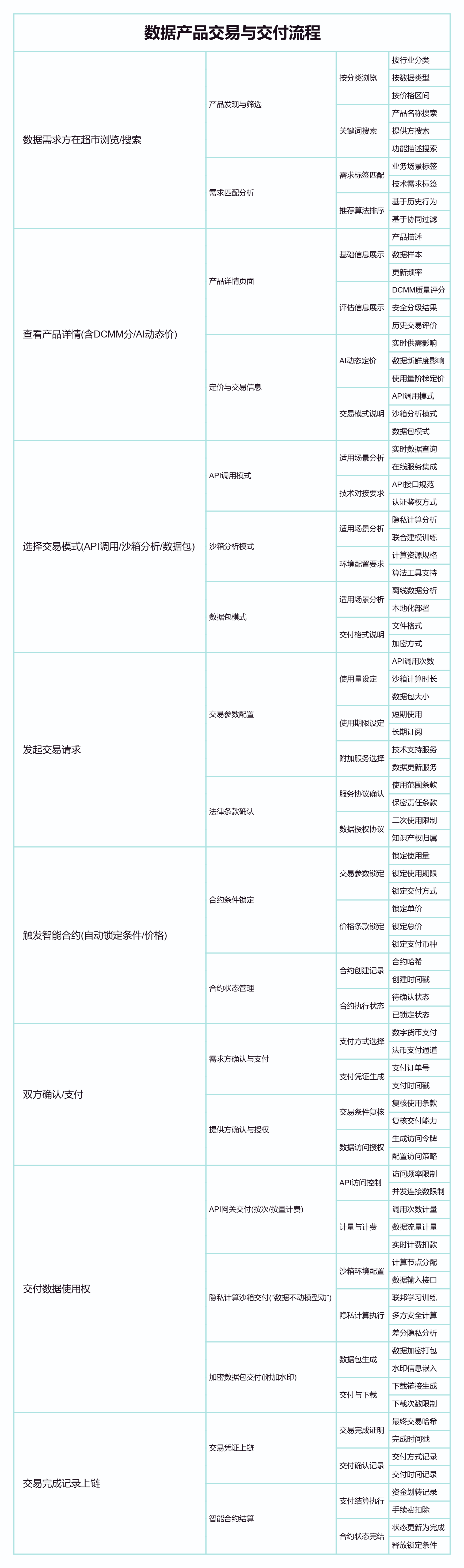
整个交易过程由智能合约驱动,极大减少了人工干预,提升了效率和透明度。多样化的交付方式满足了不同场景下的数据使用需求,同时兼顾了安全。
6.4 👁️ 数据知识产权“监管”流程:“可验证”与“可监管”的闭环
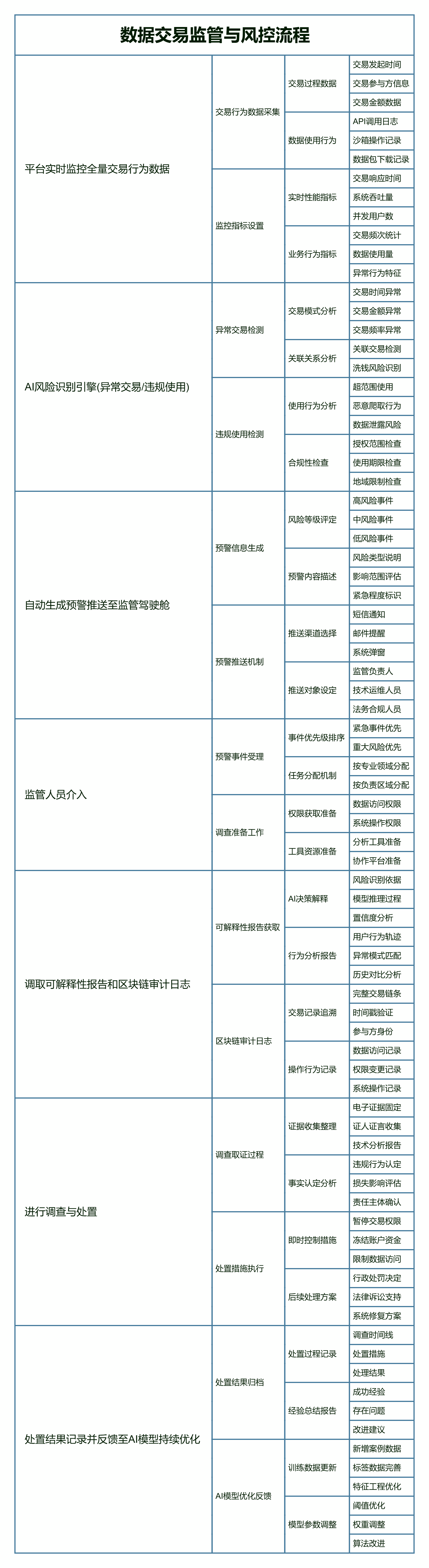
此闭环流程实现了从“被动响应”到“主动防御”的监管模式转变,AI 不仅是“裁判”,更是不断学习进化的“巡逻兵”。
🌌 第七章:未来展望:迈向数据要素的星辰大海
7.1 🤖 技术演进:从AI辅助到AI原生
当前平台已深度融合 AI,但未来我们将朝着“AI原生”演进。这意味着 AI 不再是外挂的功能模块,而是平台架构与生俱来的一部分。未来的交易中心将由一个“数据交易大模型”来统一调度,它能够理解复杂的交易意图,自动完成数据发现、组合、定价、签约和交付的全过程,实现真正的“智能体交易”(Agent-based Trading)。
7.2 🌍 生态构建:开放、共赢的开发者与伙伴生态
领码 SPARK 平台的低代码和能力开放特性,为生态构建提供了无限可能 [[32]]。我们将:
- 开放能力市场:允许第三方开发者在平台上开发和销售自己的数据处理组件、AI 模型、行业应用模板。
- 培育数据服务商:鼓励专业的第三方机构入驻,提供数据清洗、标注、合规咨询、价值评估等增值服务。
- 连接产业联盟:与武汉的光电子、汽车、生物医药等优势产业深度合作,共建行业数据空间,推动数据在产业链上下游的安全、高效流动。
7.3 🏙️ 价值延伸:赋能千行百业,驱动城市发展
武汉市数据知识产权交易中心平台的建成,其意义远不止于一个交易市场。它将成为:
- 城市数字经济的“发动机”:通过激活数据要素,降低全社会的创新成本,催生新业态、新模式。
- 产业智能化的“加速器”:为传统产业提供高质量的数据和 AI 能力,助其完成数字化、智能化转型升级。
- 现代城市治理的“智慧大脑”:在交通、医疗、环保等领域,通过跨部门、跨层级的数据融合应用,提升公共服务效率和科学决策水平。
结语
数据如星辰,散落夜空,唯有通过科学的规则、先进的技术和可信的平台将其连接,方能点亮数字时代的璀璨文明。武汉市数据知识产权交易中心平台,以领码 SPARK 为舟,以 DCMM 为舵,以 AI 为帆,正待扬帆起航,驶向数据要素价值最大化的星辰大海,为江城乃至中国的数字经济发展,书写下浓墨重彩的一笔。

这里是“一人公司”的成长家园。我们提供从产品曝光、技术变现到法律财税的全栈内容,并连接云服务、办公空间等稀缺资源,助你专注创造,无忧运营。
更多推荐



 18
18 0
0- 0



 已为社区贡献73条内容
已为社区贡献73条内容

所有评论(0)