基于dify的AI模型构建request_id查询工具
以下是关于 Dify工具 的详细介绍与安装指南,内容涵盖核心功能、应用场景及详细安装步骤,供参考:一、Dify工具介绍1. 工具定位Dify 是一款面向开发者的 AI应用开发平台,专注于简化大语言模型(如GPT、Claude等)的集成与应用开发流程,支持快速构建对话系统、知识库问答、自动化工作流等场景。2. 核心功能低代码开发:通过可视化界面配置AI流程,无需深入编码。多模型支持:兼容OpenAI
一 背景:
1.1 需要构建一套基于dify的唯一ID查询工具流程,希望可以通过更加简单的交互方式给到研发
大概要求就是:
1 输入要简单
2 直接输出链路信息和关键指标 尽量直观
1.2 Dify工具介绍和简单安装指南
以下是关于 Dify工具 的详细介绍与安装指南,内容涵盖核心功能、应用场景及详细安装步骤,供参考:
一、Dify工具介绍
1. 工具定位
Dify 是一款面向开发者的 AI应用开发平台,专注于简化大语言模型(如GPT、Claude等)的集成与应用开发流程,支持快速构建对话系统、知识库问答、自动化工作流等场景。2. 核心功能
低代码开发:通过可视化界面配置AI流程,无需深入编码。
多模型支持:兼容OpenAI、Anthropic、本地部署模型(如LLaMA)。
知识库增强:支持上传文档(PDF/TXT等),构建基于私有数据的问答系统。
API与插件扩展:提供API接口和自定义插件机制,便于二次开发。
3. 适用场景
企业级智能客服
个性化AI助手(如写作、编程辅助)
内部知识管理自动化
二、安装指南
1. 环境准备
系统要求:Linux/macOS(Windows需WSL或Docker)
依赖工具:Python 3.8+、Docker(可选)、Git
2. 安装方式
方式一:Docker快速部署(推荐)
Bash
复制
# 拉取镜像并启动
git clone https://github.com/langgenius/dify.git
cd dify/docker
docker-compose up -d
访问 http://localhost:80 完成初始化配置。
方式二:源码安装(适合定制化需求)
Bash
复制
# 克隆仓库
git clone https://github.com/langgenius/dify.git
cd dify
# 安装依赖
pip install -r requirements.txt
# 配置环境变量(修改.env文件)
cp .env.example .env # 按需填写API密钥等
# 启动服务
python manage.py runserver
3. 配置要点
模型接入:在后台设置中绑定OpenAI或本地模型API。
数据导入:通过“知识库”上传文档,训练专属AI模型。
权限管理:支持多用户协作与角色分配。
三、常见问题
端口冲突:修改docker-compose.yml 中的端口映射(如8080:80)。
模型性能:若使用本地模型,需确保显存≥16GB(如LLaMA-13B)。
数据安全:私有化部署时建议启用HTTPS和数据库加密。
四、参考资源
官方文档:Welcome to Dify | Dify
GitHub仓库:https://github.com/langgenius/dify
二 当前现状:
我们再上一篇文章讲解到 唯一DI的用法的使用场景
各种request_id唯一ID在不同场景的应用-CSDN博客
我们业务使用grafana查询工具来查询唯一ID 来查看各个状态的链路状态和关系
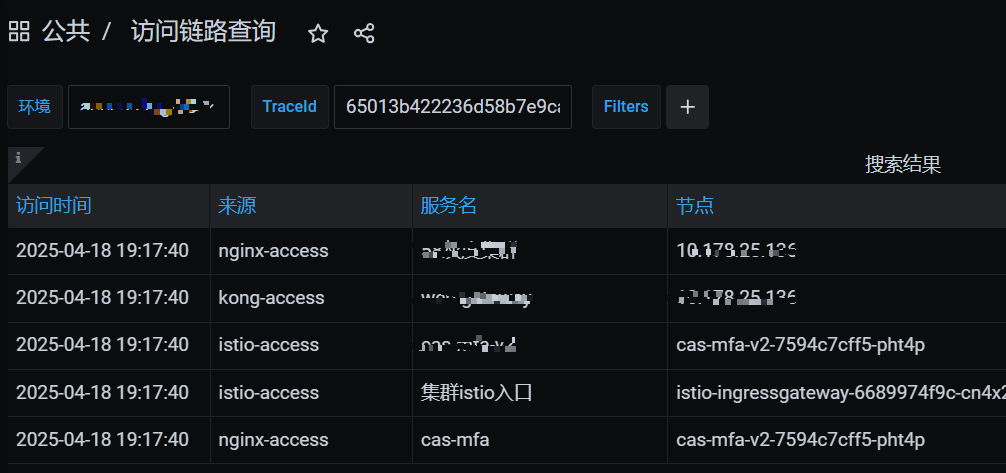
内部查询
grafana--通过查询唯一ID---ES 来返回查询结果
x_request_id:"$traceId" OR x-request-id:"$traceId" OR request-id:"$traceId" OR p-request-id:"$traceId"
改造思路:
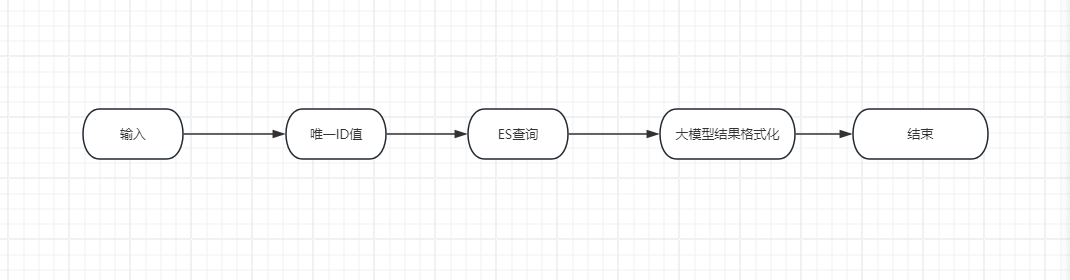
思路很清晰,但是过程还是有有一点问题。
三 正文
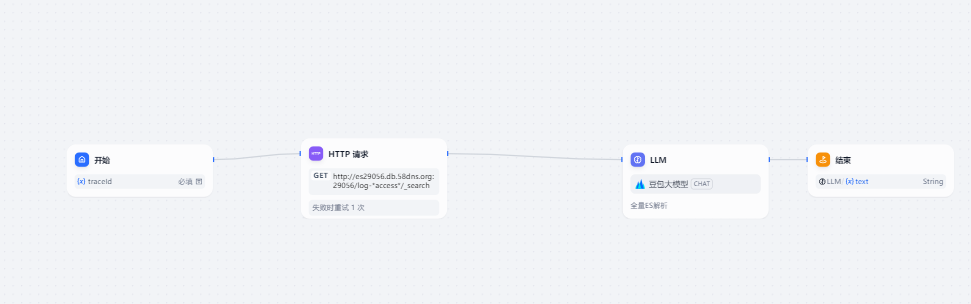
1 开始一个工作流
命名应用名称
2 选择HTTP模块
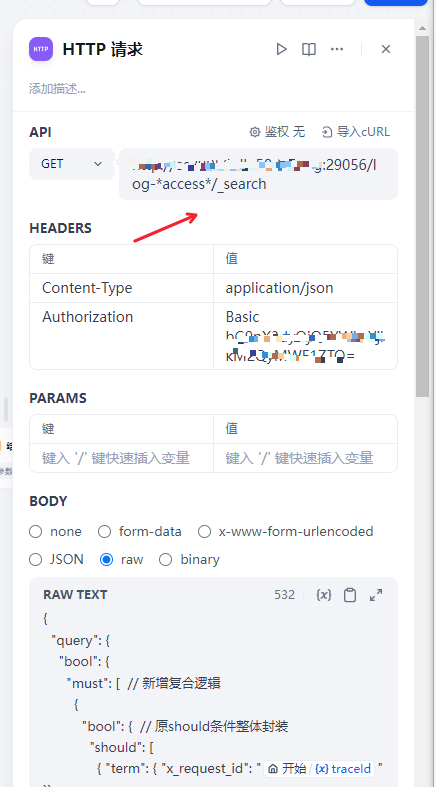
2.1 HTTP 模块重点
重点1:
1 API 我们写ES的地址 ES地址:索引名称/_search (索引名称可以*进行泛匹配)
重点2:
地版本ES 可能不需要 属于账号和密码
高版本: 由于dify提供的HTTPS模块 是不具备输入账号密码的。我们需要通过
例子: log:49ab03243423432 假设这是ES账号 log 密码:49ab03243423432
# 拼接用户名和密码,并通过管道编码为 Base64
echo -n "log:49ab03243423432" | base64
# 添加 "Basic " 前缀即可生成完整认证头
echo "Basic $(echo -n 'log:49ab03243423432' | base64)"
我们再HTTP 增加一个HEADERS 请求头:
Authorization: Basic AAAAAAAAAAAAAAAAA (BASE64后生成的)
重点3:ES的语法 (也可以通过AI工具自己生成需要的ES语法以及优化语法)
{
"query": {
"bool": {
"must": [ // 新增复合逻辑
{
"bool": { // 原should条件整体封装
"should": [
{ "term": { "x_request_id": "{{#1741337646259.traceId#}}" }},
{ "term": { "x-request-id": "{{#1741337646259.traceId#}}" }},
{ "term": { "request-id": "{{#1741337646259.traceId#}}" }},
{ "term": { "p-request-id": "{{#1741337646259.traceId#}}" }}
],
"minimum_should_match": 1
}
}
]
}
}
}
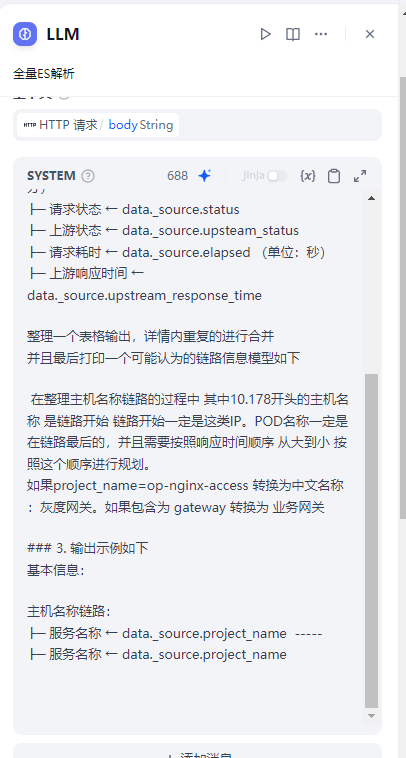
3 利用大模型再次处理JSON
我们键入相关大模型提示词
请根据
提供的JSON数据,按以下规则生成结构化# 结构化数据解析专家指令
**角色**:你是一位精通JSON数据清洗的专家,需要精准提取以下核心字段:
1. 解析路径指引
基本信息
├─ 主机名 ← data._source.host_name
├─ 服务名称 ← data._source.project_name
├─ 请求路径 ← data._source.request (提取路径部分)
├─ 请求状态 ← data._source.status
├─ 上游状态 ← data._source.upsteam_status
├─ 请求耗时 ← data._source.elapsed (单位:秒)
├─ 上游响应时间 ← data._source.upstream_response_time
整理一个表格输出,详情内重复的进行合并
并且最后打印一个可能认为的链路信息模型如下
在整理主机名称链路的过程中 其中{IP}开头的主机名称 是链路开始 链路开始一定是这类IP。POD名称一定是在链路最后的,并且需要按照响应时间顺序 从大到小 按照这个顺序进行规划。
### 3. 输出示例如下
基本信息:
主机名称链路:
├─ 服务名称 ← data._source.project_name -----
├─ 服务名称 ← data._source.project_name
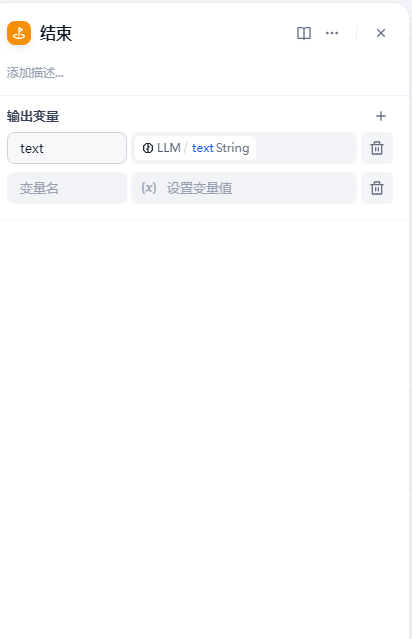
4 添加结果模块--结束
流程结束添加一个结束模块 用来把大模型处理后的结果进行返回
5 成品链路:
6 运行结果
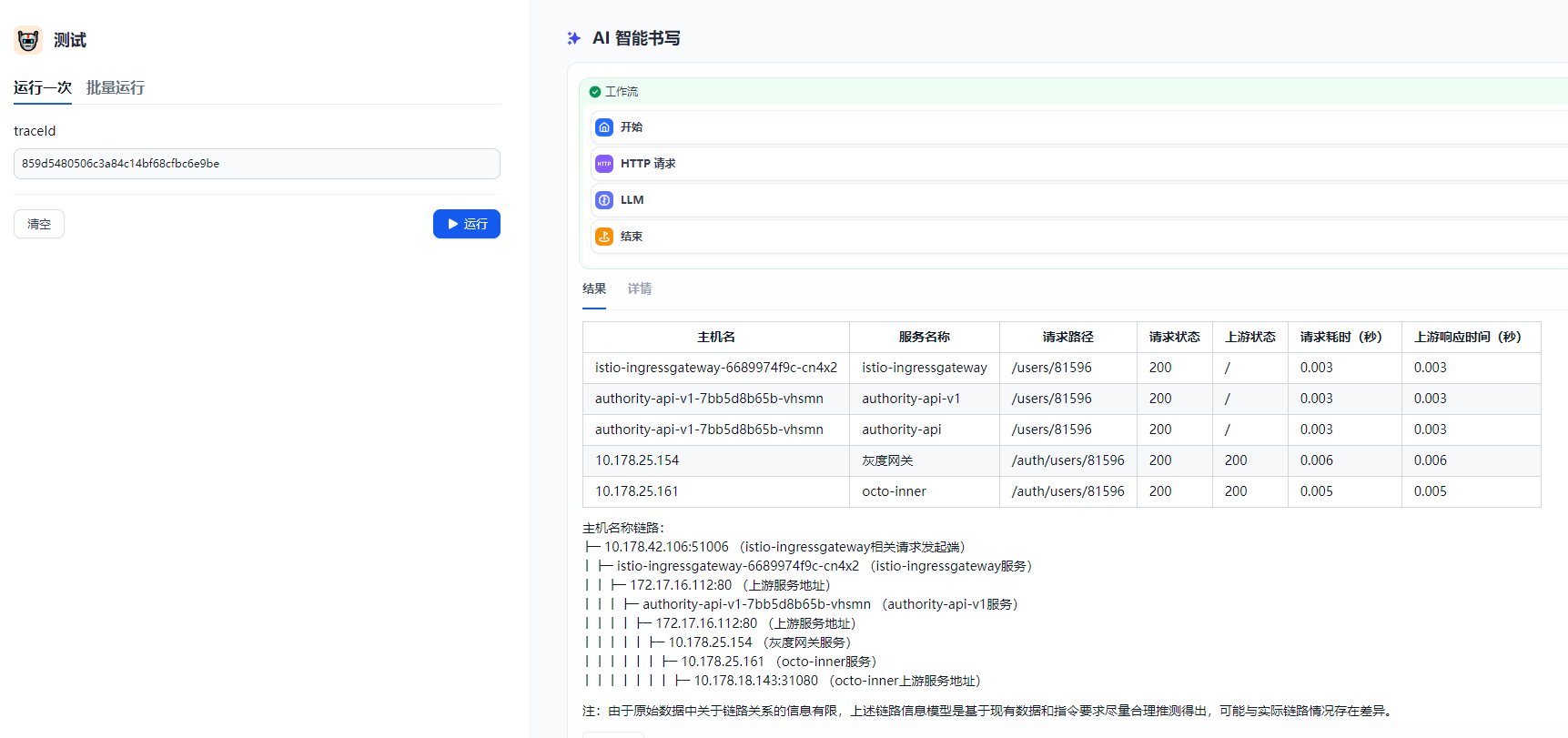
最后的输出链路 还可以通过优化提示词进一步优化链路的输出 更佳符合自己业务的链路流向
不必要的输出字段也可以去掉 尽量简化输出
尾声:
1 后续:整个流程我们按照线性处理的
其实在ES 和ES处理 我们是可以加条件分歧判断的。也可以不增加
2 我们也可以进一步优化 输入URL 通过工具留 打通代码库位置。让结果关联更多运维逻辑
给研发提供更多参考。

这里是“一人公司”的成长家园。我们提供从产品曝光、技术变现到法律财税的全栈内容,并连接云服务、办公空间等稀缺资源,助你专注创造,无忧运营。
更多推荐



 40
40 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)