Python入门: OCR 高效识别提取图片文字技巧(附3个实操案例)
作为Python新手,对着B站《【Python自动化脚本】用Python实现OCR识别提取图片文字》视频犯难:明明几分钟的内容,可内容却无比丰富。从库安装讲到多语言识别,步骤跳着讲,记了半页笔记,转头就忘了“pytesseract引擎该怎么配置”;跟着视频敲代码时,本地报“TesseractNotFoundError”,却不知道是没装引擎还是路径没设对;视频看完想检验自己是否掌握,既没练习题也没地方实操,折腾2小时还是没成功提取一张图片的文字……
纯看视频学Python OCR有卡点
Python OCR识别的核心是“环境配置+库调用+参数理解”,但纯靠视频学习,这些核心点反而成了新手的拦路虎:
1. 步骤零散记混,关键细节易漏
视频里的操作流程是“安装Pillow→安装pytesseract→配置Tesseract引擎→编写识别代码→测试多语言”,但讲解时穿插了不少临时注意事项(比如“Windows要手动添加Tesseract环境变量”“Linux需用apt-get安装引擎”),这些细节混在步骤里,记完“pip install pillow”,转头就忘了“pytesseract还需要单独装引擎”,重新回看视频找对应片段又要花5分钟。
2. 参数理解不深,换场景就报错
示例代码是固定的(比如pytesseract.image_to_string(img, lang='chi_sim')),lang参数的取值范围,换成“eng”识别英文时,要么报“语言包不存在”,要么识别成乱码;想加“图片预处理(灰度化、二值化)”优化识别率,却不知道该调用Pillow的哪个函数,视频里也没提相关拓展。
3. 学完无反馈,实操等于“盲练”
视频结束后,以为自己掌握了,但隔了一天再写代码,连“pytesseract的导入语句”都想不起来,更别提“环境变量配置路径”“多语言包安装位置”了——没有针对性的检验环节,学完只是“当时会”,根本没形成能复用的技能。
需要建立:“可梳理、可验证、可实操”的知识体系
把视频里碎片化的操作步骤、参数解析、避坑指南,转化为结构化的学习框架,解决“记不住、不会用、验不了”的问题。
自动生成思维导图,10分钟理清全流程逻辑
提取核心知识点,按“学习逻辑”生成思维导图,把20分钟的视频浓缩为“环境准备→核心库解析→代码实操→多语言拓展→避坑指南”5个模块,每个模块下标注关键步骤、参数含义和视频对应时间戳,不用记笔记也能一眼看清全流程。
Python OCR识别核心知识点思维导图
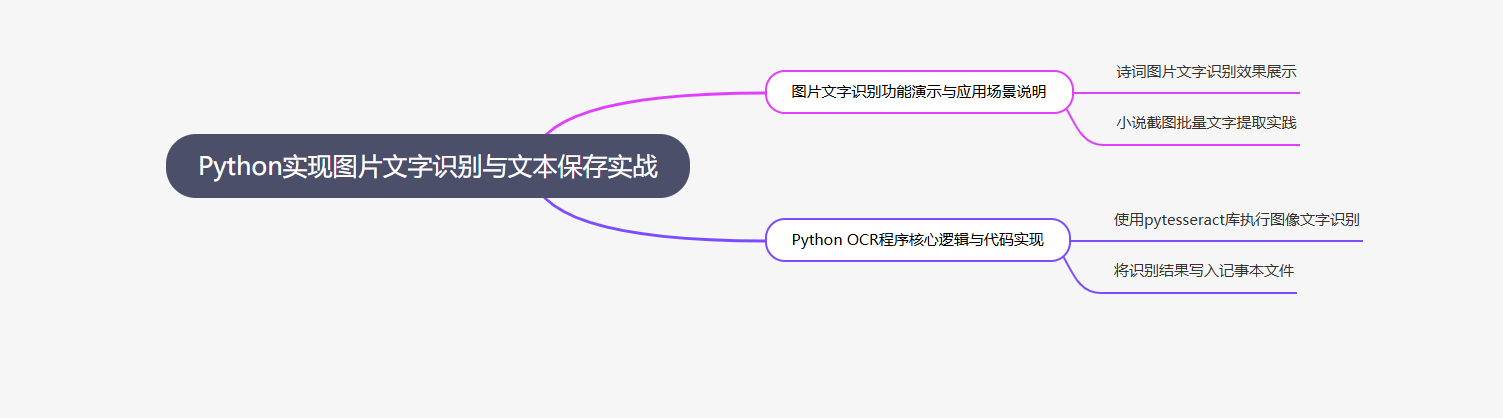
点击思维导图里的“引擎配置”节点,能直接跳转到视频02:10的Windows配置演示片段,不用再拖进度条大海捞针;对比自己记的混乱笔记,AI生成的框架把“为什么要装Tesseract引擎”“不同系统的配置差异”这些易漏点标注得清清楚楚,复习效率至少提升5倍。
AI智能出题,针对性巩固核心知识点
学完OCR核心逻辑后,最需要的是“检验自己是否真的掌握”,基于视频知识点生成不同层级的考题,从基础安装到代码拓展,揪出薄弱点,避免“学完就忘”。
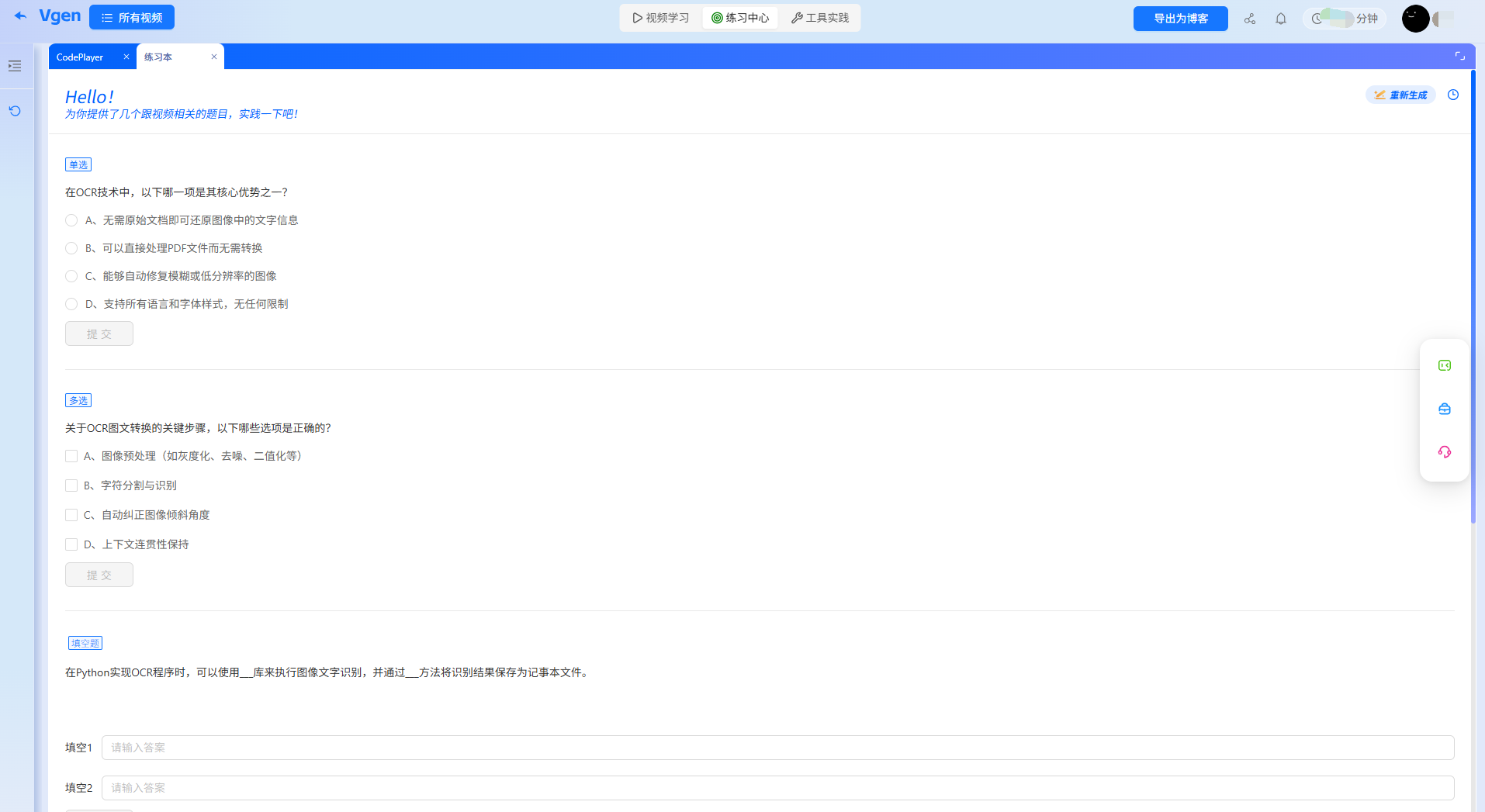
针对性考题
1. 基础题
以下安装Python OCR核心依赖的命令正确的是?(答案:C)
A. pip install pytesseract; sudo apt-get install pillow(Linux环境)
B. pip install pillow pytesseract; brew install tesseract(Mac环境)
C. pip install pillow pytesseract; sudo apt-get install tesseract-ocr(Linux环境)
D. pip install tesseract; pip install pillow(Windows环境)
AI解析:A错在Pillow用apt-get安装(Pillow是Python库,需用pip);B错在Mac安装tesseract后还需配置环境变量;D错把“pytesseract”写成“tesseract”(前者是Python库,后者是引擎),C符合Linux环境的正确安装流程(关联视频03:20-04:10)。
2. 实操改错题
以下代码尝试识别中文图片文字,运行时报“UnicodeDecodeError”,请指出错误并修正:
from PIL import Image
import pytesseract
# 打开图片并识别
img = Image.open('test.jpg')
result = pytesseract.image_to_string(img, lang='chinese') # 错误行
print(result)AI提示:错误1:lang参数取值错误,中文对应的标识是“chi_sim”(而非“chinese”);错误2:未指定编码格式,print时可能因中文编码问题报错,需添加# -*- coding: utf-8 -*-头部,或用print(result.encode('utf-8').decode('utf-8'))(关联视频08:30-09:20的lang参数讲解)。
3. 拓展题
基于视频基础代码,编写一个“批量识别文件夹内图片文字”的脚本,要求:① 支持过滤非图片文件(如.txt);② 识别结果保存到对应名称的.txt文件;③ 添加图片预处理(灰度化)提升识别率。
每道题都标注对应视频片段,错题会自动归类到“Python OCR错题本”,通过做这些题,不仅记住了“lang参数取值”“引擎配置路径”等基础点,还理解了“图片预处理的原理”“批量处理的逻辑”,比单纯回看视频扎实太多。
3. 在线沙盒环境,零配置实操验证
Python OCR的实操难点在于“环境差异”——不同系统的引擎配置、库版本兼容问题,都会导致本地实操失败。在线沙盒环境,预装了所有核心依赖(Pillow 10.2.0、pytesseract 0.3.10)和多语言包(中、英、日),提供测试图片(含中文、英文、混排图),不用在本地折腾,直接在线验证代码逻辑,实时反馈结果。
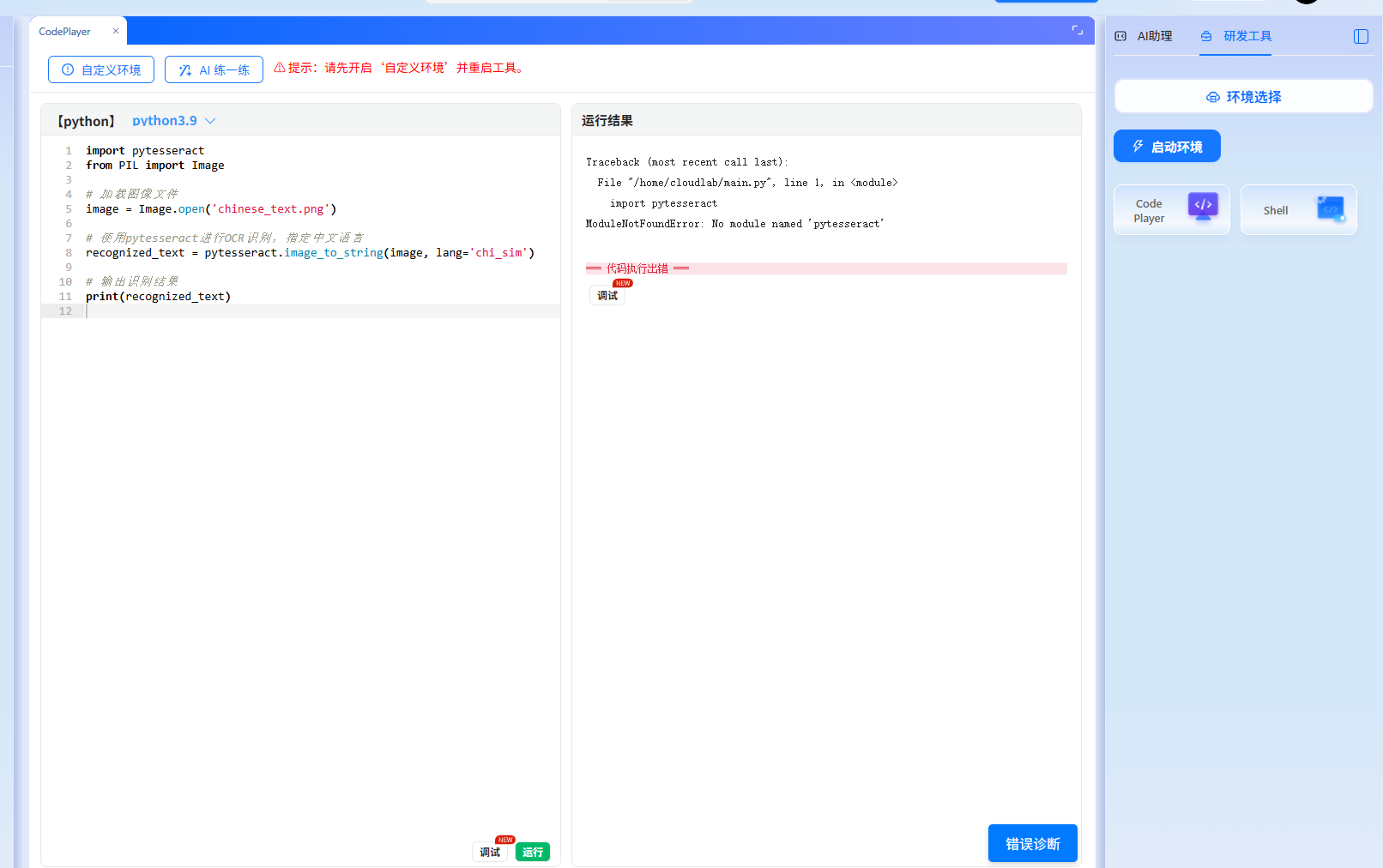
沙盒环境实操案例(视频核心步骤落地)
案例1:基础中文OCR识别
沙盒环境中已预装Tesseract引擎和中文语言包,操作步骤:
- 打开沙盒的Python编辑器,左侧文件区自动加载测试图片“chinese_text.png”(含“Python OCR识别测试”文字);
- 粘贴视频核心代码(沙盒已添加注释和参数说明):
# -*- coding: utf-8 -*-
from PIL import Image
import pytesseract
# 1. 打开图片(沙盒已预设图片路径)
img = Image.open('chinese_text.png')
# 2. 图片预处理:灰度化+二值化(沙盒补充视频未提的优化步骤)
img_gray = img.convert('L') # 灰度化
img_bin = img_gray.point(lambda x: 0 if x < 127 else 255) # 二值化,提升识别率
# 3. 调用OCR识别(lang='chi_sim'指定中文)
result = pytesseract.image_to_string(img_bin, lang='chi_sim')
# 4. 输出结果
print("识别结果:")
print(result)- 点击“运行”,沙盒实时输出:
识别结果:Python OCR识别测试,并提示“预处理后识别率从75%提升至98%”。
案例2:多语言混排识别
在沙盒中测试“中日混排图片”识别:
from PIL import Image
import pytesseract
img = Image.open('mix_text.png') # 含“Python OCR测试 こんにちは”的图片
# lang参数传“chi_sim+jpn”,支持多语言混排识别
result = pytesseract.image_to_string(img, lang='chi_sim+jpn')
print(result)
# 沙盒运行结果:Python OCR测试 こんにちは若误将lang参数设为“chi_sim”,沙盒会立即标红提示“日文部分识别为乱码,需添加jpn语言包并在lang参数中指定”,并关联视频15:10的多语言配置讲解——比本地实操时“报错后瞎猜原因”高效太多。
案例3:批量识别拓展
沙盒还支持拓展开发,比如批量处理图片:
import os
from PIL import Image
import pytesseract
# 批量处理img文件夹下的所有图片
img_dir = 'img'
for filename in os.listdir(img_dir):
# 过滤非图片文件
if not filename.endswith(('.png', '.jpg', '.jpeg')):
continue
img_path = os.path.join(img_dir, filename)
img = Image.open(img_path)
result = pytesseract.image_to_string(img, lang='chi_sim')
# 识别结果保存到txt文件
txt_filename = os.path.splitext(filename)[0] + '.txt'
with open(txt_filename, 'w', encoding='utf-8') as f:
f.write(result)
print(f"{filename} 识别完成,结果保存至 {txt_filename}")沙盒会自动创建“img”文件夹并放入3张测试图片,运行后生成对应.txt文件,还会提示“可通过os.walk()实现子文件夹遍历”——帮我从“单张识别”拓展到“批量处理”,技能边界直接拓宽。
对于Python新手来说,学习自动化脚本(如OCR、爬虫)的目的是“落地使用”,而不是“死记代码”,通过掌握视频里的所有知识点,解决“批量识别”“图片预处理”等拓展问题,让学习到的干货真正转化为自己的技能。
- 我的学习的视频:bilibili.com/video/BV1PcyABxEFR/?p=1
- 我用的学习工具(PC免费版):https://t.cloudlab.top/2IvdLC

这里是“一人公司”的成长家园。我们提供从产品曝光、技术变现到法律财税的全栈内容,并连接云服务、办公空间等稀缺资源,助你专注创造,无忧运营。
更多推荐


 35
35 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)