从部署到搭建:Dify 实战玩转私有化 AI 智能体
Dify是面向开发者的开源LLM应用开发平台,定位“生成式AI应用创新引擎”,以低代码/无代码提供模型集成、工作流编排到部署的全流程管理,降低企业级AI应用开发门槛。 开源LLM应用开发平台Dify(面向开发者),定位“生成式AI应用创新引擎”,凭低代码/无代码覆盖全流程管理,助力降低企业级AI应用开发门槛。 Dify是开发者友好的开源LLM应用平台,以“生成式AI应用创新引擎”为定位,通过低代码
什么是dify
- Dify是面向开发者的开源LLM应用开发平台,定位“生成式AI应用创新引擎”,以低代码/无代码提供模型集成、工作流编排到部署的全流程管理,降低企业级AI应用开发门槛。
- 开源LLM应用开发平台Dify(面向开发者),定位“生成式AI应用创新引擎”,凭低代码/无代码覆盖全流程管理,助力降低企业级AI应用开发门槛。
- Dify是开发者友好的开源LLM应用平台,以“生成式AI应用创新引擎”为定位,通过低代码/无代码打通全流程,降低企业级AI开发门槛。
dify 的核心特点
- • 提供拖拽式工作流编排(如 Prompt 设计、Agent 构建),支持非技术人员快速定义 AI 应用逻辑,无需深入底层代码179。
- • 内置 Prompt IDE,可调试提示词、对比模型性能,并集成文本转语音等扩展功能9。
- • 强大的模型兼容性
支持数百种主流模型(如 GPT-4、DeepSeek、Llama3、通义千问),兼容 OpenAI API 协议,可灵活切换云端或本地私有模型1610。 - • 通过 OneAPI 协议动态路由请求,优化模型调用成本610。
- • 企业级 RAG 引擎
支持长文档解析(PDF/PPT 等),结合向量数据库(如 Milvus)和混合检索(关键词+语义),提升知识库问答准确性178。 - • 支持引用溯源和人工干预,减少模型“幻觉
- • 灵活的 Agent 框架
基于 ReAct 策略(推理+行动),可调用 50+ 内置工具(如谷歌搜索、DALL·E),或自定义 API 扩展复杂任务处理能力79。 - • 全链路 LLMOps 支持
提供模型监控、日志分析、A/B 测试等功能,支持 Kubernetes 私有化部署,满足金融、医疗等高合规场景3710。
dify的版本
云版本:
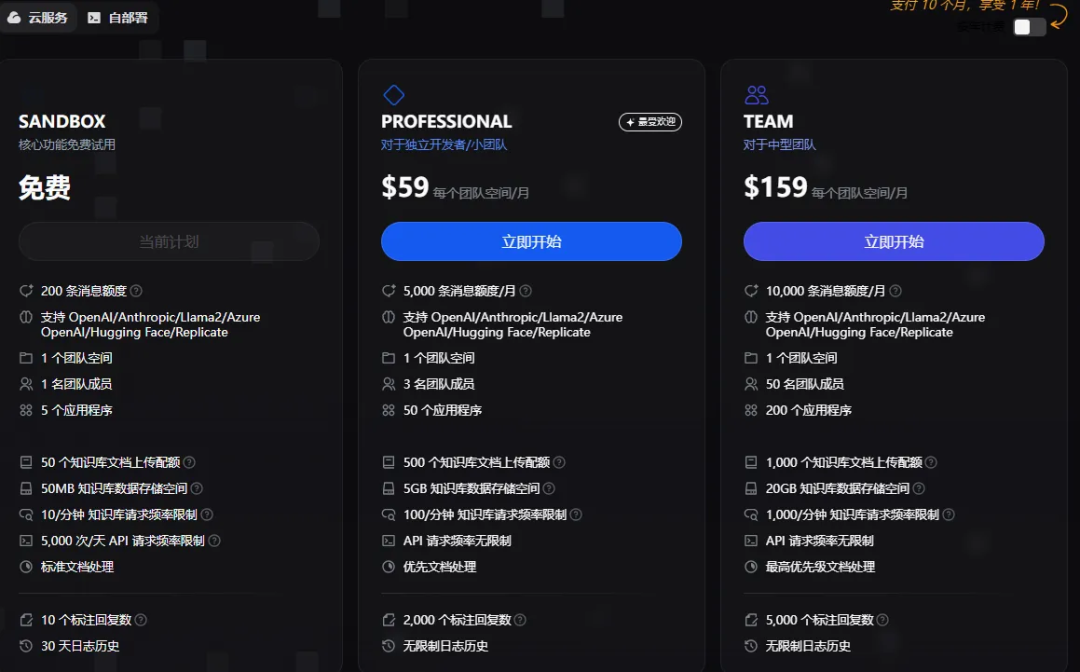
私有化部署版本:
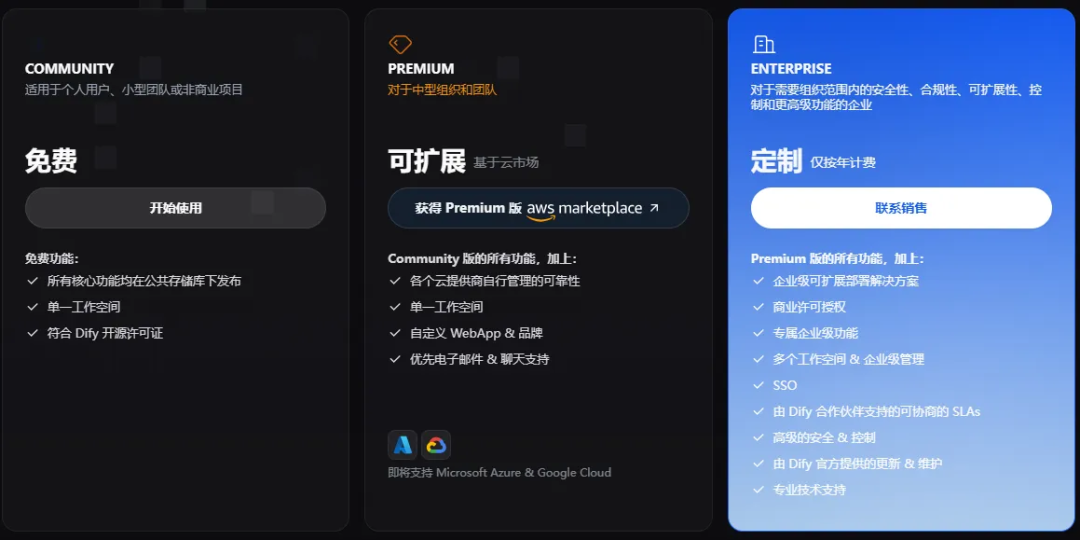
Dify vs Coze:核心优势对比
| 维度 | Dify | Coze |
|---|---|---|
| 定位 | 面向开发者/企业,支持复杂 AI 应用开发 | 面向普通用户,侧重快速搭建对话机器人 |
| 模型支持 | 多模型混合调用 + 私有化部署 | 主要依赖字节系模型(豆包),不支持自定义 |
| 知识库能力 | 长文本处理、RAG 优化、高精度检索 | 单文件仅支持 6000 Token,需手动分割 |
| 数据安全 | 全链路私有化部署,数据本地化 | 依赖云端服务,存在隐私风险 |
| 扩展性 | 自定义工具/代码节点,复杂工作流编排 | 模块简化,高级定制受限 |
| 适用场景 | 企业级应用(客服/BI/合规分析) | C 端场景(抖音/飞书聊天机器人) |
场景选型建议
- • 选 Dify:需复杂工作流(如合同分析 + 多模型调度)、数据隐私要求高、长期企业级应用。
- • 选 Coze:快速嵌入字节生态(抖音/飞书)、轻量级对话机器人开发、无代码需求。
dify的私有化部署
部署步骤
1、克隆dify社区版源码到本地
git
clone
https://github.com/langgenius/dify.git
2、进入 Dify 源代码的 Docker 目录
cd
dify/docker
复制环境配置文件
cp
.env.example .
env
# windows cmd
# copy .env.example .env
3、 启动源码中的docker-compose.yaml,此命令会自动拉取配置好的镜像并启动容器
docker compose up
注意:一开始不要使用docker compose up -d , 因为-d表示后台执行,如果pull镜像网络超时则会立刻中断,国内pull镜像不太稳定,经常中断,后面可以拉完镜像后,再次启动才加上-d参数后台运行
4、最后检查是否所有容器都正常运行:
docker compose ps
显示运行中的容器:

管理界面和配置
浏览器输入:http://localhost/install
打开配置界面,配置登录邮箱和账号名、密码后,登录后打开主界面:
后续输入http://localhost 打开主界面即可
大模型供应商配置:
打开右上角登录头像,点击“设置”,可以选择大模型供应商:
接入deepseek:
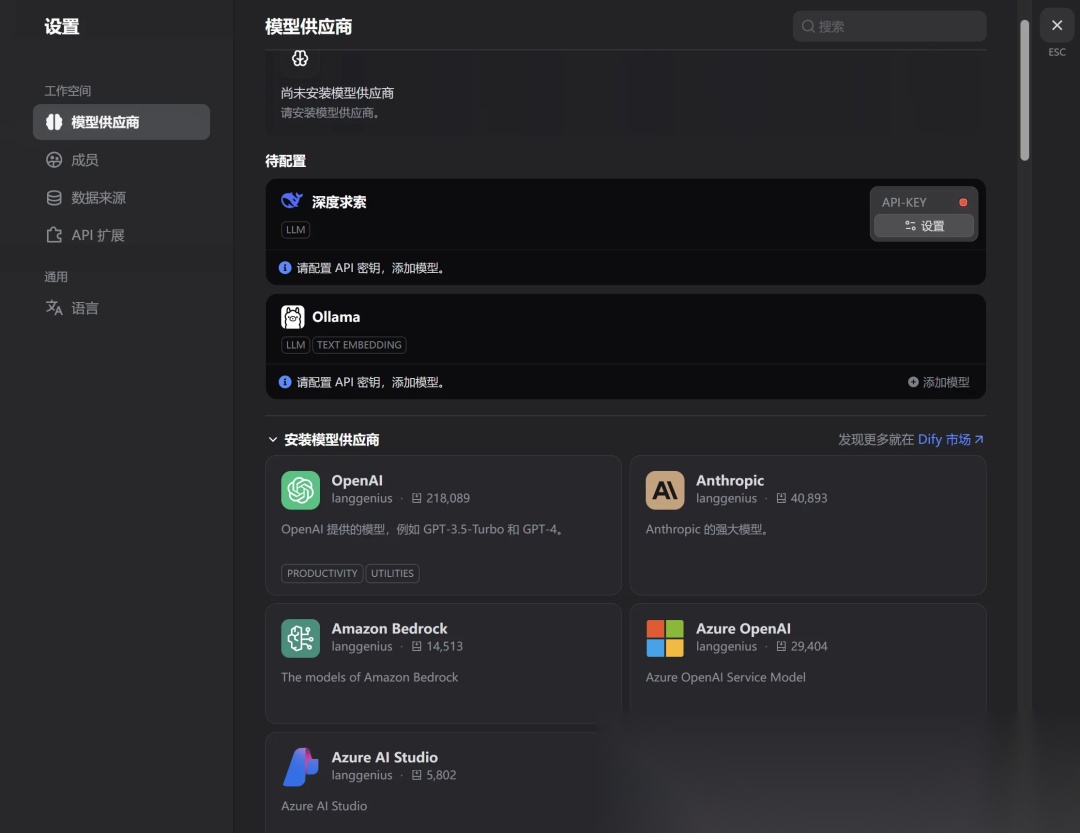
这里直接选择安装deepseek后,在配置列表设置deepseek 的api key,配置成功之后则可以在工作流节点中使用了
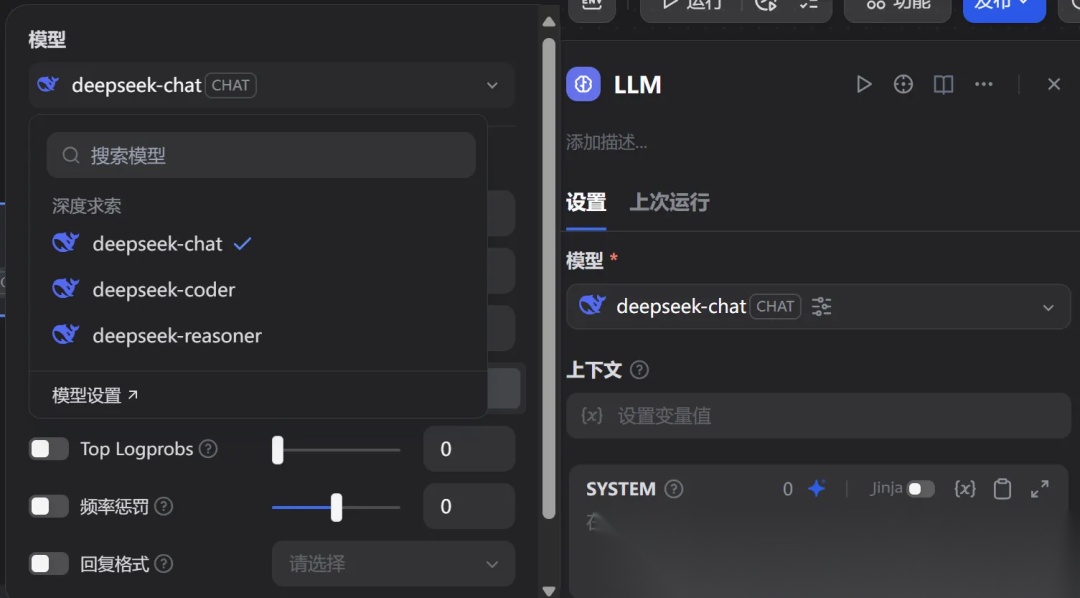
接入本地的Ollama模型:
这里主要配置了部署bge-3的embedding模型
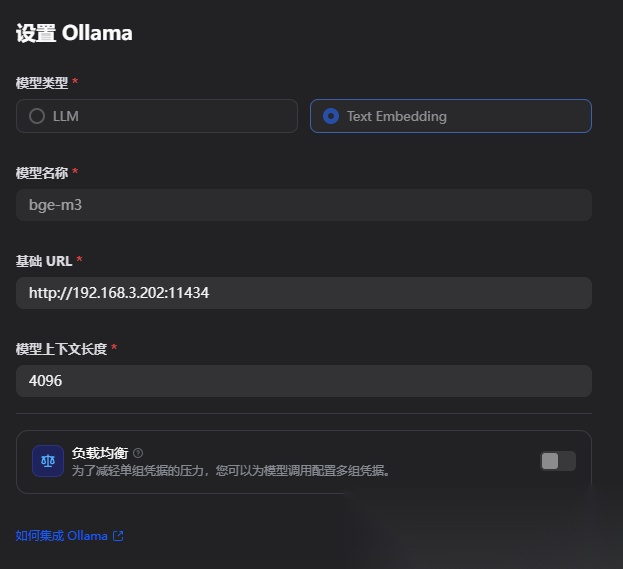
注意:配置本地Ollama的基础URL,ip不能是localhost,需要是本地的局域网ip,例如:http://192.168.3.202:11434,端口默认是11434,这是因为dify是docker启动的,localhost是容器内的地址了,不是本地宿主机的
搭建AI智能体
下面以OA行政小助手为例,搭建一个AI智能体,用于使用自然语文查询公司员工手册、用户信息以及公司部门信息等,支持RAG和工具调用
创建应用
创建空白应用,应用类型选择“Chatflow”, chatflow 基于工作流编排,适用于定义等复杂流程的多轮对话场景,具有记忆功能
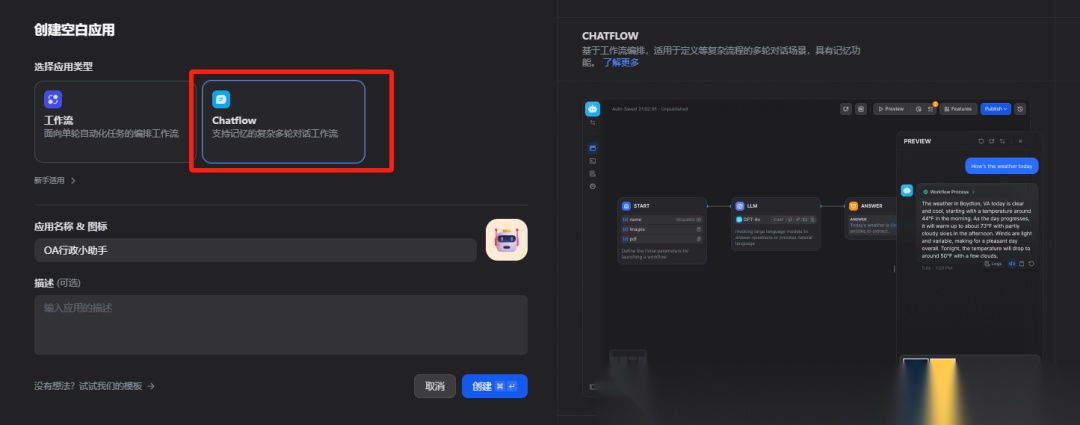
准备工作
创建知识库
导入到知识库的文本,这里将后面要检索的《员工手册》导入到知识库:
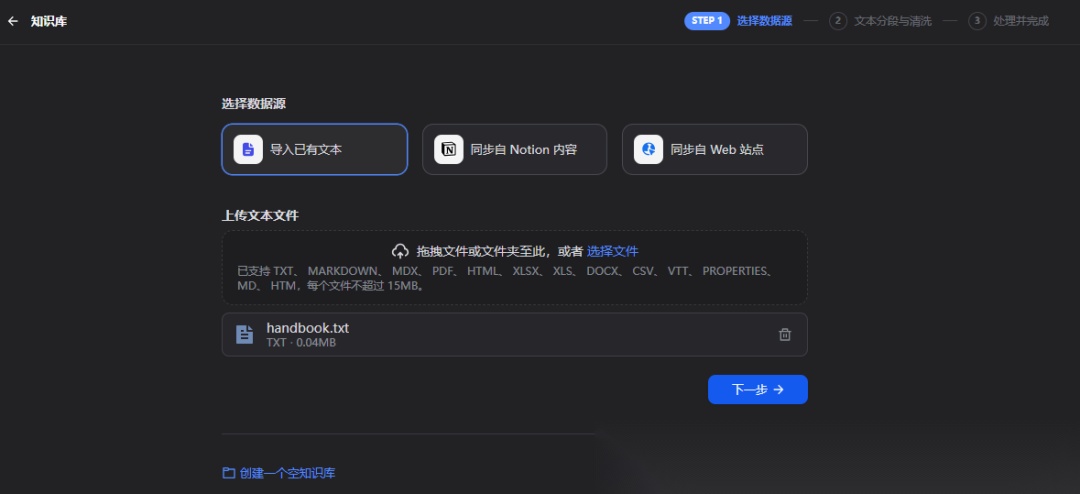
文本分段和清洗:
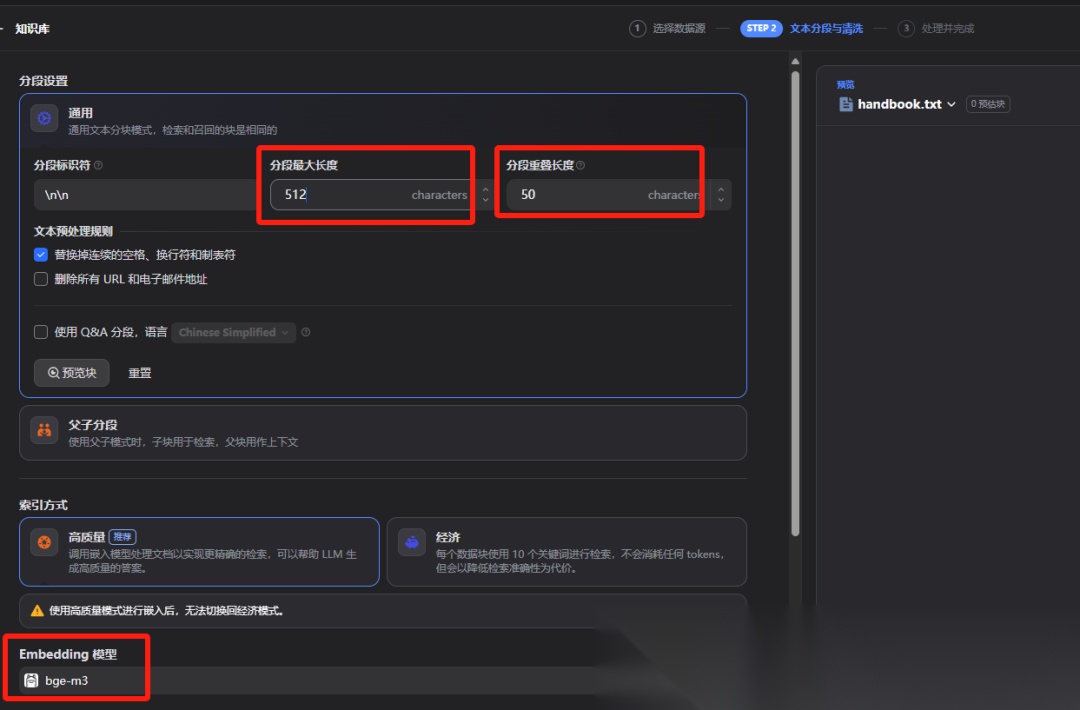
设置分段长度和重叠长度,embedding模型这里使用本地Ollama部署的bge-3模型
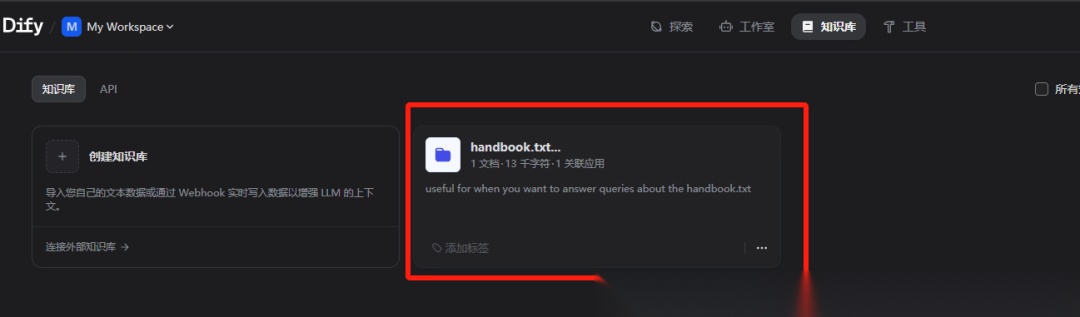
保存处理成功后,就可以在知识库看到新增的内容:
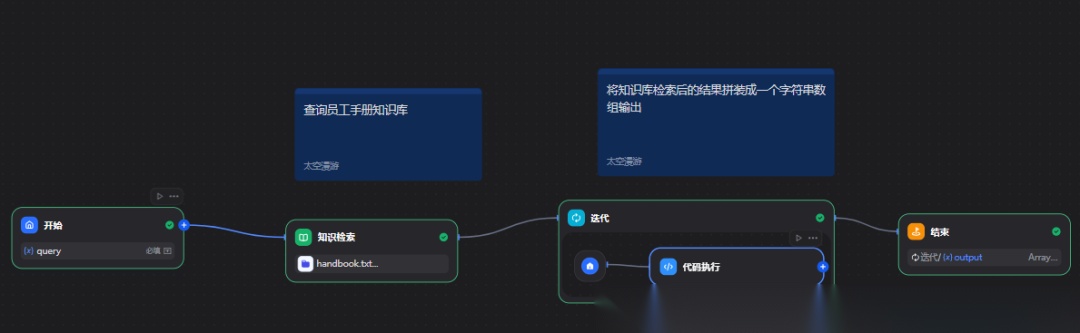
创建知识库查询工作流
工作流编排如下:
然后点击右上角发布-发布为工具,将此工作流发布为工具,在“工具”中就可以看到
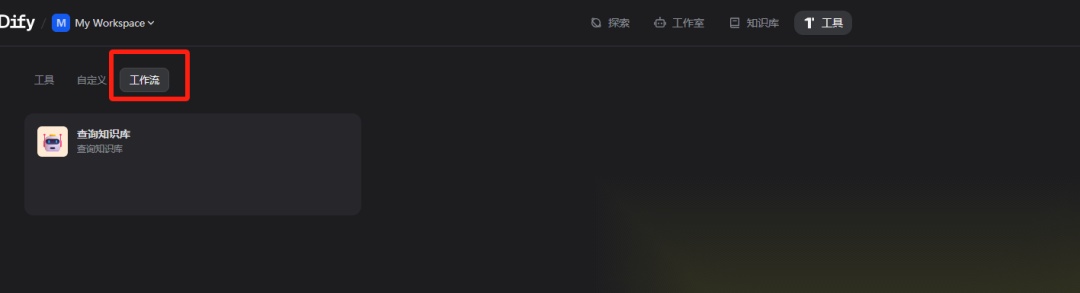
这个主要用于后面做为工具绑定到智能体的工具列表中,dify没有官方的检索知识库插件,故这里自己创建一个工作流来查询知识库,同时把这个工作流发布为插件后,就可以在智能体节点绑定成工具使用
安装数据库查询工具
右上角点击插件-安装插件-安装源-Marketplace, 搜索数据库查询,安装“数据库查询”工具
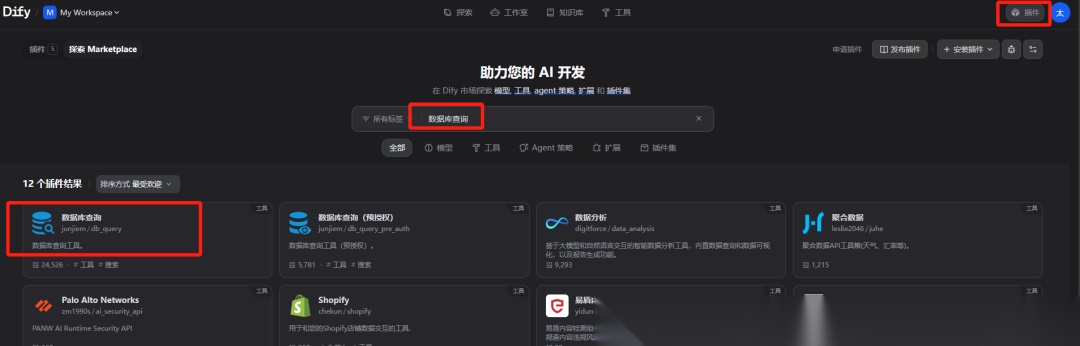
后面作为智能体查询指定的数据库查询工具
安装AGENT策略
这个AGENT策略需要在插件市场进行安装,右上角点击插件-安装插件-安装源-Marketplace, 搜索AGENT策略,安装“Dify Agent策略”
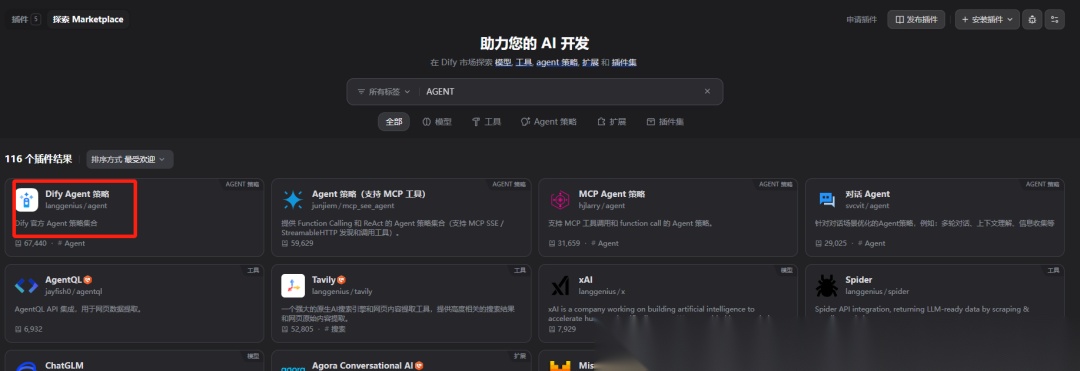
AGENT策略为后面创建智能体提供策略的处理支持
编排流程
编排如下:
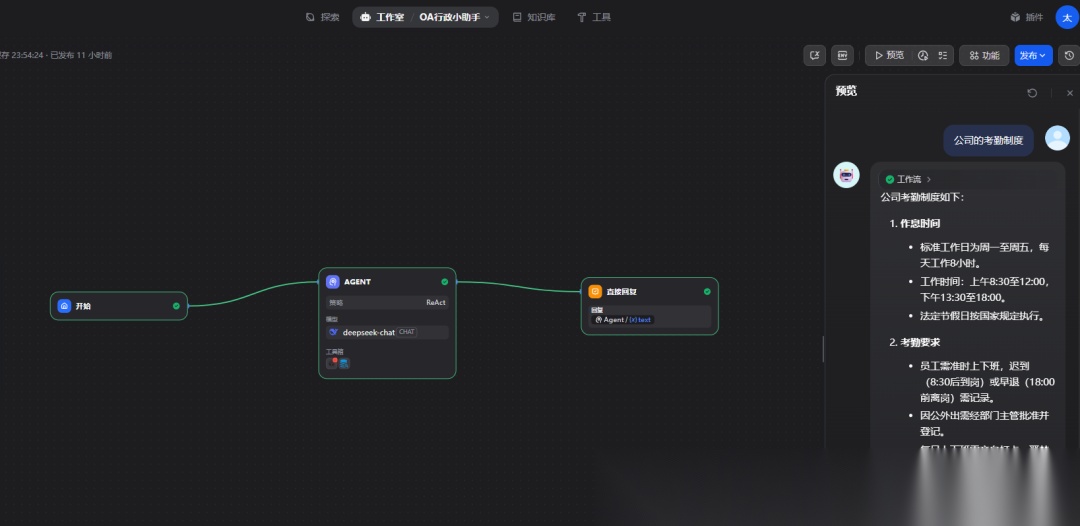
这里添加三个节点开始、AGENT、直接回复:
开始节点:
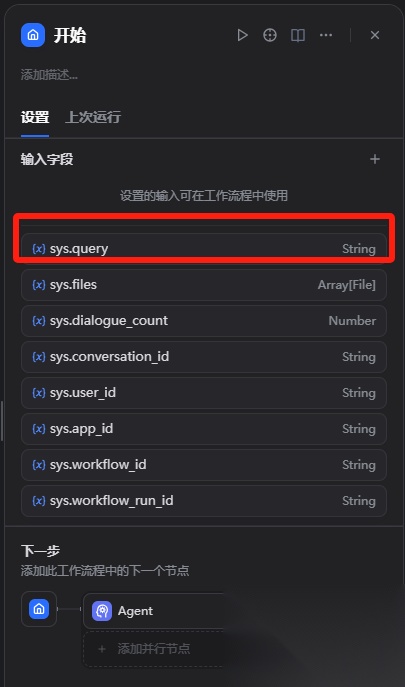
这里的sys.query字段为用户聊天的输入消息
AGENT节点:
主要的智能体处理节点:
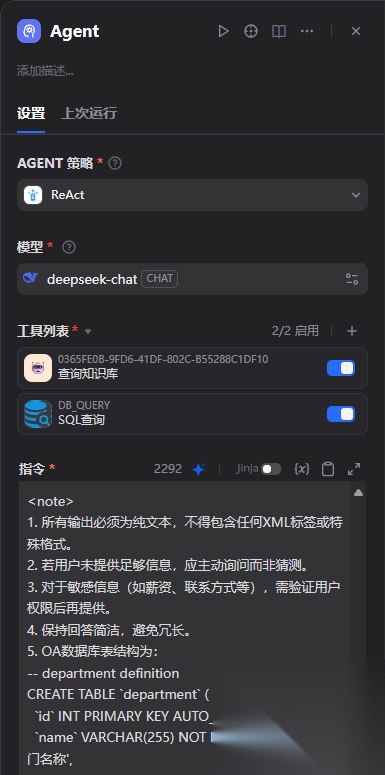
AGENT策略:
选择ReAct,支持多轮迭代调用工具处理,得出最佳的回复
工具列表:
1、查询知识库
2、SQL查询
这里绑定了前面准备好的两个工具
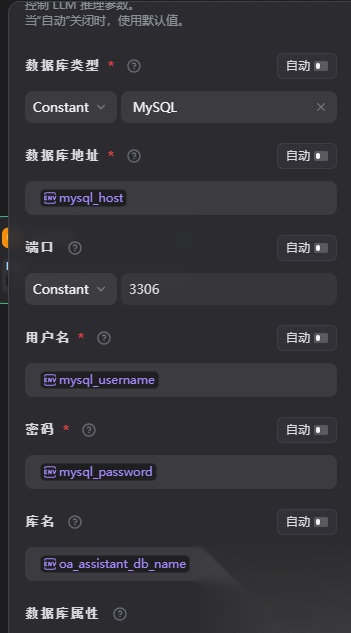
数据库工具这里可以配置的连接属性:
这里的属性值在dify环境变量已经配置好,直接选择就好
指令:
指令就是设定系统提示词:
<
instruction
>
你是一个OA小助手,专门用于查询公司员工手册、用户信息以及公司部门信息。请按照以下步骤处理用户的请求:
1. **明确查询类型**:首先确定用户需要查询的是员工手册、用户信息还是部门信息。如果是员工手册,直接返回相关章节或全文;如果是用户或部门信息,需确认查询的具体内容(如姓名、工号、部门名称等)。
2. **精准匹配数据**:根据用户提供的查询条件,从数据库中检索最匹配的结果。若用户提供的信息不完整,可请求进一步澄清。
3. **格式化输出**:将结果以清晰、简洁的文本形式返回,避免使用任何XML标签或其他标记语言。确保信息易于阅读和理解。
4. **处理模糊请求**:如果用户查询的内容不明确或存在多个可能的结果,列出所有可能的选项并提示用户进一步筛选。
5. **错误处理**:若未找到匹配结果,需明确告知用户并建议调整查询条件。
请始终以专业、友好的态度回应用户,确保信息的准确性和及时性。
</
instruction
>
<
examples
>
<
example
>
输入:查询员工手册中的请假政策
输出:员工手册中关于请假政策的规定如下:
1. 年假:员工每年享有15天带薪年假。
2. 病假:需提供医院证明,每年最多30天。
3. 事假:需提前申请,无薪。
更多详情请参考手册第5章第2节。
</
example
>
<
example
>
输入:查询张三的部门信息
输出:张三隶属于技术部,职位为高级软件工程师,工号为TECH2023。
</
example
>
<
example
>
输入:查询市场部的所有员工
输出:市场部现有员工如下:
1. 李四 - 市场经理
2. 王五 - 市场专员
3. 赵六 - 品牌策划
如需详细信息,请提供具体员工姓名。
</
example
>
</
examples
>
<
note
>
1. 所有输出必须为纯文本,不得包含任何XML标签或特殊格式。
2. 若用户未提供足够信息,应主动询问而非猜测。
3. 对于敏感信息(如薪资、联系方式等),需验证用户权限后再提供。
4. 保持回答简洁,避免冗长。
5. OA数据库表结构为:
-- department definition
CREATE TABLE `department` (
`id` INT PRIMARY KEY AUTO_INCREMENT,
`name` VARCHAR(255) NOT NULL COMMENT '部门名称',
`parent_id` INT COMMENT '上级部门ID',
`manager_id` INT COMMENT '部门负责人ID',
`create_time` DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`edit_time` DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间',
UNIQUE KEY `uniq_department_name` (`name`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='部门表';
-- employee definition
CREATE TABLE `employee` (
`id` INT PRIMARY KEY AUTO_INCREMENT,
`employee_no` VARCHAR(255) NOT NULL COMMENT '员工编号',
`name` VARCHAR(255) NOT NULL COMMENT '姓名',
`gender` TINYINT NOT NULL DEFAULT 0 COMMENT '0-未知 1-男 2-女',
`birth_date` DATE COMMENT '出生日期',
`phone` VARCHAR(50) NOT NULL COMMENT '联系电话',
`email` VARCHAR(255) NOT NULL COMMENT '电子邮箱',
`department_id` INT NOT NULL COMMENT '所属部门',
`position` VARCHAR(255) NOT NULL COMMENT '当前职位',
`entry_date` DATE NOT NULL COMMENT '入职日期',
`status` TINYINT NOT NULL DEFAULT 2 COMMENT '1-试用 2-在职 3-离职',
`create_time` DATETIME DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`edit_time` DATETIME DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间',
UNIQUE KEY `uniq_employee_no` (`employee_no`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='员工表';
</
note
>
提示词列出了OA数据库的表结构,帮助LLM理解跟组装查询SQL
直接回复节点:
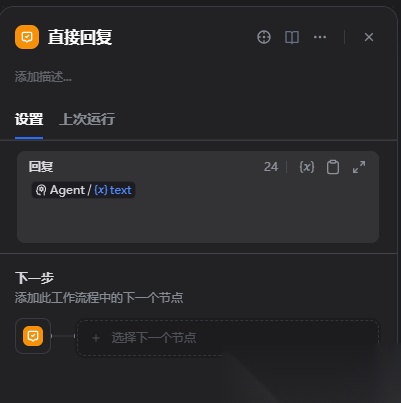
回复选择上个节点AGENT的输出结果text
预览
点击预览弹出预览聊天界面,输入聊天消息就可以和编排好的智能体聊天了
工具调用:
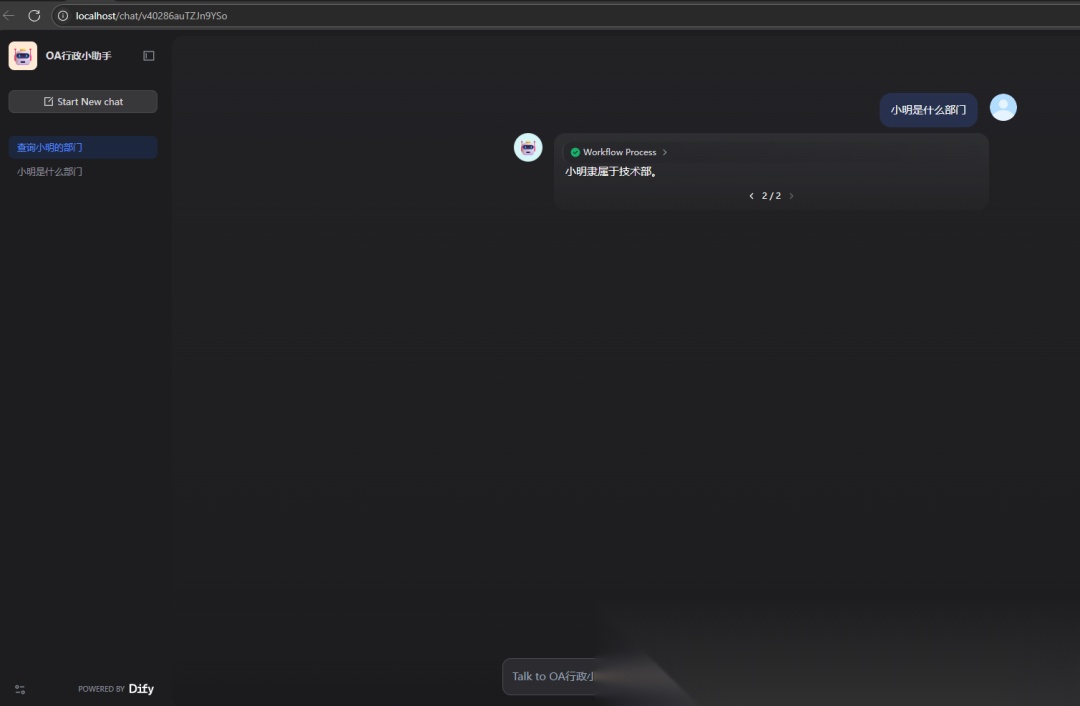
比如查询“小明的员工资料”:
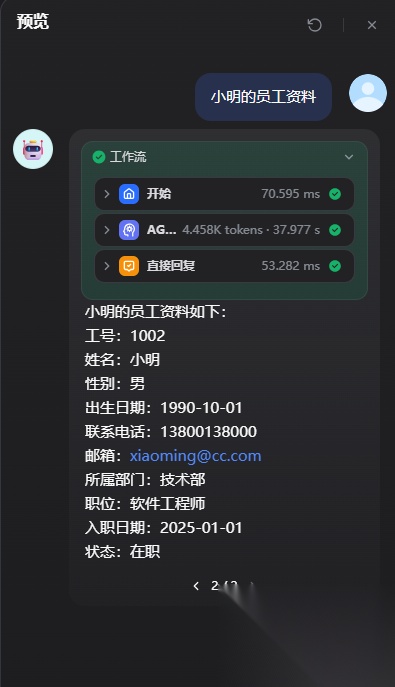
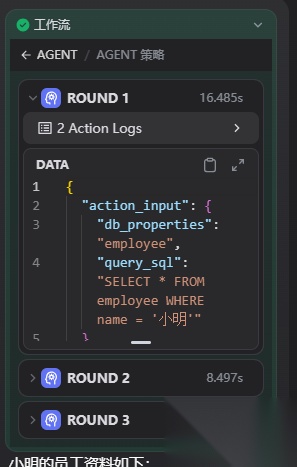
智能体会感知用户的查询意图,自动调用数据库查询工具查询小明的员工表和部门表,最终得出结果,这里可以看到这里经过三轮的步骤,round 1查询员工表,round 2 查询部门表,round 3 再由大模型总结输出最终的结果
知识库检索:
比如查询“公司的考勤制度”
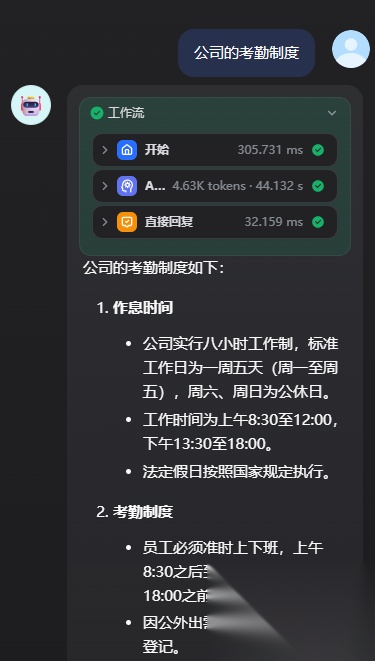
智能体会使用知识库查询工具,自动去检索知识库,然后总结出最终的输出
发布运行
可以将智能体聊天界面发布成web站点,方便外部进行访问
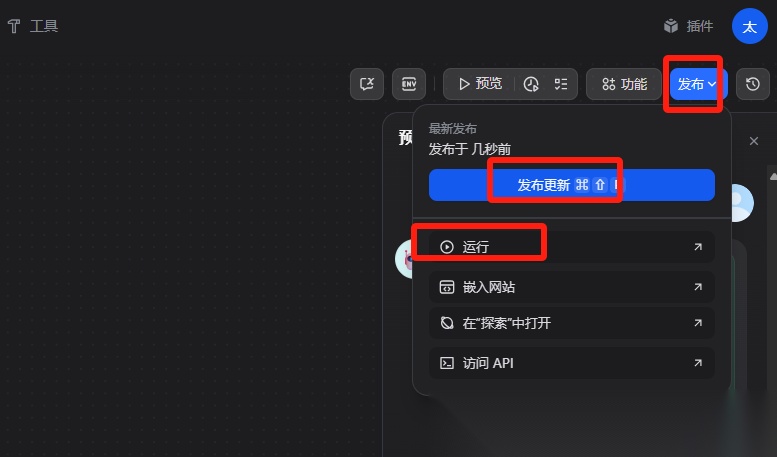
“发布更新”后,点击“运行”可以打开web站点:
预览
点击预览弹出预览聊天界面,输入聊天消息就可以和编排好的智能体聊天了
工具调用:
比如查询“小明的员工资料”:
[外链图片转存中…(img-0E87Wmrr-1756292728193)]
[外链图片转存中…(img-wHSiDpDS-1756292728193)]
智能体会感知用户的查询意图,自动调用数据库查询工具查询小明的员工表和部门表,最终得出结果,这里可以看到这里经过三轮的步骤,round 1查询员工表,round 2 查询部门表,round 3 再由大模型总结输出最终的结果
知识库检索:
比如查询“公司的考勤制度”
[外链图片转存中…(img-Usssec9L-1756292728193)]
智能体会使用知识库查询工具,自动去检索知识库,然后总结出最终的输出
发布运行
可以将智能体聊天界面发布成web站点,方便外部进行访问
[外链图片转存中…(img-nh9Dw5Op-1756292728193)]
“发布更新”后,点击“运行”可以打开web站点:
读者福利大放送:如果你对大模型感兴趣,想更加深入的学习大模型**,那么这份精心整理的大模型学习资料,绝对能帮你少走弯路、快速入门**
如果你是零基础小白,别担心——大模型入门真的没那么难,你完全可以学得会!
👉 不用你懂任何算法和数学知识,公式推导、复杂原理这些都不用操心;
👉 也不挑电脑配置,普通家用电脑完全能 hold 住,不用额外花钱升级设备;
👉 更不用你提前学 Python 之类的编程语言,零基础照样能上手。
你要做的特别简单:跟着我的讲解走,照着教程里的步骤一步步操作就行。
包括:大模型学习线路汇总、学习阶段,大模型实战案例,大模型学习视频,人工智能、机器学习、大模型书籍PDF。带你从零基础系统性的学好大模型!
现在这份资料免费分享给大家,有需要的小伙伴,直接VX扫描下方二维码就能领取啦😝↓↓↓
为什么要学习大模型?
数据显示,2023 年我国大模型相关人才缺口已突破百万,这一数字直接暴露了人才培养体系的严重滞后与供给不足。而随着人工智能技术的飞速迭代,产业对专业人才的需求将呈爆发式增长,据预测,到 2025 年这一缺口将急剧扩大至 400 万!!
大模型学习路线汇总
整体的学习路线分成L1到L4四个阶段,一步步带你从入门到进阶,从理论到实战,跟着学习路线一步步打卡,小白也能轻松学会!
大模型实战项目&配套源码
光学理论可不够,这套学习资料还包含了丰富的实战案例,让你在实战中检验成果巩固所学知识
大模型学习必看书籍PDF
我精选了一系列大模型技术的书籍和学习文档(电子版),它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。
大模型超全面试题汇总
在面试过程中可能遇到的问题,我都给大家汇总好了,能让你们在面试中游刃有余
这些资料真的有用吗?
这份资料由我和鲁为民博士(北京清华大学学士和美国加州理工学院博士)共同整理,现任上海殷泊信息科技CEO,其创立的MoPaaS云平台获Forrester全球’强劲表现者’认证,服务航天科工、国家电网等1000+企业,以第一作者在IEEE Transactions发表论文50+篇,获NASA JPL火星探测系统强化学习专利等35项中美专利。本套AI大模型课程由清华大学-加州理工双料博士、吴文俊人工智能奖得主鲁为民教授领衔研发。
资料内容涵盖了从入门到进阶的各类视频教程和实战项目,无论你是小白还是有些技术基础的技术人员,这份资料都绝对能帮助你提升薪资待遇,转行大模型岗位。
👉获取方式:
😝有需要的小伙伴,可以保存图片到VX扫描下方二维码免费领取【保证100%免费】
相信我,这套大模型系统教程将会是全网最齐全 最适合零基础的!!

这里是“一人公司”的成长家园。我们提供从产品曝光、技术变现到法律财税的全栈内容,并连接云服务、办公空间等稀缺资源,助你专注创造,无忧运营。
更多推荐



 22
22 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)